Foresight Learning for SEC Risk Prediction
作者: Benjamin Turtel, Paul Wilczewski, Danny Franklin, Kris Skotheim
分类: cs.LG
发布日期: 2026-01-27
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出Foresight Learning,用于从SEC文件中预测风险概率,无需人工标注。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风险预测 SEC文件 Foresight Learning 自然语言处理 大型语言模型
📋 核心要点
- 现有方法难以量化SEC文件中风险披露的概率,缺乏大规模风险级别的监督数据是关键挑战。
- 论文提出Foresight Learning,通过全自动数据生成流程,将SEC风险披露转化为时间相关的监督信号。
- 实验表明,该方法训练的紧凑型语言模型在风险预测的准确性和校准方面优于现有模型,包括GPT-5。
📝 摘要(中文)
SEC文件中披露的风险描述了潜在的不利事件,但很少量化其可能性,限制了其在概率分析中的应用。一个核心障碍是缺乏大规模的、风险级别的监督,将披露的风险与实际结果联系起来。我们介绍了一种全自动的数据生成流程,它仅使用公共数据将定性的SEC风险披露转换为时间相关的监督。对于每个文件,该流程从“风险因素”部分生成公司特定的、时间限定的风险查询,并通过自动解析后续披露的结果来标记它们。使用这个基于SEC文件的风险查询和结果数据集,我们训练了一个紧凑的大型语言模型来估计披露的风险在指定期限内实现的概率。尽管模型规模不大,但结果模型在概率准确性和校准方面显著优于预训练和启发式基线,并且优于前沿通用模型,包括GPT-5。更广泛地说,这项工作表明,Foresight Learning能够仅使用原始的、按时间顺序排列的领域内文本,以可扩展且全自动的方式训练领域特定的专家模型——无需专有数据、外部语料库或手动注释。由此产生的模型实现了前沿水平的性能,同时仍然可以在单个GPU上部署。这一结果为从自然产生的企业文档中学习校准的、与决策相关的信号提供了一条通用途径。为了支持透明性和可重复性,我们开源了本研究中使用的评估数据集。
🔬 方法详解
问题定义:论文旨在解决SEC文件中风险披露的概率预测问题。现有方法的痛点在于,风险披露通常是定性的,缺乏量化信息,并且缺乏大规模的、将风险披露与实际结果联系起来的监督数据,导致难以进行概率分析。
核心思路:论文的核心思路是利用Foresight Learning,通过全自动的数据生成流程,从公开的SEC文件中提取风险披露信息,并将其转化为可用于训练模型的监督信号。具体来说,就是将风险披露转化为风险查询,并根据后续的SEC文件自动标注这些查询的结果。
技术框架:整体框架包含以下几个主要阶段:1) 从SEC文件中提取“风险因素”部分;2) 将风险因素转化为公司特定的、时间限定的风险查询;3) 通过自动解析后续披露的结果来标注这些查询;4) 使用标注好的数据训练一个紧凑的大型语言模型。
关键创新:最重要的技术创新点在于全自动的数据生成流程,它能够仅使用公开的SEC文件,无需人工标注或外部语料库,即可生成大规模的、时间相关的监督数据。这使得训练领域特定的风险预测模型成为可能。
关键设计:论文使用了一种紧凑的大型语言模型,具体结构未知。数据生成流程的关键在于如何将风险因素转化为有效的风险查询,以及如何准确地解析后续披露的结果来标注这些查询。论文开源了评估数据集和数据生成平台,但具体的技术细节未知。
🖼️ 关键图片
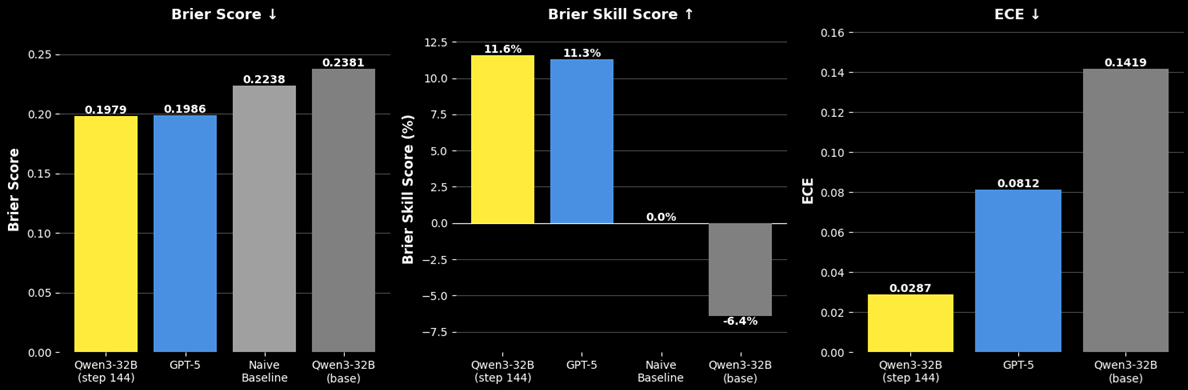
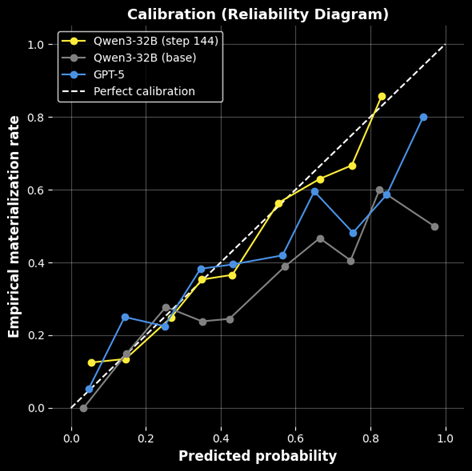
📊 实验亮点
实验结果表明,使用Foresight Learning训练的紧凑型语言模型在风险预测的准确性和校准方面显著优于预训练和启发式基线,并且优于前沿通用模型,包括GPT-5。具体性能数据未知,但论文强调了在单个GPU上部署的可行性。
🎯 应用场景
该研究成果可应用于金融风险管理、投资决策支持、企业合规性评估等领域。通过自动分析SEC文件中的风险披露,可以帮助投资者和监管机构更好地了解企业的潜在风险,并做出更明智的决策。未来,该方法可以扩展到其他类型的企业文档,以提取和预测各种类型的风险。
