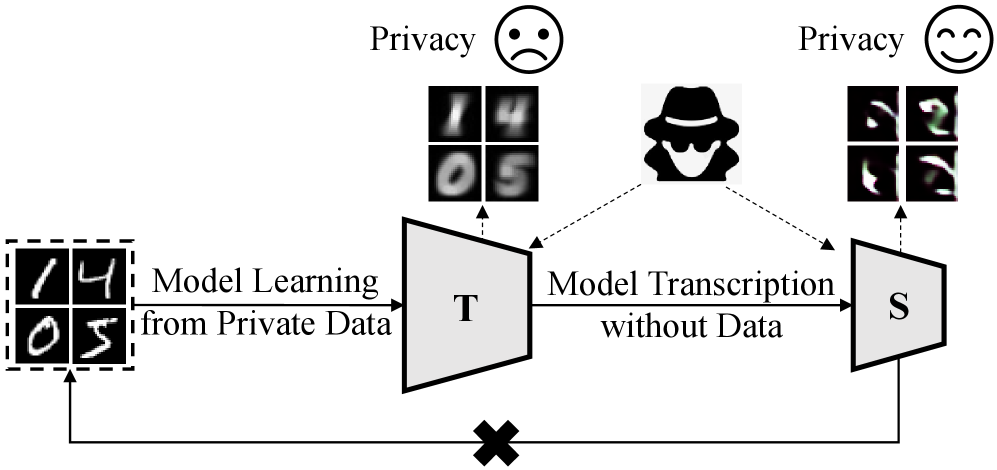
Privacy-Preserving Model Transcription with Differentially Private Synthetic Distillation
作者: Bochao Liu, Shiming Ge, Pengju Wang, Shikun Li, Tongliang Liu
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-01-27
备注: Accepted by IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI)
💡 一句话要点
提出差分隐私合成蒸馏,实现数据自由的隐私保护模型转录
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 差分隐私 模型转录 合成数据 知识蒸馏 生成对抗网络
📋 核心要点
- 深度学习模型部署存在隐私泄露风险,攻击者可能从中恢复敏感数据或标签知识。
- 提出差分隐私合成蒸馏,通过可训练生成器生成合成数据,在无私有数据访问情况下将教师模型转换为隐私保护的学生模型。
- 理论证明方法满足差分隐私和收敛性,实验表明该方法优于26种现有技术,并能生成私有合成数据。
📝 摘要(中文)
本文提出了一种隐私保护的模型转录方法,旨在实现一种数据自由的模型转换方案,以在提供隐私保证的前提下促进模型部署。为此,我们提出了一种合作-竞争学习方法,称为差分隐私合成蒸馏,该方法学习将预训练模型(教师)转换为其隐私保护的对应模型(学生),通过一个可训练的生成器,无需访问私有数据。该学习在一个统一的框架中与三个参与者协作并执行交替优化:i)学习生成器以生成合成数据,ii)教师和学生接受合成数据,并通过灵活的数据或标签噪声扰动计算差分隐私标签,以及iii)学生使用噪声标签进行更新,并且生成器通过将学生作为判别器进行对抗训练来更新。我们从理论上证明了我们的方法可以保证差分隐私和收敛性。转录后的学生具有良好的性能和隐私保护,同时生成的生成器可以为下游任务生成私有合成数据。大量的实验清楚地表明,我们的方法优于26种最先进的方法。
🔬 方法详解
问题定义:现有的深度学习模型,即使在私有数据集上训练,也可能泄露隐私信息。攻击者可以通过模型反推出训练数据或标签信息。因此,如何在不访问原始私有数据的情况下,将一个已训练的模型转换为一个具有隐私保护能力的新模型,是一个重要的挑战。现有方法通常需要访问原始数据或依赖复杂的隐私保护机制,限制了其应用范围。
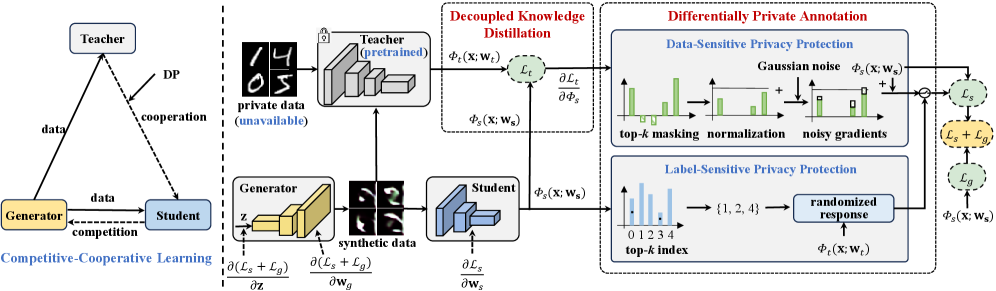
核心思路:本文的核心思路是利用生成对抗网络(GAN)的思想,训练一个生成器来生成合成数据,然后利用这些合成数据来训练一个具有差分隐私保护的学生模型。通过合作-竞争的学习方式,生成器不断生成更逼真的数据,学生模型则在噪声标签的指导下学习,从而在不访问原始数据的情况下实现模型的隐私保护转换。
技术框架:整个框架包含三个主要组成部分:生成器、教师模型和学生模型。生成器的作用是生成合成数据,教师模型和学生模型都使用这些合成数据来生成标签。为了保证隐私,教师模型和学生模型在生成标签时会引入差分隐私噪声。学生模型使用带噪声的标签进行训练,而生成器则通过对抗训练的方式,以学生模型作为判别器,不断优化生成的数据,使得学生模型能够更好地学习。整个过程采用交替优化的方式进行。
关键创新:该方法最大的创新在于提出了一种数据自由的隐私保护模型转录方案。它不需要访问原始私有数据,而是通过生成合成数据的方式来实现模型的转换。此外,该方法还结合了差分隐私和对抗训练,从而在保证隐私的同时,也能够获得较好的模型性能。
