Whitespaces Don't Lie: Feature-Driven and Embedding-Based Approaches for Detecting Machine-Generated Code
作者: Syed Mehedi Hasan Nirob, Shamim Ehsan, Moqsadur Rahman, Summit Haque
分类: cs.SE, cs.LG
发布日期: 2026-01-27
💡 一句话要点
利用代码特征与嵌入,检测机器生成的代码,提升代码溯源能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成检测 机器学习 代码特征 代码嵌入 CodeBERT 学术诚信 软件安全
📋 核心要点
- 现有方法难以有效区分人工编写和机器生成的代码,给学术诚信和软件安全带来挑战。
- 论文提出结合代码特征与嵌入的检测方法,利用代码风格和语义信息进行判别。
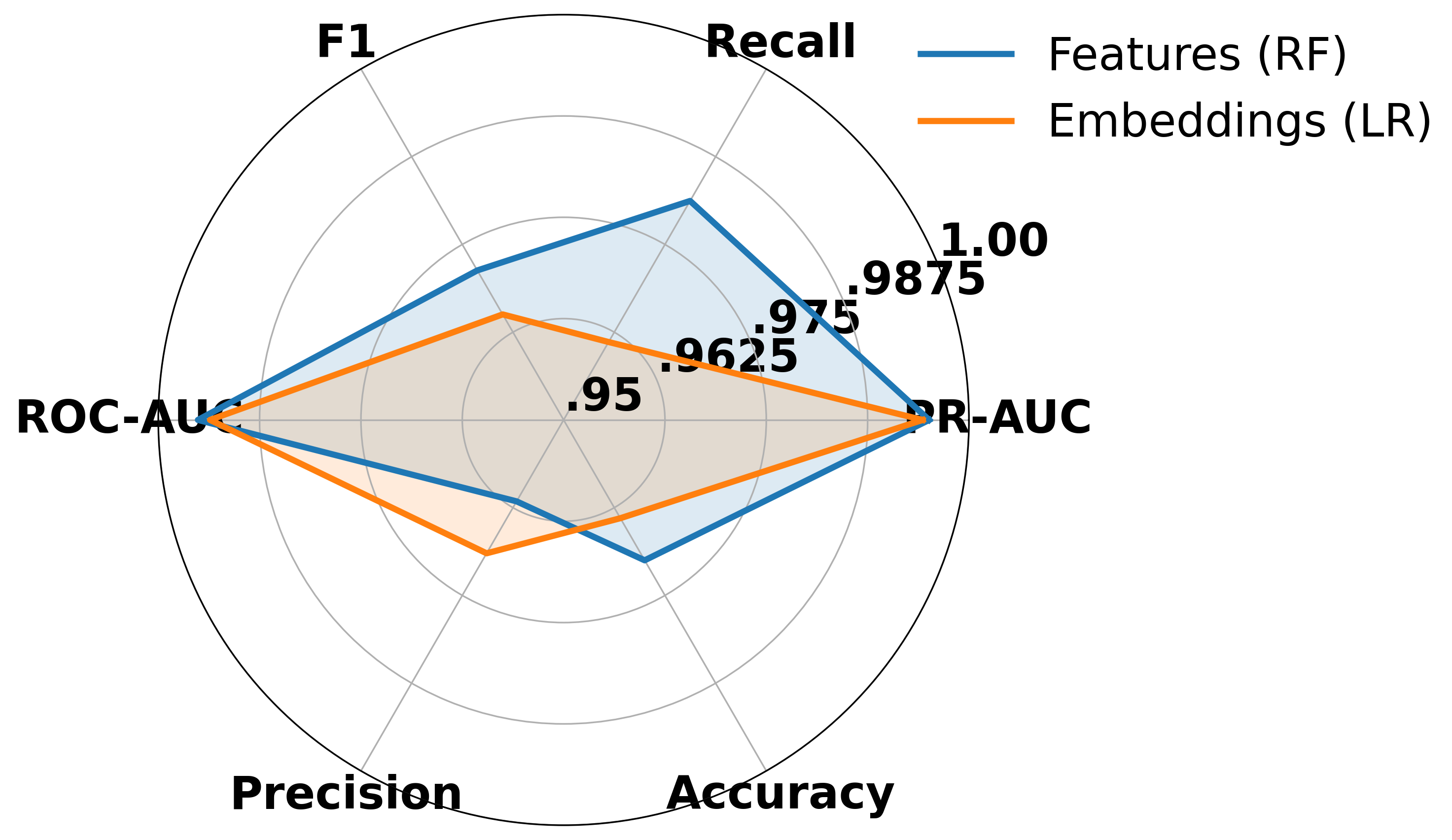
- 实验表明,该方法在区分人工与机器生成代码方面表现出色,AUC接近0.995。
📝 摘要(中文)
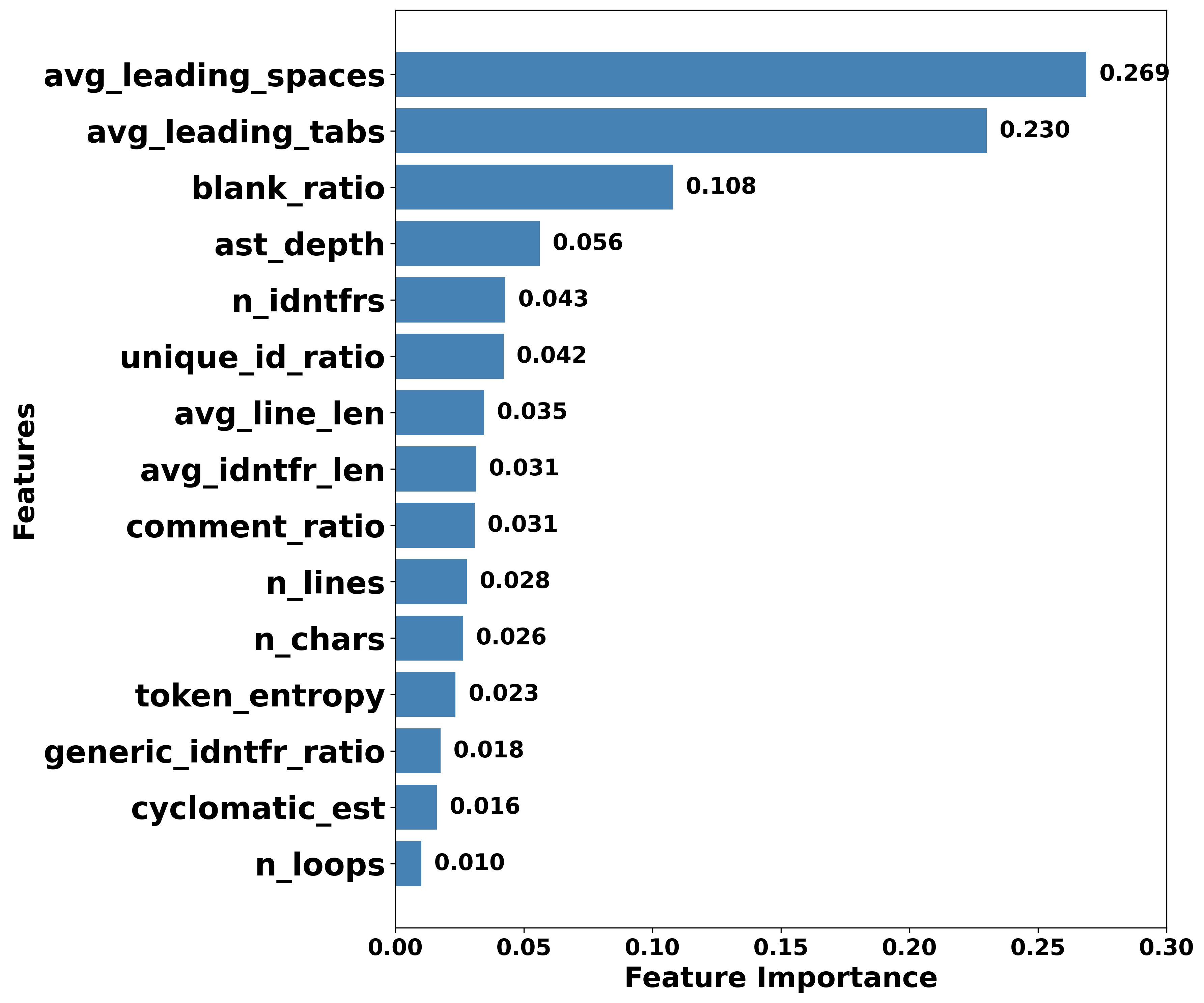
大型语言模型(LLM)能够根据自然语言提示生成看似合理的源代码,这在加速软件开发和支持学习的同时,也带来了学术诚信、作者身份归属和负责任的AI使用方面的新风险。本文研究了区分人工编写代码和机器生成代码的问题,比较了两种互补的方法:基于代码的轻量级、可解释的文体和结构属性构建的基于特征的检测器,以及利用预训练代码编码器的基于嵌入的检测器。使用包含60万个人工编写和AI生成代码样本的最新大规模基准数据集,我们发现基于特征的模型取得了强大的性能(ROC-AUC 0.995,PR-AUC 0.995,F1 0.971),而使用CodeBERT嵌入的基于嵌入的模型也具有很强的竞争力(ROC-AUC 0.994,PR-AUC 0.994,F1 0.965)。分析表明,与缩进和空格相关的特征提供了特别具有区分性的线索,而嵌入则捕获了更深层的语义模式,并产生了略高的精度。这些发现强调了解释性和泛化之间的权衡,为在学术和工业环境中部署强大的代码溯源检测提供了实践指导。
🔬 方法详解
问题定义:论文旨在解决区分人工编写代码和机器生成代码的问题。现有方法可能不够鲁棒,难以应对各种代码生成模型,并且缺乏可解释性,难以理解判断依据。
