Selective Steering: Norm-Preserving Control Through Discriminative Layer Selection
作者: Quy-Anh Dang, Chris Ngo
分类: cs.LG, cs.AI
发布日期: 2026-01-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出选择性引导,通过判别层选择实现LLM中保持范数的对抗控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 激活引导 范数保持 判别层选择
📋 核心要点
- 现有激活引导方法在对抗攻击中存在系数调整困难和范数敏感问题,导致分布偏移和生成崩溃。
- 选择性引导通过范数保持旋转公式和判别层选择,确保激活分布完整性,并仅在必要时进行干预。
- 实验表明,选择性引导在提高攻击成功率的同时,保持了模型的性能和稳定性,优于现有方法。
📝 摘要(中文)
尽管在对齐方面取得了显著进展,大型语言模型(LLM)仍然容易受到引发有害行为的对抗攻击。激活引导技术提供了一种有前景的推理时干预方法,但现有方法存在关键限制:激活添加需要仔细的系数调整,并且对特定层的范数变化敏感,而定向消融仅提供二元控制。最近关于角度引导的工作通过2D子空间中的旋转引入了连续控制,但其在实际应用中违反了范数保持,导致分布偏移和生成崩溃,尤其是在参数低于7B的模型中。我们提出了选择性引导,通过两个关键创新解决了这些限制:(1)一种数学上严格的范数保持旋转公式,可保持激活分布的完整性,以及(2)判别层选择,仅在特征表示表现出异号类对齐时才应用引导。在九个模型上的实验表明,选择性引导实现了比先前方法高5.5倍的攻击成功率,同时保持零困惑度违规,并在标准基准上保持约100%的能力保留。我们的方法为可控且稳定的LLM行为修改提供了一个原则性、高效的框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对对抗攻击时,容易产生有害行为的问题。现有的激活引导方法,如激活添加和定向消融,存在系数调整困难、对层间范数变化敏感、控制粒度粗糙等问题,导致模型性能下降和生成内容不稳定。特别是Angular Steering方法,虽然尝试通过旋转进行连续控制,但违反了范数保持,导致分布偏移和生成崩溃。
核心思路:论文的核心思路是通过一种范数保持的旋转方法,以及一种判别性的层选择机制,来实现对LLM行为的精确控制,同时避免对模型性能产生负面影响。核心在于只在那些能够有效引导模型行为的层上进行干预,并且保证干预操作不会破坏激活分布的整体结构。
技术框架:Selective Steering 包含两个主要模块:(1) 范数保持旋转模块:该模块使用一种数学上严格的旋转公式,确保在激活空间中进行旋转时,激活向量的范数保持不变,从而避免分布偏移。 (2) 判别层选择模块:该模块分析每一层的特征表示,选择那些特征表示与目标类别对齐方向相反的层进行引导。整体流程是,首先通过判别层选择模块确定需要进行引导的层,然后使用范数保持旋转模块对这些层的激活进行旋转,从而实现对模型行为的控制。
关键创新:论文的关键创新在于两个方面:(1) 提出了一个数学上严格的范数保持旋转公式,解决了现有方法中存在的分布偏移问题。与Angular Steering等方法不同,该公式保证了旋转操作不会改变激活向量的范数,从而保持了激活分布的完整性。(2) 提出了一个判别层选择机制,该机制能够自动选择那些能够有效引导模型行为的层进行干预,避免了对所有层进行盲目干预,提高了引导效率和模型稳定性。
关键设计:在范数保持旋转模块中,具体的旋转公式需要根据激活向量的维度和旋转角度进行设计,以确保旋转操作的范数保持特性。在判别层选择模块中,需要定义一个合适的指标来衡量特征表示与目标类别的对齐程度,例如可以使用余弦相似度或内积。此外,还需要设置一个阈值来决定哪些层需要进行引导。这些参数的具体设置需要根据具体的模型和任务进行调整。
🖼️ 关键图片

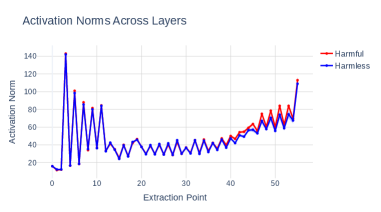

📊 实验亮点
实验结果表明,Selective Steering 在九个不同的模型上实现了比现有方法高5.5倍的攻击成功率,同时保持了零困惑度违规,并在标准基准测试中保持了约100%的能力。这意味着该方法在提高模型安全性的同时,不会对模型的性能产生明显的负面影响,具有很高的实用价值。
🎯 应用场景
该研究成果可应用于提高大型语言模型在各种场景下的安全性,例如防止模型生成有害内容、避免模型被用于恶意目的等。通过选择性地引导模型的行为,可以使其更加符合人类的价值观和道德规范。此外,该方法还可以用于个性化定制模型的行为,使其更好地适应特定用户的需求。
📄 摘要(原文)
Despite significant progress in alignment, large language models (LLMs) remain vulnerable to adversarial attacks that elicit harmful behaviors. Activation steering techniques offer a promising inference-time intervention approach, but existing methods suffer from critical limitations: activation addition requires careful coefficient tuning and is sensitive to layer-specific norm variations, while directional ablation provides only binary control. Recent work on Angular Steering introduces continuous control via rotation in a 2D subspace, but its practical implementation violates norm preservation, causing distribution shift and generation collapse, particularly in models below 7B parameters. We propose Selective Steering, which addresses these limitations through two key innovations: (1) a mathematically rigorous norm-preserving rotation formulation that maintains activation distribution integrity, and (2) discriminative layer selection that applies steering only where feature representations exhibit opposite-signed class alignment. Experiments across nine models demonstrate that Selective Steering achieves 5.5x higher attack success rates than prior methods while maintaining zero perplexity violations and approximately 100\% capability retention on standard benchmarks. Our approach provides a principled, efficient framework for controllable and stable LLM behavior modification. Code: https://github.com/knoveleng/steering