Group Distributionally Robust Optimization-Driven Reinforcement Learning for LLM Reasoning
作者: Kishan Panaganti, Zhenwen Liang, Wenhao Yu, Haitao Mi, Dong Yu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-27
备注: Keywords: Large Language Models, Reasoning Models, Reinforcement Learning, Distributionally Robust Optimization, GRPO
💡 一句话要点
提出基于Group DRO的强化学习框架,提升LLM在复杂推理任务中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 分布鲁棒优化 推理 动态训练 难度自适应 长尾问题
📋 核心要点
- 现有强化学习方法在训练LLM推理时,采用静态均匀采样策略,导致计算资源浪费在简单样本上,而困难样本训练不足。
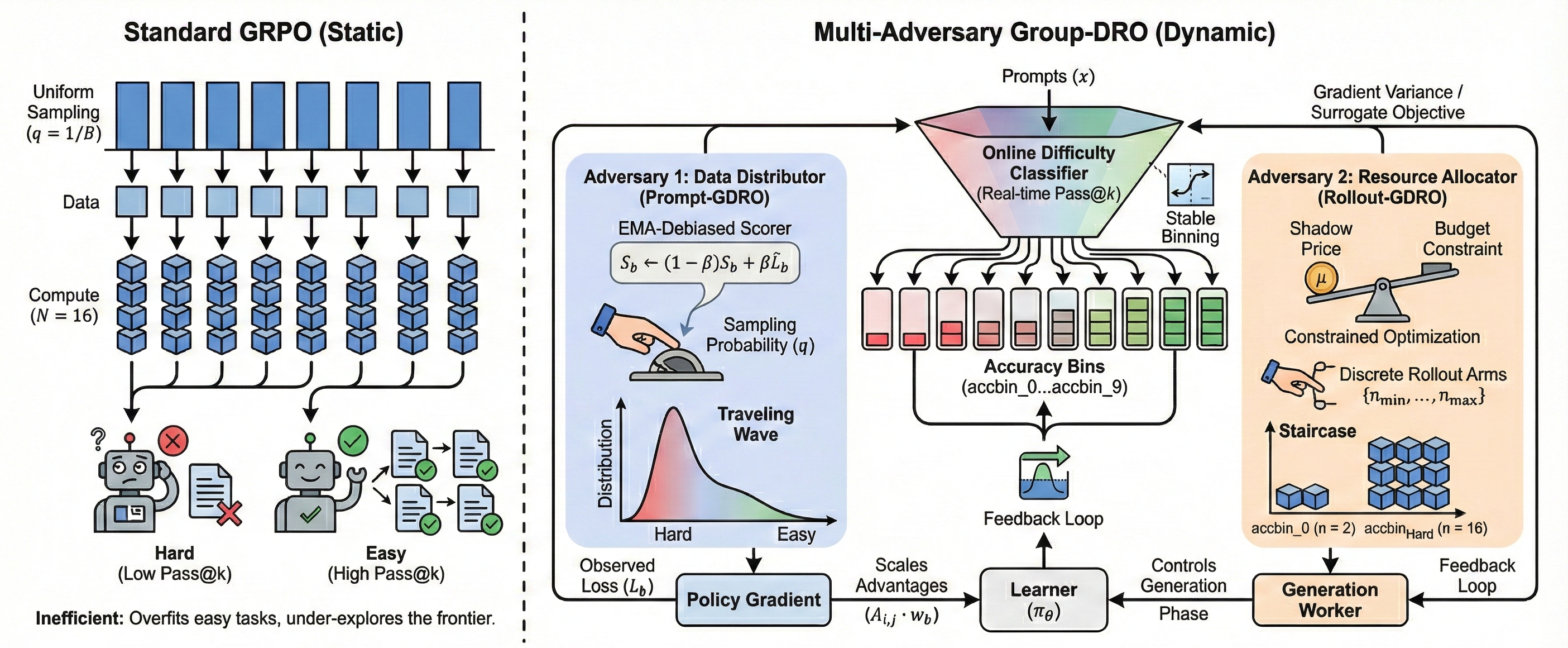
- 论文提出Multi-Adversary GDRO框架,通过在线难度分类器和两个GDRO博弈动态调整训练分布,关注困难样本。
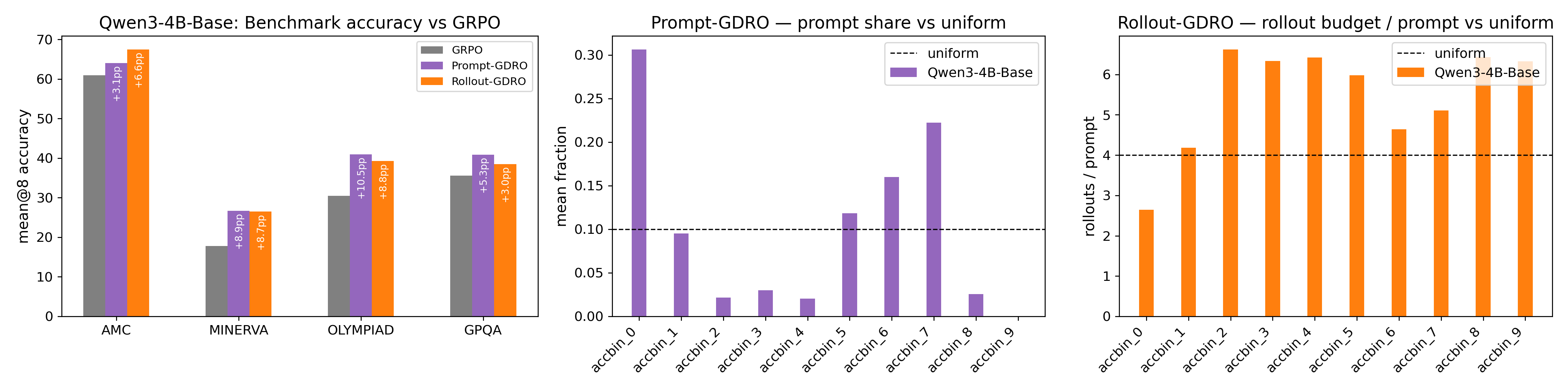
- 实验表明,Prompt-GDRO和Rollout-GDRO在不同规模的模型上,相比GRPO基线,pass@8准确率分别提升了10.6%和10.1%。
📝 摘要(中文)
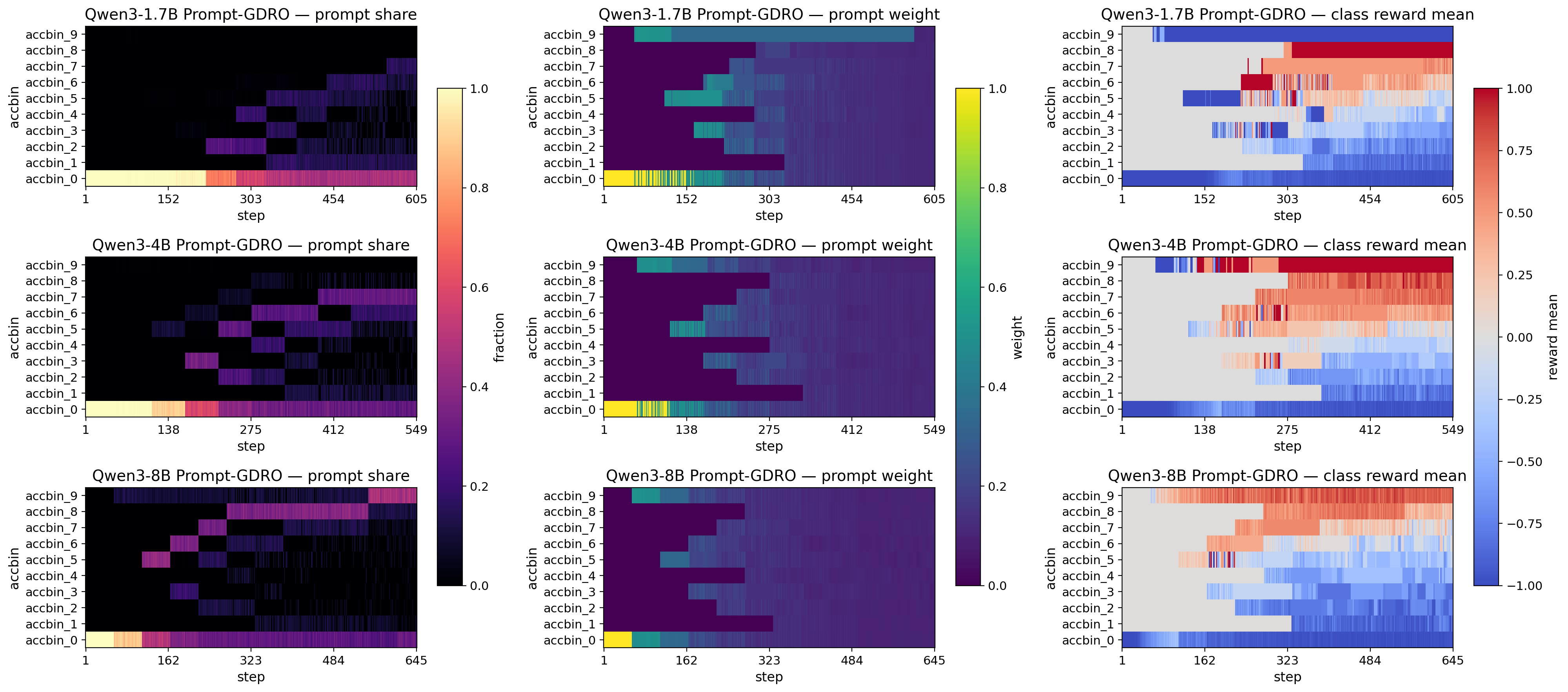
大语言模型(LLM)推理的最新进展越来越多地受到后训练损失函数和对齐策略改进的驱动。然而,诸如Group Relative Policy Optimization (GRPO) 等标准强化学习(RL)范式仍然受到静态均匀性的限制:均匀的prompt抽样和每个prompt固定数量的rollout。对于异构的、重尾的推理数据,这会造成结构性低效,浪费算力在已经解决的模式上,同时对困难问题的长尾进行欠训练。为了解决这个问题,我们提出了多对抗Group Distributionally Robust Optimization (GDRO),这是一个优化优先的框架,通过动态调整训练分布来超越均匀推理模型。我们引入了一个在线难度分类器,将prompt划分为动态的pass@k难度组。