Explicit Multi-head Attention for Inter-head Interaction in Large Language Models
作者: Runyu Peng, Yunhua Zhou, Demin Song, Kai Lv, Bo Wang, Qipeng Guo, Xipeng Qiu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-27
💡 一句话要点
提出多头显式注意力机制MEA,增强大语言模型中头之间的交互
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多头注意力 显式交互 大语言模型 KV缓存压缩 模型优化 预训练 Transformer
📋 核心要点
- 现有Transformer模型中,头之间的交互对注意力机制的性能至关重要,但建模方式仍有提升空间。
- 提出多头显式注意力(MEA),通过头级别线性组合和组归一化,显式建模并增强头之间的信息交流。
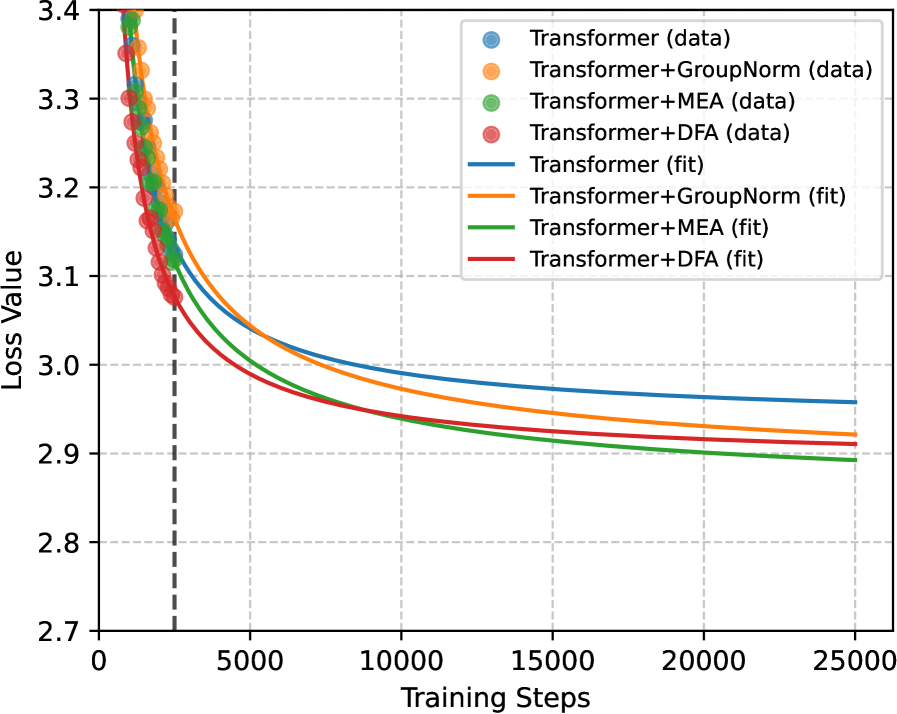
- 实验表明,MEA具有更强的预训练鲁棒性,并能有效压缩KV缓存,同时保持甚至提升模型性能。
📝 摘要(中文)
本文提出多头显式注意力(MEA),一种简单而有效的注意力变体,显式地建模跨头交互。MEA包含两个关键组件:头级别线性组合(HLC)模块,它对跨头的键和值向量分别应用可学习的线性组合,从而实现丰富的头间通信;以及头级别组归一化层,用于对齐重组后的头的统计特性。MEA在预训练中表现出强大的鲁棒性,允许使用更大的学习率,从而加快收敛速度,最终降低验证损失并提高各种任务的性能。此外,本文还探索了MEA的参数效率,通过减少注意力头的数量并利用HLC使用低秩“虚拟头”来重建它们。这实现了一种实用的键值缓存压缩策略,在知识密集型和科学推理任务上将KV缓存内存使用量减少50%,而性能损失可忽略不计,在奥林匹克级别的数学基准测试中仅下降3.59%的准确率。
🔬 方法详解
问题定义:现有Transformer模型中的多头注意力机制,头与头之间的交互方式较为隐式,可能限制了模型捕捉复杂关系的能力。此外,大语言模型推理时KV缓存占用大量内存,如何有效压缩KV缓存是一个重要问题。
核心思路:本文的核心思路是显式地建模多头注意力机制中头之间的交互。通过引入头级别线性组合(HLC)模块,允许每个头的信息与其他头的信息进行线性组合,从而增强头之间的信息交流。同时,利用HLC的低秩特性,实现KV缓存的压缩。
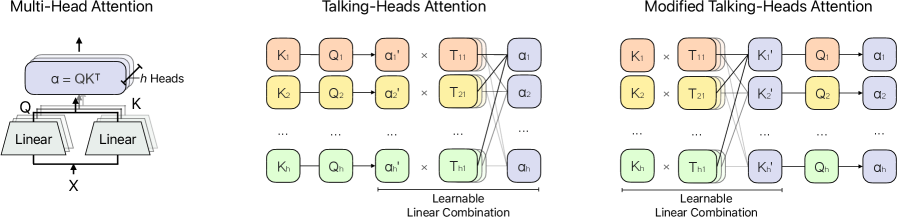
技术框架:MEA主要包含两个模块:HLC和头级别组归一化。HLC模块对Key和Value向量进行线性组合,实现跨头的交互。具体来说,对每个头的Key和Value向量,使用一个可学习的线性变换矩阵,将所有头的Key/Value向量进行加权组合。头级别组归一化用于对齐重组后的头的统计特性,稳定训练过程。
关键创新:MEA的关键创新在于显式地建模了多头注意力机制中头之间的交互。与传统的注意力机制相比,MEA允许每个头的信息与其他头的信息进行线性组合,从而增强了模型捕捉复杂关系的能力。此外,利用HLC的低秩特性,实现了KV缓存的压缩,降低了内存占用。
关键设计:HLC模块的关键设计在于使用可学习的线性变换矩阵对Key和Value向量进行加权组合。这些矩阵的参数是模型需要学习的。头级别组归一化的关键设计在于对重组后的头进行归一化,以稳定训练过程。在KV缓存压缩方面,通过减少注意力头的数量,并利用HLC使用低秩“虚拟头”来重建它们,从而减少KV缓存的存储空间。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MEA在预训练中表现出强大的鲁棒性,允许使用更大的学习率,从而加快收敛速度,降低验证损失。在知识密集型和科学推理任务上,MEA的KV缓存压缩策略可以将KV缓存内存使用量减少50%,而性能损失可忽略不计。在奥林匹克级别的数学基准测试中,准确率仅下降3.59%。
