Metric $k$-clustering using only Weak Comparison Oracles
作者: Rahul Raychaudhury, Aryan Esmailpour, Sainyam Galhotra, Stavros Sintos
分类: cs.LG, cs.DS
发布日期: 2026-01-27
期刊: ICLR 2026
💡 一句话要点
提出基于弱比较Oracle的度量k-聚类算法,适用于无精确距离信息的场景
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: k-聚类 弱比较Oracle Rank模型 度量学习 聚类算法 近似算法 倍增维数
📋 核心要点
- 传统k-聚类算法依赖精确距离,但在许多实际应用中难以获取,限制了算法的应用。
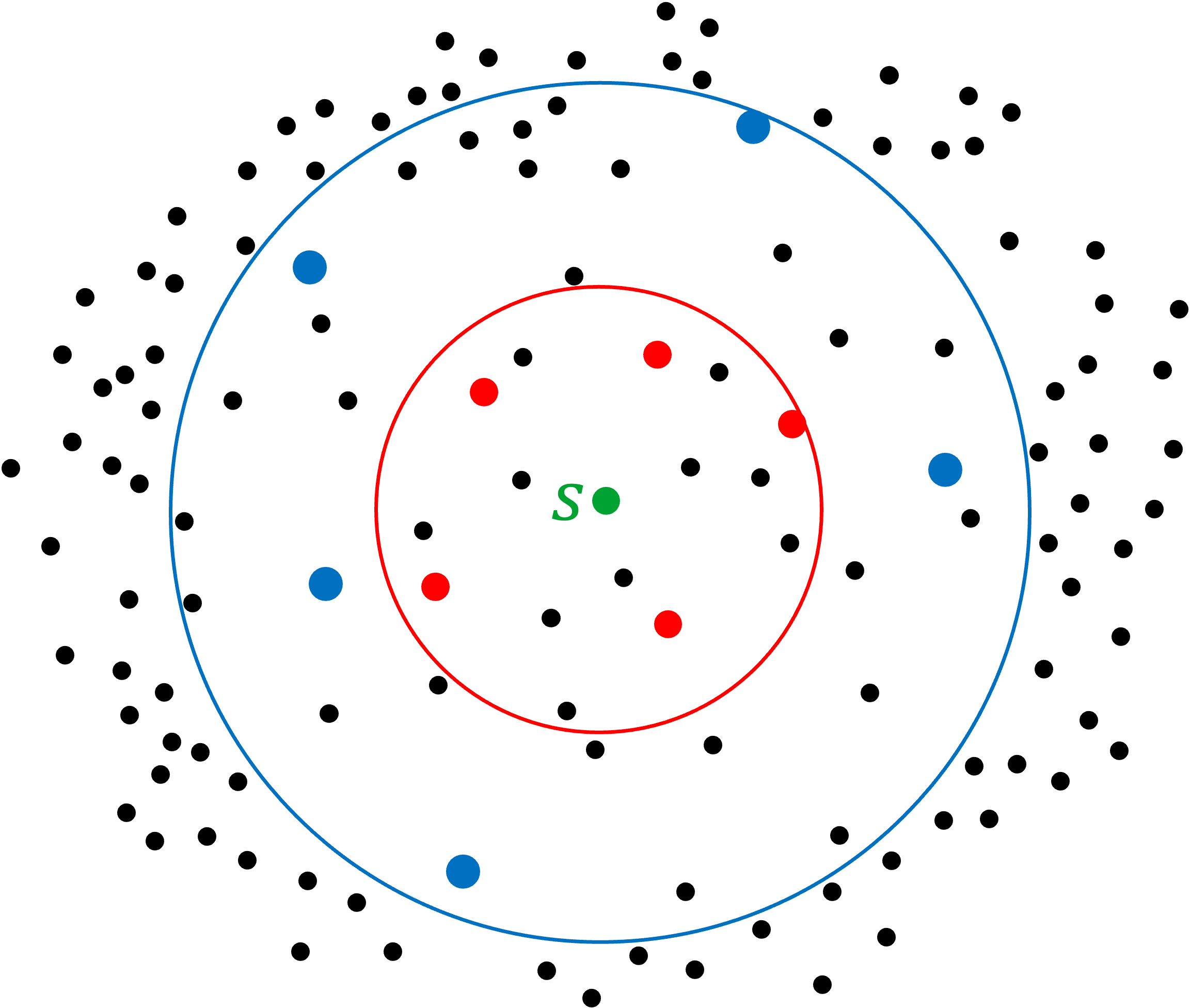
- 论文提出基于四元组Oracle的聚类方法,仅需相对距离比较,适用于噪声环境和低成本数据源。
- 算法在任意度量空间和有界倍增维数空间中均取得较好的聚类效果,并降低了查询复杂度。
📝 摘要(中文)
聚类是无监督学习中的一个基本任务。然而,经典的k-聚类算法(如k-median和k-means)假设可以访问精确的成对距离,这在许多现代应用中是不现实的要求。本文研究了Rank模型(R-model)中的聚类问题,其中对距离的访问完全被一个四元组Oracle所取代,该Oracle仅提供相对距离比较。在实践中,这样的Oracle可以代表学习模型或人类反馈,并且预期是有噪声的且需要访问成本。给定一个具有n个输入项的度量空间,我们设计了随机算法,该算法仅使用有噪声的四元组Oracle,计算出一个包含O(k·polylog(n))个中心的集合,以及从输入项到中心的映射,使得该映射的聚类成本至多是最佳k-聚类成本的常数倍。对于任意度量空间,我们的方法实现了O(n·k·polylog(n))的查询复杂度,并且当底层度量具有有界倍增维数时,查询复杂度提高到O((n+k^2)·polylog(n))。当度量具有有界倍增维数时,我们可以进一步将近似从常数提高到1+ε,对于任意小的常数ε∈(0,1),同时保持相同的渐近查询复杂度。我们的框架展示了如何将有噪声、低成本的Oracle(例如从大型语言模型导出的Oracle)系统地集成到可扩展的聚类算法中。
