LLM-Assisted Logic Rule Learning: Scaling Human Expertise for Time Series Anomaly Detection
作者: Haoting Zhang, Shekhar Jain
分类: cs.LG, cs.AI
发布日期: 2026-01-27
💡 一句话要点
提出LLM辅助的逻辑规则学习框架,解决供应链时序异常检测中专家知识规模化难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序异常检测 大型语言模型 逻辑规则学习 供应链管理 专家知识 可解释性 自动化 知识图谱
📋 核心要点
- 传统时序异常检测方法难以兼顾业务需求和领域知识,专家分析又无法规模化处理海量数据。
- 利用LLM将专家知识编码为可解释的逻辑规则,自动生成并优化规则,提升检测精度和可解释性。
- 实验表明,该方法优于无监督学习,且相比直接使用LLM,具有更低的延迟和成本,更适合部署。
📝 摘要(中文)
时序异常检测对于供应链管理至关重要,能够帮助企业采取积极的运营措施。然而,传统的基于数据模式的无监督异常检测方法,其结果往往与业务需求和领域知识不符;而人工专家分析又无法扩展到供应链中数百万种产品。本文提出了一种框架,利用大型语言模型(LLM)将人类专业知识系统地编码为可解释的、基于逻辑的规则,用于检测供应链时序数据中的异常模式。该方法包括三个阶段:1)在领域知识的指导下,基于LLM对训练数据进行标注;2)通过LLM驱动的优化,自动生成和迭代改进符号规则;3)利用LLM支持的、与业务相关的异常类别来增强规则的可解释性。实验结果表明,该方法在检测精度和可解释性方面均优于无监督学习方法。此外,与直接使用LLM进行时序异常检测相比,该方法提供了一致、确定的结果,且计算延迟和成本较低,非常适合生产部署。该框架展示了LLM如何在运营环境中弥合可扩展自动化和专家驱动决策之间的差距。
🔬 方法详解
问题定义:论文旨在解决供应链管理中时序数据异常检测的问题。现有方法,如传统的无监督学习,依赖于数据本身的统计特性,忽略了业务逻辑和专家经验,导致误报率高,难以满足实际需求。而人工分析虽然准确,但成本高昂,无法扩展到大规模数据集。因此,如何将专家知识融入到自动化异常检测流程中,是一个亟待解决的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)作为知识的载体和推理引擎,将领域专家的经验转化为可执行的逻辑规则。通过LLM的理解和生成能力,自动构建和优化这些规则,从而实现既能规模化处理数据,又能保证检测结果符合业务逻辑的目标。这种方法的核心在于将LLM从一个简单的预测模型,转变为一个知识驱动的规则生成和优化器。
技术框架:该框架包含三个主要阶段:1) LLM辅助的数据标注:利用LLM,根据领域知识对时序数据进行标注,生成训练数据。LLM在此阶段扮演着“标注员”的角色,将专家知识转化为可供机器学习模型学习的标签。2) LLM驱动的规则生成与优化:基于标注数据,自动生成初始的逻辑规则,并利用LLM进行迭代优化。LLM在此阶段扮演着“规则工程师”的角色,不断改进规则的准确性和泛化能力。3) LLM支持的规则增强与解释:利用LLM为规则添加业务相关的异常类别,增强规则的可解释性。LLM在此阶段扮演着“解释器”的角色,将抽象的规则转化为易于理解的业务语言。
关键创新:该方法最重要的创新点在于将LLM应用于逻辑规则的学习和优化,而不是直接用于时序数据的预测。这种间接应用方式,既利用了LLM的强大能力,又避免了直接使用LLM进行时序预测时可能出现的不稳定性和高计算成本。此外,通过将专家知识编码为可解释的逻辑规则,提高了异常检测结果的可解释性,增强了用户对模型的信任。
关键设计:在LLM辅助的数据标注阶段,需要设计合适的prompt,引导LLM根据领域知识生成准确的标签。在LLM驱动的规则生成与优化阶段,需要选择合适的规则表示形式(例如,基于时间序列特征的逻辑表达式),并设计有效的优化策略,例如基于遗传算法或强化学习的规则搜索算法。在LLM支持的规则增强与解释阶段,需要构建一个包含业务相关异常类别的知识库,并利用LLM将规则与这些类别进行关联。
