CHEHAB RL: Learning to Optimize Fully Homomorphic Encryption Computations
作者: Bilel Sefsaf, Abderraouf Dandani, Abdessamed Seddiki, Arab Mohammed, Eduardo Chielle, Michail Maniatakos, Riyadh Baghdadi
分类: cs.CR, cs.LG
发布日期: 2026-01-27
💡 一句话要点
提出CHEHAB RL,利用深度强化学习优化全同态加密计算。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全同态加密 深度强化学习 代码优化 向量化 隐私保护
📋 核心要点
- 全同态加密计算成本高昂,编写高效代码需专业知识,手动优化转换序列不可行。
- 利用深度强化学习,训练智能体学习重写规则序列,自动向量化FHE代码,降低延迟和噪声。
- 实验表明,相比Coyote,CHEHAB RL生成的代码执行速度提升5.3倍,噪声降低2.54倍,编译速度提升27.9倍。
📝 摘要(中文)
全同态加密(FHE)可以直接对加密数据进行计算,但其高计算成本仍然是一个显著的障碍。编写高效的FHE代码是一项复杂的任务,需要密码学专业知识,并且找到最佳的程序转换序列通常是难以处理的。在本文中,我们提出了CHEHAB RL,这是一个利用深度强化学习(RL)来自动优化FHE代码的新框架。我们的方法不是依赖于预定义的启发式方法或组合搜索,而是训练一个RL代理来学习一个有效的策略,应用一系列重写规则来自动向量化标量FHE代码,同时减少指令延迟和噪声增长。所提出的方法支持结构化和非结构化代码的优化。为了训练代理,我们使用大型语言模型(LLM)合成了一个多样化的计算数据集。我们将提出的方法集成到CHEHAB FHE编译器中,并在一个基准测试套件上评估它,将其性能与最先进的向量化FHE编译器Coyote进行比较。结果表明,我们的方法生成的代码在执行速度上快了5.3倍,累积的噪声减少了2.54倍,而编译过程本身比Coyote快了27.9倍(几何平均值)。
🔬 方法详解
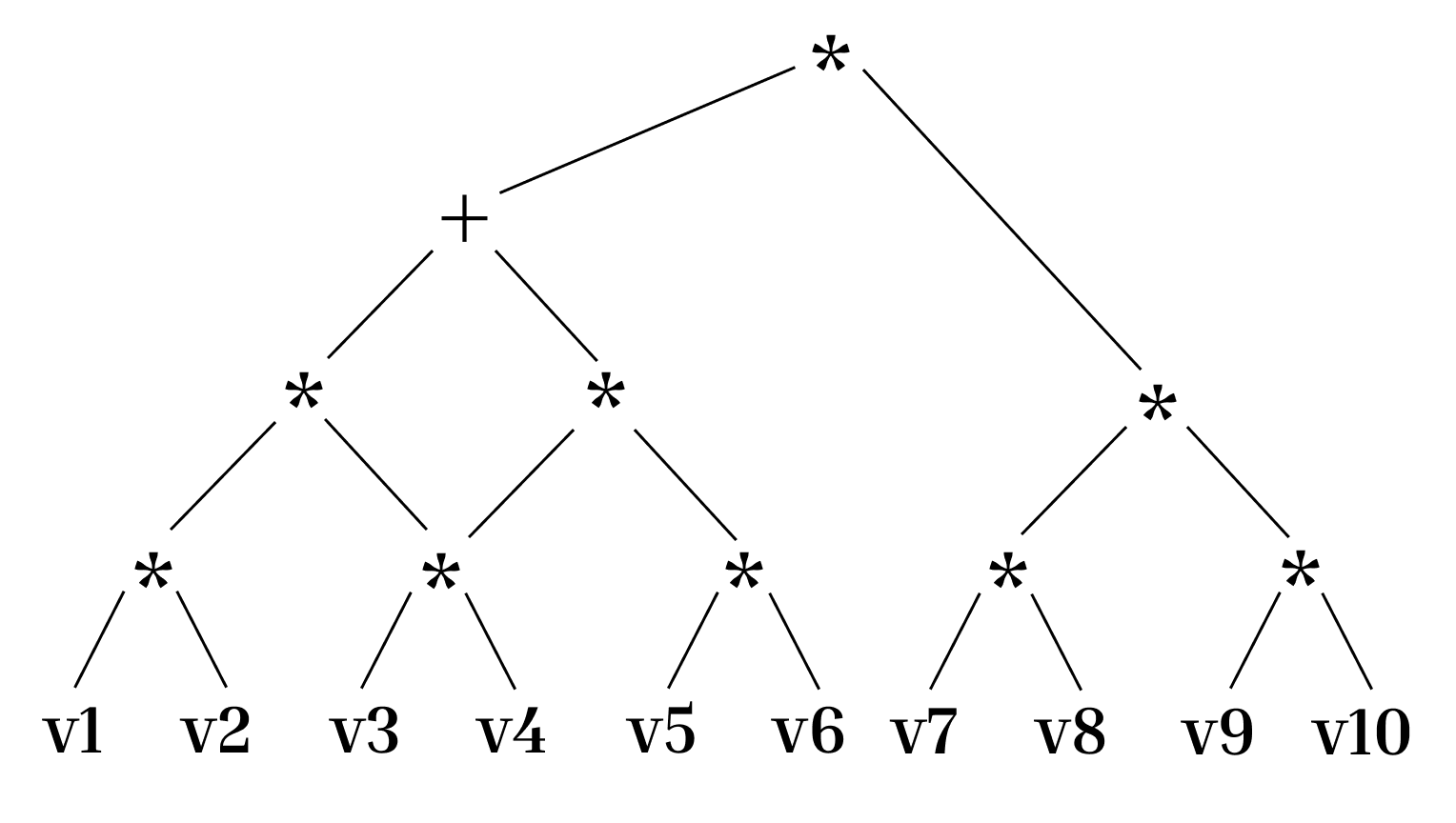
问题定义:全同态加密(FHE)允许直接在加密数据上进行计算,但其计算开销巨大。手动优化FHE代码,例如选择最佳的向量化策略,非常困难且耗时,需要专业的密码学知识。现有的编译器,如Coyote,依赖于预定义的启发式规则或组合搜索,效率较低,难以适应各种复杂的计算模式。