🔬 方法详解
问题定义:论文旨在解决在无法获取精确成对距离的情况下,如何进行有效的度量k-聚类。现有k-聚类算法依赖精确距离信息,这在许多实际场景中是不现实的,例如,当数据来自人类反馈或学习模型时,只能获得相对距离比较,且数据可能存在噪声。
核心思路:论文的核心思路是利用四元组Oracle提供的相对距离比较信息,代替精确距离信息进行聚类。通过这种方式,算法可以处理噪声数据,并降低对数据获取成本的要求。算法的目标是找到一组中心点,使得每个数据点到其最近中心的距离之和最小化,同时保证查询复杂度尽可能低。
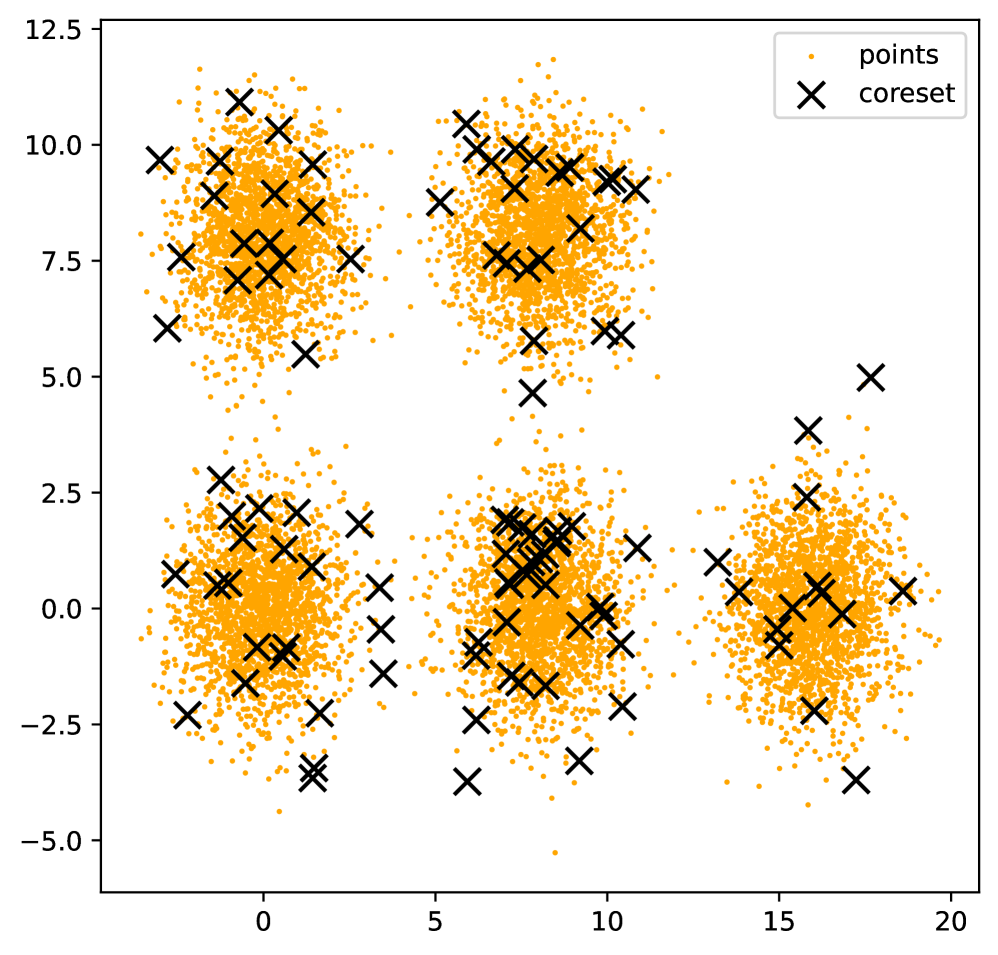
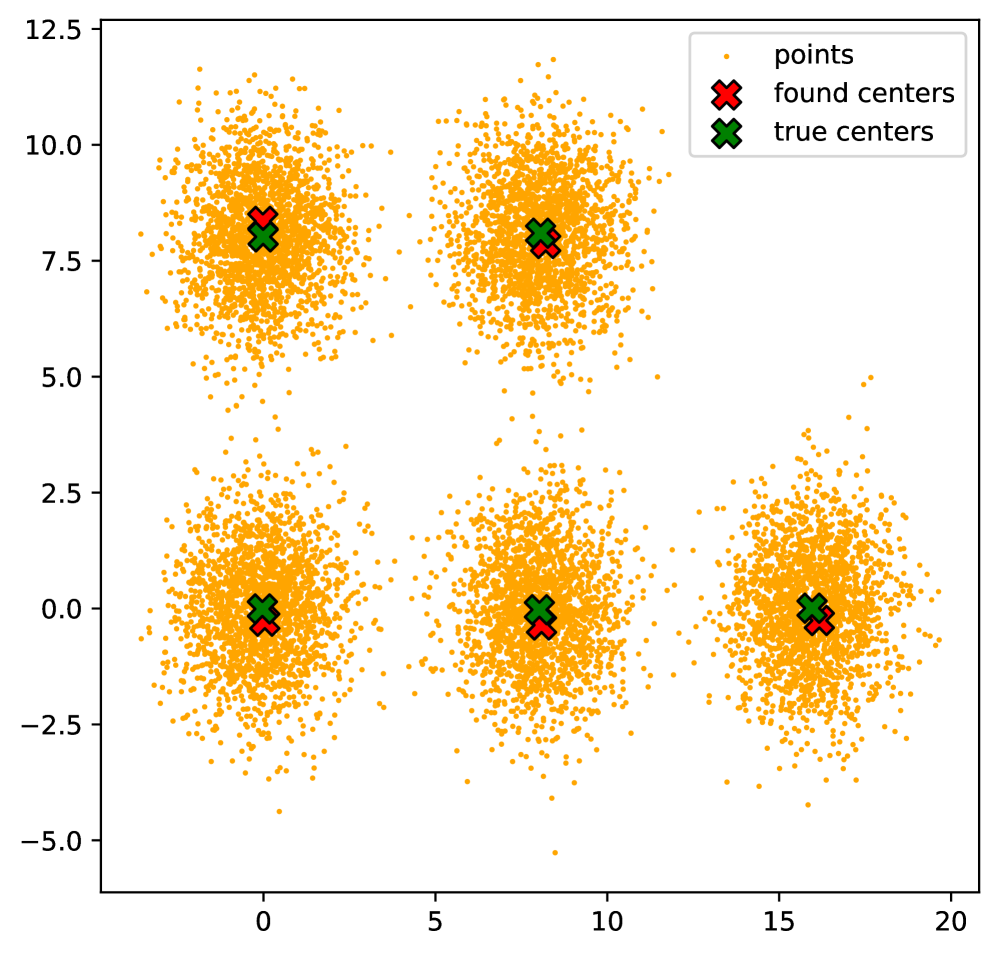
技术框架:整体框架包含以下几个主要阶段:1. 使用四元组Oracle进行采样,选择候选中心点。2. 将每个数据点分配到其最近的中心点,形成聚类。3. 迭代优化中心点和聚类分配,直到收敛。算法的关键在于如何有效地利用四元组Oracle进行采样和分配,以及如何保证算法的收敛性和近似比。
关键创新:最重要的技术创新点在于使用弱比较Oracle(四元组Oracle)代替精确距离信息进行聚类。这种方法使得算法可以应用于更广泛的场景,例如,当数据来自人类反馈或学习模型时。此外,算法还针对不同的度量空间(任意度量空间和有界倍增维数空间)设计了不同的采样和分配策略,以提高算法的效率和近似比。
关键设计:算法的关键设计包括:1. 如何设计四元组Oracle的查询策略,以最小化查询次数,同时保证采样质量。2. 如何设计数据点到中心点的分配策略,以最小化聚类成本。3. 如何设计迭代优化策略,以保证算法的收敛性和近似比。此外,算法还针对有界倍增维数空间设计了特殊的优化策略,以进一步提高算法的效率和近似比。
🖼️ 关键图片
📊 实验亮点