📄 摘要(原文)
Risk disclosures in SEC filings describe potential adverse events but rarely quantify their likelihood, limiting their usefulness for probabilistic analysis. A central obstacle is the absence of large-scale, risk-level supervision linking disclosed risks to realized outcomes. We introduce a fully automated data generation pipeline that converts qualitative SEC risk disclosures into temporally grounded supervision using only public data. For each filing, the pipeline generates firm-specific, time-bounded risk queries from the Risk Factors section and labels them by automatically resolving outcomes against subsequent disclosures. Using this dataset of risk queries and outcomes grounded in SEC filings, we train a compact large language model to estimate the probability that a disclosed risk will materialize within a specified horizon. Despite its modest size, the resulting model substantially improves over pretrained and heuristic baselines, and outperforms frontier general-purpose models, including GPT-5, on probabilistic accuracy and calibration. More broadly, this work demonstrates that Foresight Learning enables scalable and fully automated training of domain-specific expert models using only raw, chronological, in-domain text -- without proprietary data, external corpora, or manual annotation. The resulting models achieve frontier-level performance while remaining deployable on a single GPU. This result suggests a general pathway for learning calibrated, decision-relevant signals from naturally occurring enterprise documents. To support transparency and reproducibility, we open-source the evaluation dataset used in this study. Evaluation Data: https://huggingface.co/datasets/LightningRodLabs/sec_risk_questions_test_set Data Generation Platform: https://lightningrod.ai/ SDK: https://github.com/lightning-rod-labs/lightningrod-python-sdk