Double Fairness Policy Learning: Integrating Action Fairness and Outcome Fairness in Decision-making
作者: Zeyu Bian, Lan Wang, Chengchun Shi, Zhengling Qi
分类: stat.ML, cs.LG
发布日期: 2026-01-27
💡 一句话要点
提出双重公平策略学习框架,解决决策中的行动公平与结果公平问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 公平性 策略学习 多目标优化 行动公平 结果公平
📋 核心要点
- 现有策略学习方法较少关注公平性,尤其缺乏对行动公平和结果公平的综合考虑。
- 提出双重公平学习(DFL)框架,通过多目标优化显式平衡行动公平、结果公平和价值最大化。
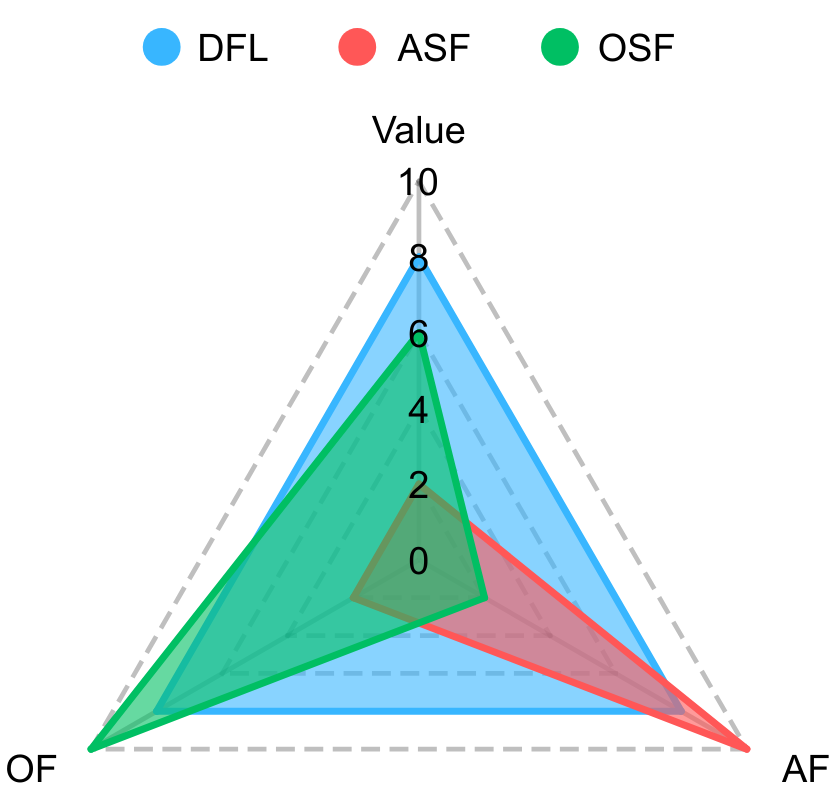
- 实验表明,DFL在模拟和真实数据集上均能有效提升行动和结果公平性,同时保持较好的价值。
📝 摘要(中文)
公平性是可信机器学习的核心支柱,尤其是在仅靠准确性或利润驱动的优化不足的领域。虽然大多数公平性研究集中在监督学习上,但策略学习中的公平性研究仍然较少。由于策略学习是介入性的,因此它会产生两个不同的公平性目标:行动公平(公平的行动分配)和结果公平(公平的下游结果)。至关重要的是,当群体面临不同的约束或对同一行动的反应不同时,均等化行动通常不会均等化结果。我们提出了一个新的双重公平学习(DFL)框架,该框架明确地管理三个目标之间的权衡:行动公平、结果公平和价值最大化。我们将公平性直接整合到策略学习的多目标优化问题中,并采用词典加权Tchebyshev方法,该方法可以恢复凸设置之外的Pareto解,并具有关于遗憾界限的理论保证。我们的框架是灵活的,可以适应各种常用的公平性概念。大量的模拟表明,相对于竞争方法,性能有所提高。在应用于汽车第三方责任保险数据集和创业培训数据集时,DFL在行动和结果公平性方面都有了显著提高,而总体价值的降低幅度很小。
🔬 方法详解
问题定义:论文旨在解决策略学习中行动公平和结果公平难以兼顾的问题。现有方法通常只关注单一维度的公平性,或者简单地将公平性作为约束条件,无法有效权衡公平性和价值最大化。此外,不同群体对相同策略的反应可能不同,导致行动公平并不一定带来结果公平。
核心思路:论文的核心思路是将行动公平、结果公平和价值最大化整合到一个多目标优化问题中,通过寻找Pareto最优解来平衡这三个目标。这种方法允许在不同目标之间进行权衡,从而找到更符合实际需求的策略。
技术框架:DFL框架主要包含以下几个阶段:1) 定义行动公平和结果公平的度量标准;2) 将公平性度量和价值函数整合到多目标优化问题中;3) 使用词典加权Tchebyshev方法求解多目标优化问题,该方法能够找到Pareto最优解,即使在非凸情况下也能有效工作;4) 根据求解结果,选择合适的策略。
关键创新:该论文的关键创新在于提出了一个能够同时考虑行动公平和结果公平的策略学习框架。与现有方法相比,DFL能够更灵活地处理公平性约束,并在不同目标之间进行权衡。此外,使用词典加权Tchebyshev方法保证了能够找到Pareto最优解,即使在非凸情况下也能有效工作。
关键设计:论文的关键设计包括:1) 使用不同的公平性度量标准来定义行动公平和结果公平,例如统计均等、机会均等;2) 使用词典加权Tchebyshev方法来求解多目标优化问题,该方法通过设置不同的权重来控制不同目标的重要性;3) 针对具体的应用场景,设计合适的价值函数和策略表示。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DFL框架在模拟数据集和真实数据集上均取得了显著的性能提升。在汽车第三方责任保险数据集和创业培训数据集上,DFL在行动和结果公平性方面都有了显著提高,同时总体价值的降低幅度很小。与现有方法相比,DFL能够更好地平衡公平性和价值最大化。
🎯 应用场景
该研究具有广泛的应用前景,例如在信贷审批、招聘、教育资源分配等领域,可以帮助决策者制定更公平、更合理的策略。通过平衡行动公平和结果公平,可以减少歧视,促进社会公平。此外,该框架还可以应用于其他需要考虑多个目标的决策问题。
📄 摘要(原文)
Fairness is a central pillar of trustworthy machine learning, especially in domains where accuracy- or profit-driven optimization is insufficient. While most fairness research focuses on supervised learning, fairness in policy learning remains less explored. Because policy learning is interventional, it induces two distinct fairness targets: action fairness (equitable action assignments) and outcome fairness (equitable downstream consequences). Crucially, equalizing actions does not generally equalize outcomes when groups face different constraints or respond differently to the same action. We propose a novel double fairness learning (DFL) framework that explicitly manages the trade-off among three objectives: action fairness, outcome fairness, and value maximization. We integrate fairness directly into a multi-objective optimization problem for policy learning and employ a lexicographic weighted Tchebyshev method that recovers Pareto solutions beyond convex settings, with theoretical guarantees on the regret bounds. Our framework is flexible and accommodates various commonly used fairness notions. Extensive simulations demonstrate improved performance relative to competing methods. In applications to a motor third-party liability insurance dataset and an entrepreneurship training dataset, DFL substantially improves both action and outcome fairness while incurring only a modest reduction in overall value.