核心思路:CHEHAB RL的核心思想是利用深度强化学习(RL)来自动学习FHE代码的优化策略。通过将代码优化过程建模为一个马尔可夫决策过程(MDP),训练一个RL智能体来选择最佳的重写规则序列,从而实现代码的自动向量化,降低指令延迟和噪声增长。这种方法避免了手动设计启发式规则的复杂性,并能够自适应地优化各种类型的FHE代码。
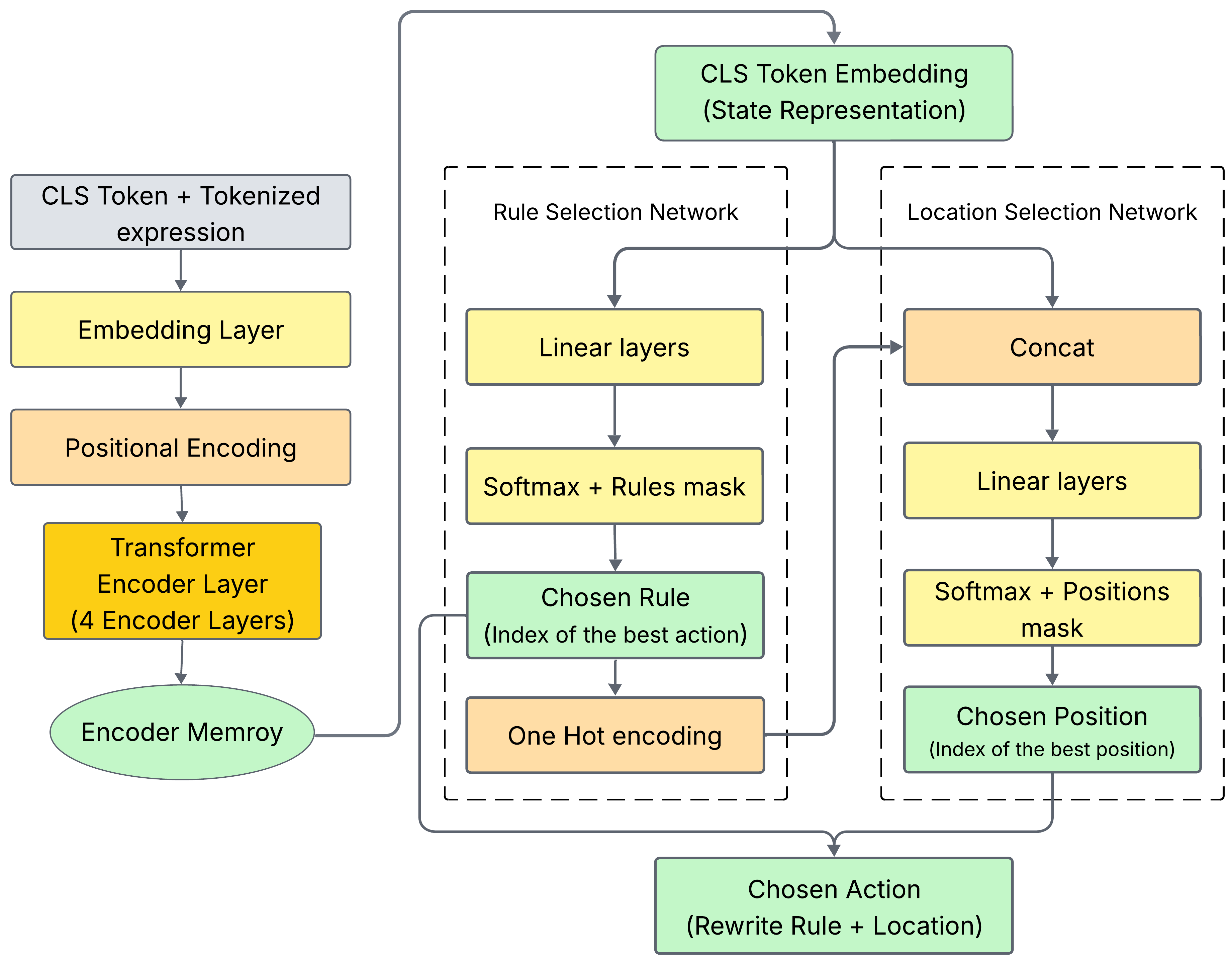
技术框架:CHEHAB RL框架主要包含以下几个模块:1) 环境(Environment):表示当前的FHE代码状态,包括抽象语法树(AST)和噪声预算等信息。2) 动作空间(Action Space):定义了一组可用的重写规则,用于转换FHE代码。3) 奖励函数(Reward Function):用于评估每个动作的优劣,例如执行时间、噪声增长等。4) RL智能体(RL Agent):使用深度神经网络来学习最佳的策略,选择合适的动作。5) 训练数据集(Training Dataset):使用大型语言模型(LLM)生成多样化的FHE计算代码,用于训练RL智能体。
关键创新:CHEHAB RL的关键创新在于将深度强化学习应用于FHE代码优化。与传统的基于启发式规则或组合搜索的方法不同,CHEHAB RL能够自动学习最佳的优化策略,并能够适应各种类型的FHE代码。此外,使用LLM生成训练数据,可以有效地提高RL智能体的泛化能力。
关键设计:CHEHAB RL使用深度Q网络(DQN)作为RL智能体,并采用经验回放和目标网络等技术来提高训练的稳定性。奖励函数的设计至关重要,需要综合考虑执行时间、噪声增长等因素。动作空间的设计需要仔细选择合适的重写规则,以保证代码优化的有效性。LLM生成的训练数据需要足够多样化,以覆盖各种类型的FHE计算模式。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CHEHAB RL在FHE代码优化方面取得了显著的性能提升。与最先进的向量化FHE编译器Coyote相比,CHEHAB RL生成的代码执行速度提升了5.3倍(几何平均值),累积的噪声降低了2.54倍(几何平均值),而编译过程本身也快了27.9倍(几何平均值)。这些结果表明,CHEHAB RL是一种高效且有效的FHE代码优化方法。
🎯 应用场景
CHEHAB RL可应用于各种需要保护数据隐私的场景,如联邦学习、安全多方计算、医疗数据分析等。通过自动优化FHE代码,降低计算成本,使得FHE技术能够更广泛地应用于实际场景,保护用户数据的隐私安全。未来,该技术有望进一步扩展到其他密码学算法的优化。
📄 摘要(原文)
Fully Homomorphic Encryption (FHE) enables computations directly on encrypted data, but its high computational cost remains a significant barrier. Writing efficient FHE code is a complex task requiring cryptographic expertise, and finding the optimal sequence of program transformations is often intractable. In this paper, we propose CHEHAB RL, a novel framework that leverages deep reinforcement learning (RL) to automate FHE code optimization. Instead of relying on predefined heuristics or combinatorial search, our method trains an RL agent to learn an effective policy for applying a sequence of rewriting rules to automatically vectorize scalar FHE code while reducing instruction latency and noise growth. The proposed approach supports the optimization of both structured and unstructured code. To train the agent, we synthesize a diverse dataset of computations using a large language model (LLM). We integrate our proposed approach into the CHEHAB FHE compiler and evaluate it on a suite of benchmarks, comparing its performance against Coyote, a state-of-the-art vectorizing FHE compiler. The results show that our approach generates code that is $5.3\times$ faster in execution, accumulates $2.54\times$ less noise, while the compilation process itself is $27.9\times$ faster than Coyote (geometric means).