论文提出的算法在理论上证明了其近似比和查询复杂度。对于任意度量空间,算法实现了O(n·k·polylog(n))的查询复杂度,并且当底层度量具有有界倍增维数时,查询复杂度提高到O((n+k^2)·polylog(n))。当度量具有有界倍增维数时,可以将近似比从常数提高到1+ε,同时保持相同的渐近查询复杂度。这些结果表明,该算法在效率和精度方面都具有优势。
🎯 应用场景
该研究成果可应用于推荐系统、图像检索、社交网络分析等领域。例如,在推荐系统中,可以通过用户对物品的偏好关系(相对距离比较)进行用户聚类,从而实现个性化推荐。在图像检索中,可以通过图像之间的相似度比较进行图像聚类,从而提高检索效率。该方法还可以应用于生物信息学、金融风控等领域,具有广泛的应用前景。
📄 摘要(原文)
Clustering is a fundamental primitive in unsupervised learning. However, classical algorithms for $k$-clustering (such as $k$-median and $k$-means) assume access to exact pairwise distances -- an unrealistic requirement in many modern applications. We study clustering in the \emph{Rank-model (R-model)}, where access to distances is entirely replaced by a \emph{quadruplet oracle} that provides only relative distance comparisons. In practice, such an oracle can represent learned models or human feedback, and is expected to be noisy and entail an access cost. Given a metric space with $n$ input items, we design randomized algorithms that, using only a noisy quadruplet oracle, compute a set of $O(k \cdot \mathsf{polylog}(n))$ centers along with a mapping from the input items to the centers such that the clustering cost of the mapping is at most constant times the optimum $k$-clustering cost. Our method achieves a query complexity of $O(n\cdot k \cdot \mathsf{polylog}(n))$ for arbitrary metric spaces and improves to $O((n+k^2) \cdot \mathsf{polylog}(n))$ when the underlying metric has bounded doubling dimension. When the metric has bounded doubling dimension we can further improve the approximation from constant to $1+\varepsilon$, for any arbitrarily small constant $\varepsilon\in(0,1)$, while preserving the same asymptotic query complexity. Our framework demonstrates how noisy, low-cost oracles, such as those derived from large language models, can be systematically integrated into scalable clustering algorithms.