POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration
作者: Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, Aviral Kumar
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-26
💡 一句话要点
POPE:通过特权On-Policy探索学习解决复杂推理问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 复杂推理 探索策略 特权学习 On-Policy 语言模型 问题求解
📋 核心要点
- 现有强化学习方法在解决复杂推理问题时,由于探索不足,难以获得有效奖励信号。
- POPE利用oracle提供的部分解决方案作为特权信息,引导On-Policy RL进行更有效的探索。
- 实验表明,POPE能够扩展可解决问题的范围,并显著提高在具有挑战性的推理基准上的性能。
📝 摘要(中文)
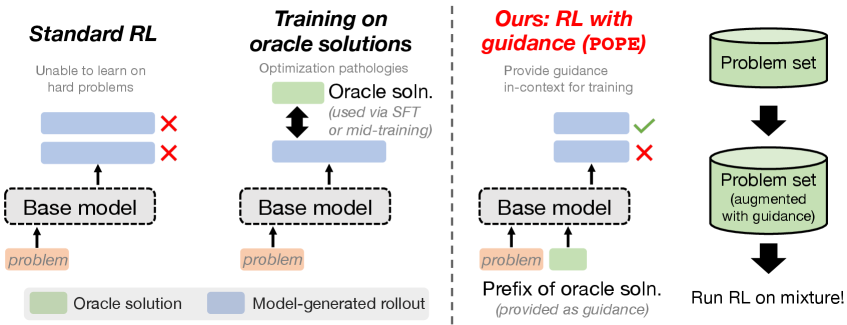
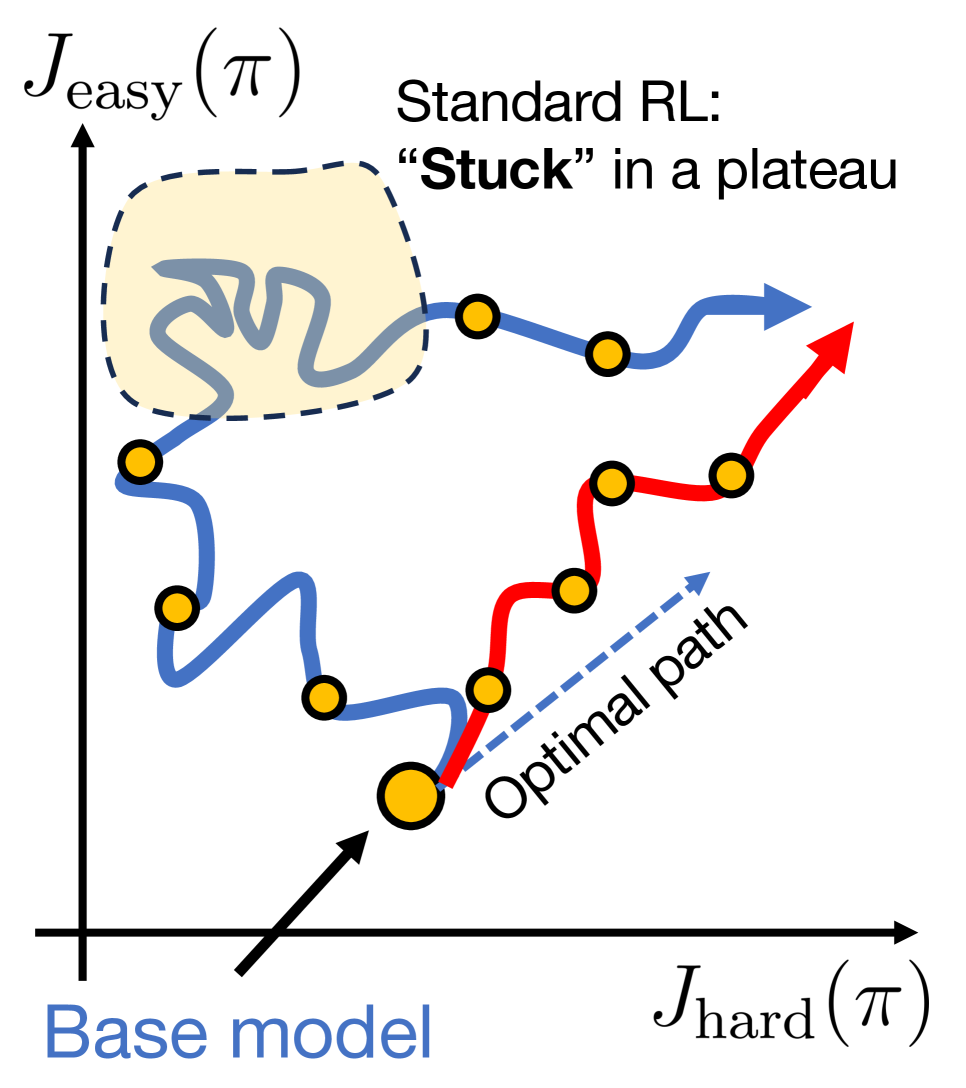
强化学习(RL)提升了大型语言模型(LLM)的推理能力,但现有方法在许多训练问题上仍然无法学习。在复杂问题上,On-Policy RL很少探索到哪怕一次正确的完整轨迹,导致零奖励,无法驱动改进。论文发现,经典RL中用于解决探索问题的自然方法,如熵奖励、更宽松的重要性采样比例裁剪或直接优化pass@k目标,都无法解决此问题,反而会破坏优化稳定性,且不提升可解性。一个自然的替代方案是利用从简单问题迁移学习。然而,论文表明,在RL训练期间混合简单和复杂问题会适得其反,因为射线干涉会导致优化集中在已解决的问题上,从而积极抑制较难问题的进展。为了解决这个挑战,论文提出了特权On-Policy探索(POPE),该方法利用人类或其他oracle解决方案作为特权信息来指导复杂问题的探索,这与将oracle解决方案作为训练目标的方法(例如,Off-Policy RL方法或从SFT进行warmstarting)不同。POPE使用oracle解决方案的前缀来扩充复杂问题,使RL能够在引导的轨迹中获得非零奖励。关键是,通过指令遵循和推理之间的协同作用,由此产生的行为可以转移回原始的、无引导的问题。
🔬 方法详解
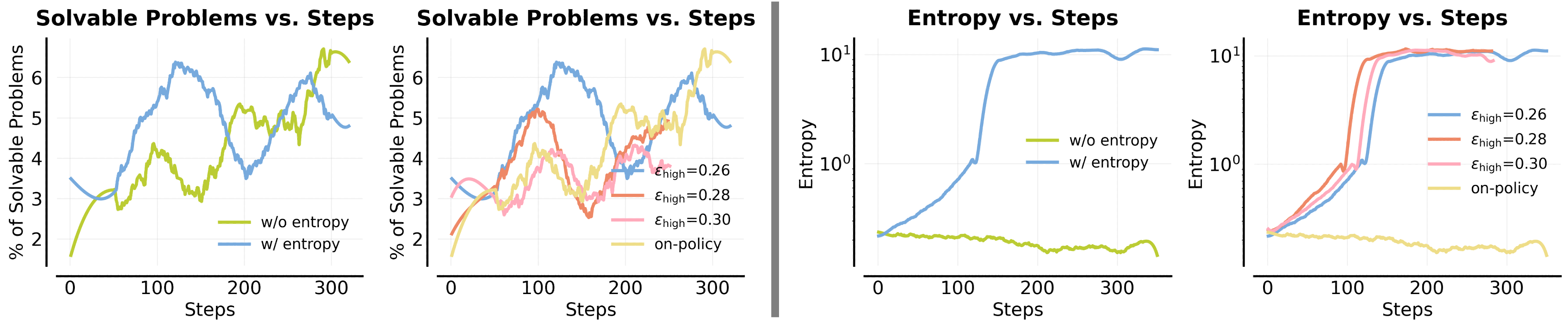
问题定义:论文旨在解决强化学习在复杂推理任务中探索不足的问题。现有方法,如熵奖励、重要性采样比例裁剪等,无法有效解决该问题,甚至会破坏优化过程。简单地混合简单和困难问题进行训练也会由于射线干涉而导致性能下降。
核心思路:POPE的核心思路是利用oracle(如人类专家或已知的最优策略)提供的部分解决方案作为特权信息,引导强化学习智能体在复杂问题中进行更有效的探索。通过提供部分正确的轨迹,智能体可以获得非零奖励,从而学习到有用的策略。