然后,我们为后训练提出了两个独立的GDRO博弈:(1)Prompt-GDRO,它采用EMA去偏的乘法权重bandit采样器来针对密集的难度裕度,并提升持续困难组的权重,而没有频率偏差;(2)Rollout-GDRO,它使用影子价格控制器在各组之间重新分配rollout,在固定的平均预算下最大化困难任务的梯度方差减少(计算中性)。我们为两个控制器提供了无遗憾保证,并额外提供了一个方差代理分析,为Rollout-GDRO提出了平方根最优rollout分配。我们使用Qwen3-Base模型在DAPO 14.1k数据集上验证了我们的框架。与GRPO基线相比,Prompt-GDRO和Rollout-GDRO在1.7B、4B和8B规模上分别实现了+10.6%和+10.1%的平均相对pass@8准确率增益。定性分析显示了一种涌现的课程:对抗者将资源转移到不断发展的推理前沿,从而增强了推理模型的性能。
🔬 方法详解
问题定义:现有基于强化学习的LLM推理训练方法,如GRPO,采用均匀的prompt采样和固定数量的rollout,无法有效处理推理数据中存在的异构性和长尾分布。这导致模型在简单问题上过度训练,而在困难问题上训练不足,计算资源利用率低。
核心思路:论文的核心思路是通过动态调整训练分布,使模型更多地关注困难样本。具体来说,通过在线难度分类器将prompt划分为不同的难度组,然后利用对抗学习的思想,设计两个GDRO博弈,分别调整prompt的采样概率和rollout的分配,从而优化模型的训练过程。
技术框架:整体框架包含以下几个主要模块:1) 在线难度分类器:根据模型在prompt上的表现,将prompt动态地划分为不同的难度组。2) Prompt-GDRO:使用EMA去偏的乘法权重bandit采样器,动态调整prompt的采样概率,增加困难组的采样概率。3) Rollout-GDRO:使用影子价格控制器,在固定的计算预算下,动态调整每个难度组的rollout数量,增加困难组的rollout数量。
关键创新:论文的关键创新在于提出了Multi-Adversary GDRO框架,该框架能够动态地调整训练分布,从而更有效地训练LLM进行复杂推理。与现有方法相比,该框架能够更好地处理推理数据中的异构性和长尾分布,提高计算资源利用率。此外,论文还为Rollout-GDRO提供了平方根最优rollout分配的理论分析。
