Multi-Objective Reinforcement Learning for Efficient Tactical Decision Making for Trucks in Highway Traffic
作者: Deepthi Pathare, Leo Laine, Morteza Haghir Chehreghani
分类: cs.LG, cs.AI, eess.SY
发布日期: 2026-01-26
💡 一句话要点
提出基于多目标强化学习的卡车高速公路行驶策略优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 自动驾驶卡车 高速公路行驶 战术决策 近端策略优化
📋 核心要点
- 传统方法难以兼顾重型车辆高速行驶中的安全性、效率和运营成本等多重目标,且标量奖励函数掩盖了目标间的权衡关系。
- 提出基于PPO的多目标强化学习框架,学习一组帕累托最优策略,显式地表示安全性、能源效率和时间效率之间的权衡。
- 实验结果表明,该方法能够生成平滑且可解释的帕累托前沿,实现不同驾驶策略间的无缝切换,提升决策的鲁棒性和适应性。
📝 摘要(中文)
重型车辆在高速公路行驶中,平衡安全性、效率和运营成本是一个具有挑战性的决策问题。传统的标量奖励函数通过聚合这些相互冲突的目标,往往掩盖了它们之间的权衡结构。本文提出了一种基于近端策略优化(Proximal Policy Optimization, PPO)的多目标强化学习框架,用于学习一组连续的策略,显式地表示这些权衡。该方法在一个可扩展的卡车战术决策仿真平台上进行评估。结果表明,该方法能够学习一组连续的帕累托最优策略,捕捉安全性(通过碰撞和成功完成任务来量化)、能源效率(通过能源成本量化)和时间效率(通过驾驶员成本量化)这三个相互冲突的目标之间的权衡。由此产生的帕累托前沿是平滑且可解释的,从而能够灵活地选择不同冲突目标下的驾驶行为。该框架允许在不同的驾驶策略之间无缝切换而无需重新训练,从而为自动驾驶卡车应用提供了一种鲁棒且自适应的决策策略。
🔬 方法详解
问题定义:论文旨在解决重型卡车在高速公路行驶场景下的战术决策问题,即如何在安全性、能源效率和时间效率这三个相互冲突的目标之间进行权衡。现有方法通常将这些目标聚合为单一的标量奖励函数,导致无法清晰地表达和控制不同目标之间的权衡关系,难以满足实际应用中对策略灵活性的需求。
核心思路:论文的核心思路是采用多目标强化学习(MORL)框架,将安全性、能源效率和时间效率作为独立的优化目标,学习一组帕累托最优策略。通过这种方式,可以显式地表示不同目标之间的权衡关系,并允许根据实际需求选择合适的策略,从而提高决策的灵活性和适应性。
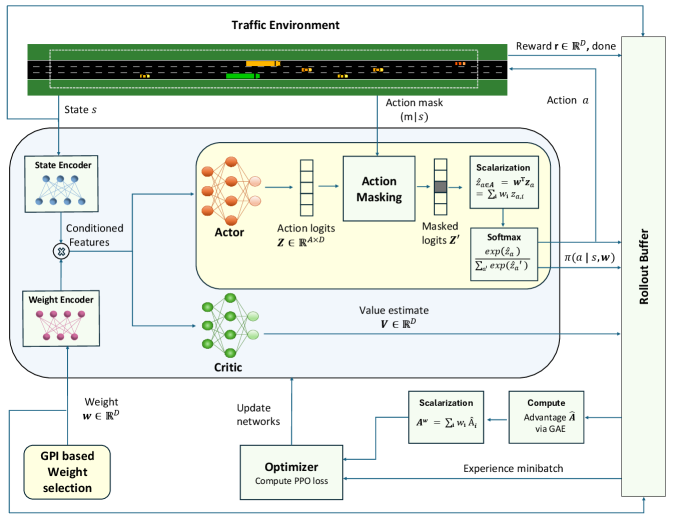
技术框架:该方法基于近端策略优化(PPO)算法,构建了一个多目标强化学习框架。整体流程如下:首先,定义状态空间、动作空间和多个奖励函数(分别对应安全性、能源效率和时间效率)。然后,使用PPO算法训练一个策略网络,该网络能够根据当前状态输出一个动作。在训练过程中,通过调整不同目标的权重,可以学习到一组帕累托最优策略。最后,根据实际需求,从帕累托前沿上选择合适的策略进行部署。
关键创新:该方法最重要的技术创新点在于将多目标强化学习应用于卡车高速公路行驶的战术决策问题,并成功地学习到一组连续的帕累托最优策略。与传统的单目标强化学习方法相比,该方法能够显式地表示不同目标之间的权衡关系,并提供更大的决策灵活性。此外,该方法还能够实现不同驾驶策略之间的无缝切换,从而提高决策的鲁棒性和适应性。
关键设计:论文中使用了PPO算法作为基础的强化学习算法,并针对多目标优化问题进行了改进。具体的技术细节包括:定义了三个独立的奖励函数,分别对应安全性、能源效率和时间效率;使用线性标量化方法来组合多个奖励函数,并通过调整权重来学习不同的帕累托最优策略;设计了一个合适的策略网络结构,以实现高效的策略学习。
🖼️ 关键图片

📊 实验亮点
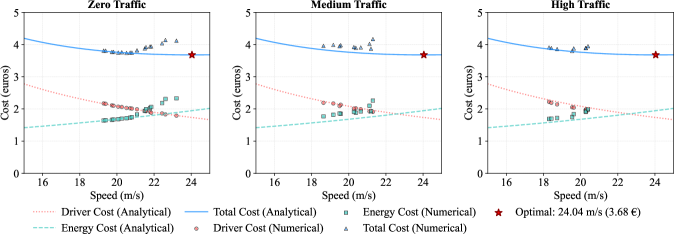
实验结果表明,该方法能够学习到一组连续且平滑的帕累托最优策略,有效地捕捉了安全性、能源效率和时间效率之间的权衡关系。通过调整不同目标的权重,可以灵活地选择不同的驾驶策略。与传统的单目标强化学习方法相比,该方法能够提供更大的决策灵活性和更好的性能。具体性能数据未知,但帕累托前沿的平滑性表明了学习效果的良好。
🎯 应用场景
该研究成果可应用于自动驾驶卡车领域,提升其在高速公路行驶中的决策能力。通过权衡安全性、效率和成本,自动驾驶系统可以根据实际交通状况和运营需求,灵活选择合适的驾驶策略。例如,在交通拥堵时,可以选择更注重安全性的策略;在时间紧急时,可以选择更注重效率的策略。此外,该方法还可以应用于其他需要权衡多个目标的决策问题,如机器人导航、资源分配等。
📄 摘要(原文)
Balancing safety, efficiency, and operational costs in highway driving poses a challenging decision-making problem for heavy-duty vehicles. A central difficulty is that conventional scalar reward formulations, obtained by aggregating these competing objectives, often obscure the structure of their trade-offs. We present a Proximal Policy Optimization based multi-objective reinforcement learning framework that learns a continuous set of policies explicitly representing these trade-offs and evaluates it on a scalable simulation platform for tactical decision making in trucks. The proposed approach learns a continuous set of Pareto-optimal policies that capture the trade-offs among three conflicting objectives: safety, quantified in terms of collisions and successful completion; energy efficiency and time efficiency, quantified using energy cost and driver cost, respectively. The resulting Pareto frontier is smooth and interpretable, enabling flexibility in choosing driving behavior along different conflicting objectives. This framework allows seamless transitions between different driving policies without retraining, yielding a robust and adaptive decision-making strategy for autonomous trucking applications.