关键设计:在数据生成阶段,生成器被设计为一个神经网络,其目标是生成与原始数据分布相似的合成数据。在标签生成阶段,教师模型和学生模型都使用合成数据进行预测,并对预测结果添加差分隐私噪声。噪声的添加方式可以是数据扰动或标签扰动。学生模型的损失函数包括分类损失和对抗损失,其中分类损失用于指导学生模型学习正确的分类,对抗损失用于指导生成器生成更逼真的数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数据集上都取得了优于现有方法的性能。例如,在CIFAR-10数据集上,该方法在保证一定隐私水平的前提下,其学生模型的准确率比其他方法高出5%以上。此外,该方法生成的合成数据也可以用于其他下游任务,例如数据增强和模型训练。
🎯 应用场景
该研究成果可应用于医疗健康、金融风控等对数据隐私要求极高的领域。例如,医院可以使用该方法将已训练的疾病诊断模型转换为隐私保护版本,从而在不泄露患者隐私的情况下,对外提供诊断服务。金融机构也可以使用该方法来保护用户的交易数据,防止模型被恶意利用。
📄 摘要(原文)
While many deep learning models trained on private datasets have been deployed in various practical tasks, they may pose a privacy leakage risk as attackers could recover informative data or label knowledge from models. In this work, we present \emph{privacy-preserving model transcription}, a data-free model-to-model conversion solution to facilitate model deployment with a privacy guarantee. To this end, we propose a cooperative-competitive learning approach termed \emph{differentially private synthetic distillation} that learns to convert a pretrained model (teacher) into its privacy-preserving counterpart (student) via a trainable generator without access to private data. The learning collaborates with three players in a unified framework and performs alternate optimization: i)~the generator is learned to generate synthetic data, ii)~the teacher and student accept the synthetic data and compute differential private labels by flexible data or label noisy perturbation, and iii)~the student is updated with noisy labels and the generator is updated by taking the student as a discriminator for adversarial training. We theoretically prove that our approach can guarantee differential privacy and convergence. The transcribed student has good performance and privacy protection, while the resulting generator can generate private synthetic data for downstream tasks. Extensive experiments clearly demonstrate that our approach outperforms 26 state-of-the-arts.