关键设计:Prompt-GDRO使用EMA去偏的乘法权重bandit采样器,其关键参数包括学习率和探索率。Rollout-GDRO使用影子价格控制器,其关键参数包括影子价格的更新步长和计算预算。在线难度分类器使用pass@k指标来评估prompt的难度,k的取值会影响难度组的划分。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Prompt-GDRO和Rollout-GDRO在DAPO 14.1k数据集上,使用Qwen3-Base模型,在1.7B、4B和8B三种模型规模下,相比GRPO基线,pass@8准确率分别实现了+10.6%和+10.1%的平均相对增益。这表明该方法能够有效提升LLM在复杂推理任务中的性能。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的大语言模型应用场景,例如问答系统、代码生成、数学问题求解等。通过动态调整训练分布,可以显著提升模型在困难问题上的性能,提高用户体验,并降低计算成本。该方法还可推广到其他机器学习任务中,用于解决数据分布不均匀的问题。
📄 摘要(原文)
Recent progress in Large Language Model (LLM) reasoning is increasingly driven by the refinement of post-training loss functions and alignment strategies. However, standard Reinforcement Learning (RL) paradigms like Group Relative Policy Optimization (GRPO) remain constrained by static uniformity: uniform prompt sampling and a fixed number of rollouts per prompt. For heterogeneous, heavy-tailed reasoning data, this creates structural inefficiencies that waste compute on already-solved patterns while under-training the long tail of hard problems. To address this, we propose Multi-Adversary Group Distributionally Robust Optimization (GDRO), an optimization-first framework that moves beyond uniform reasoning models by dynamically adapting the training distribution. We introduce an Online Difficulty Classifier that partitions prompts into dynamic pass@k difficulty groups. We then propose two independent GDRO games for post-training: (1) Prompt-GDRO, which employs an EMA-debiased multiplicative-weights bandit sampler to target the intensive difficulty margin and upweight persistently hard groups without frequency bias; and (2) Rollout-GDRO, which uses a shadow-price controller to reallocate rollouts across groups, maximizing gradient variance reduction on hard tasks under a fixed mean budget (compute-neutral). We provide no-regret guarantees for both controllers and additionally a variance-proxy analysis motivating a square-root optimal rollout allocation for Rollout-GDRO. We validate our framework on the DAPO 14.1k dataset using Qwen3-Base models. Prompt-GDRO and Rollout-GDRO achieve average relative gains of +10.6% and +10.1%, respectively, in pass@8 accuracy across 1.7B, 4B, and 8B scales compared to the GRPO baseline. Qualitative analysis shows an emergent curriculum: the adversaries shift resources to the evolving reasoning frontier, enhancing the reasoning model's performance.