技术框架:POPE方法主要包含以下几个阶段:1) 问题增强:将原始的复杂问题与oracle提供的部分解决方案的前缀进行拼接,形成新的训练问题。2) On-Policy RL训练:使用增强后的问题进行On-Policy强化学习训练,智能体在oracle引导下进行探索,获得奖励信号。3) 策略迁移:训练好的策略被迁移到原始的、未增强的问题上,智能体在没有oracle引导的情况下进行推理。
关键创新:POPE的关键创新在于利用oracle信息的方式。与传统的Off-Policy RL或SFT warmstarting不同,POPE不是将oracle解决方案作为训练目标,而是将其作为探索的引导。这种方式能够更好地利用oracle信息,同时避免了Off-Policy RL的方差问题和SFT warmstarting的泛化性问题。
关键设计:POPE的关键设计包括:1) Oracle信息编码:如何将oracle提供的部分解决方案有效地编码到问题中,以便智能体能够理解和利用。2) 奖励函数设计:如何设计奖励函数,使得智能体能够最大化地利用oracle引导,并最终学习到解决原始问题的策略。3) 策略迁移策略:如何确保训练好的策略能够有效地迁移到原始的、未增强的问题上。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,POPE方法能够显著提高强化学习智能体在复杂推理任务上的性能。与传统的On-Policy RL方法相比,POPE能够扩展可解决问题的范围,并取得更高的奖励。实验结果表明,POPE在多个具有挑战性的推理基准上都取得了显著的提升,验证了其有效性。
🎯 应用场景
POPE方法可以应用于各种需要复杂推理和规划的任务,例如代码生成、数学问题求解、游戏AI等。通过利用专家知识或已知的最优策略,POPE可以帮助强化学习智能体更快地学习到有效的策略,从而提高解决复杂问题的能力。该方法在教育、自动化和人工智能等领域具有广泛的应用前景。
📄 摘要(原文)
Reinforcement learning (RL) has improved the reasoning abilities of large language models (LLMs), yet state-of-the-art methods still fail to learn on many training problems. On hard problems, on-policy RL rarely explores even a single correct rollout, yielding zero reward and no learning signal for driving improvement. We find that natural solutions to remedy this exploration problem from classical RL, such as entropy bonuses, more permissive clipping of the importance ratio, or direct optimization of pass@k objectives, do not resolve this issue and often destabilize optimization without improving solvability. A natural alternative is to leverage transfer from easier problems. However, we show that mixing easy and hard problems during RL training is counterproductive due to ray interference, where optimization focuses on already-solvable problems in a way that actively inhibits progress on harder ones. To address this challenge, we introduce Privileged On-Policy Exploration (POPE), an approach that leverages human- or other oracle solutions as privileged information to guide exploration on hard problems, unlike methods that use oracle solutions as training targets (e.g., off-policy RL methods or warmstarting from SFT). POPE augments hard problems with prefixes of oracle solutions, enabling RL to obtain non-zero rewards during guided rollouts. Crucially, the resulting behaviors transfer back to the original, unguided problems through a synergy between instruction-following and reasoning. Empirically, POPE expands the set of solvable problems and substantially improves performance on challenging reasoning benchmarks.