核心思路:论文的核心思路是结合代码的浅层特征(如空格、缩进)和深层语义信息(通过代码嵌入捕获)来提高检测的准确性和鲁棒性。利用浅层特征提供快速且可解释的判断依据,而深层语义信息则增强模型的泛化能力。
技术框架:该方法包含两个主要分支:基于特征的检测器和基于嵌入的检测器。基于特征的检测器提取代码的文体和结构特征,例如缩进、空格等,然后使用机器学习模型(具体模型未知)进行分类。基于嵌入的检测器使用预训练的代码编码器(如CodeBERT)将代码转换为嵌入向量,然后使用分类器(具体分类器未知)进行判别。
关键创新:该研究的关键创新在于结合了浅层代码特征和深层语义嵌入,充分利用了代码的不同层面的信息。此外,研究强调了空格和缩进等简单特征在区分人工编写和机器生成代码中的重要性,这为未来的研究提供了新的视角。
关键设计:论文中关于特征提取和嵌入的具体技术细节描述较少。基于特征的方法中,具体的特征选择方法和机器学习模型未知。基于嵌入的方法中,分类器的选择和训练策略也未知。但论文强调了CodeBERT嵌入的有效性,并分析了不同特征的重要性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于特征的模型和基于嵌入的模型均取得了优异的性能。基于特征的模型达到了ROC-AUC 0.995,PR-AUC 0.995,F1 0.971,而基于CodeBERT嵌入的模型也达到了ROC-AUC 0.994,PR-AUC 0.994,F1 0.965。研究强调了空格和缩进等特征的重要性,并发现嵌入能够捕获更深层的语义信息。
🎯 应用场景
该研究成果可应用于学术诚信检测,例如检测学生提交的代码是否为AI生成。此外,还可用于软件安全领域,例如识别恶意代码是否由AI生成,从而提高安全防护能力。该技术还有助于代码溯源和作者身份验证,为知识产权保护提供支持。
📄 摘要(原文)
Large language models (LLMs) have made it remarkably easy to synthesize plausible source code from natural language prompts. While this accelerates software development and supports learning, it also raises new risks for academic integrity, authorship attribution, and responsible AI use. This paper investigates the problem of distinguishing human-written from machine-generated code by comparing two complementary approaches: feature-based detectors built from lightweight, interpretable stylometric and structural properties of code, and embedding-based detectors leveraging pretrained code encoders. Using a recent large-scale benchmark dataset of 600k human-written and AI-generated code samples, we find that feature-based models achieve strong performance (ROC-AUC 0.995, PR-AUC 0.995, F1 0.971), while embedding-based models with CodeBERT embeddings are also very competitive (ROC-AUC 0.994, PR-AUC 0.994, F1 0.965). Analysis shows that features tied to indentation and whitespace provide particularly discriminative cues, whereas embeddings capture deeper semantic patterns and yield slightly higher precision. These findings underscore the trade-offs between interpretability and generalization, offering practical guidance for deploying robust code-origin detection in academic and industrial contexts.