🎯 应用场景
MEA具有广泛的应用前景,可应用于各种基于Transformer的大语言模型中,提升模型性能和效率。尤其在资源受限的场景下,MEA的KV缓存压缩能力可以有效降低内存占用,使其能够部署在移动设备或边缘设备上。此外,MEA的预训练鲁棒性使其能够使用更大的学习率,加快模型训练速度。
📄 摘要(原文)
In large language models built upon the Transformer architecture, recent studies have shown that inter-head interaction can enhance attention performance. Motivated by this, we propose Multi-head Explicit Attention (MEA), a simple yet effective attention variant that explicitly models cross-head interaction. MEA consists of two key components: a Head-level Linear Composition (HLC) module that separately applies learnable linear combinations to the key and value vectors across heads, thereby enabling rich inter-head communication; and a head-level Group Normalization layer that aligns the statistical properties of the recombined heads. MEA shows strong robustness in pretraining, which allows the use of larger learning rates that lead to faster convergence, ultimately resulting in lower validation loss and improved performance across a range of tasks. Furthermore, we explore the parameter efficiency of MEA by reducing the number of attention heads and leveraging HLC to reconstruct them using low-rank "virtual heads". This enables a practical key-value cache compression strategy that reduces KV-cache memory usage by 50% with negligible performance loss on knowledge-intensive and scientific reasoning tasks, and only a 3.59% accuracy drop for Olympiad-level mathematical benchmarks.