🖼️ 关键图片
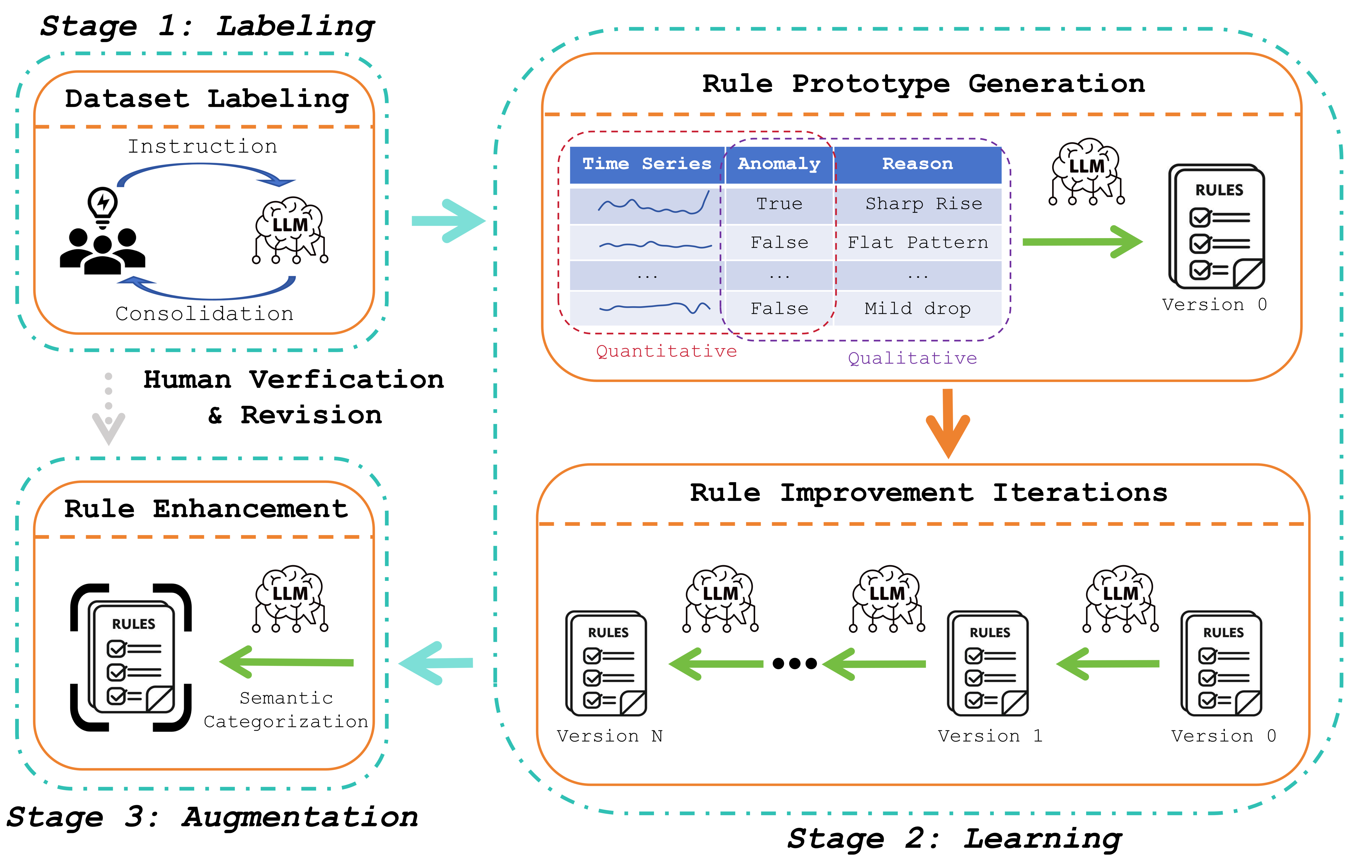
📊 实验亮点
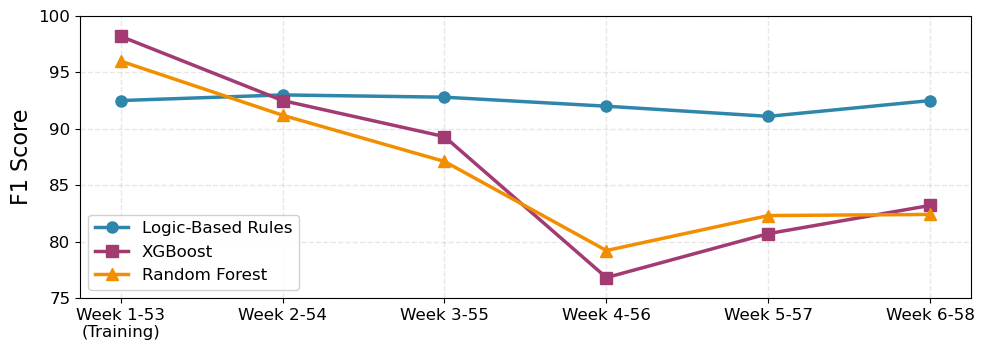
实验结果表明,该方法在时序异常检测任务中,相比于传统的无监督学习方法,在检测精度和可解释性方面均有显著提升。具体而言,该方法在准确率、召回率和F1值等指标上均优于对比基线。此外,与直接使用LLM进行时序异常检测相比,该方法具有更低的计算延迟和成本,更适合生产环境部署。
🎯 应用场景
该研究成果可广泛应用于供应链管理、金融风控、工业生产等领域,用于检测异常事件、预测潜在风险,并为决策者提供可解释的依据。通过将领域专家的知识融入到自动化系统中,可以显著提高运营效率和决策质量,降低运营成本和风险。未来,该方法有望扩展到其他类型的结构化数据,例如文本数据、图数据等。
📄 摘要(原文)
Time series anomaly detection is critical for supply chain management to take proactive operations, but faces challenges: classical unsupervised anomaly detection based on exploiting data patterns often yields results misaligned with business requirements and domain knowledge, while manual expert analysis cannot scale to millions of products in the supply chain. We propose a framework that leverages large language models (LLMs) to systematically encode human expertise into interpretable, logic-based rules for detecting anomaly patterns in supply chain time series data. Our approach operates in three stages: 1) LLM-based labeling of training data instructed by domain knowledge, 2) automated generation and iterative improvements of symbolic rules through LLM-driven optimization, and 3) rule augmentation with business-relevant anomaly categories supported by LLMs to enhance interpretability. The experiment results showcase that our approach outperforms the unsupervised learning methods in both detection accuracy and interpretability. Furthermore, compared to direct LLM deployment for time series anomaly detection, our approach provides consistent, deterministic results with low computational latency and cost, making it ideal for production deployment. The proposed framework thus demonstrates how LLMs can bridge the gap between scalable automation and expert-driven decision-making in operational settings.