HalluGuard: Demystifying Data-Driven and Reasoning-Driven Hallucinations in LLMs
作者: Xinyue Zeng, Junhong Lin, Yujun Yan, Feng Guo, Liang Shi, Jun Wu, Dawei Zhou
分类: cs.LG, cs.AI
发布日期: 2026-01-26
备注: Have been accepted by ICLR'26
💡 一句话要点
HalluGuard:通过NTK几何学统一检测LLM中的数据驱动和推理驱动幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 神经切核 数据驱动幻觉 推理驱动幻觉 风险界限 LLM可靠性
📋 核心要点
- 现有LLM幻觉检测方法通常只关注数据或推理单一来源,且依赖任务特定规则,泛化性不足。
- 提出HalluGuard,基于神经切核(NTK)几何,统一建模并检测数据驱动和推理驱动两种幻觉。
- 在10个基准测试中,HalluGuard超越了11个基线模型,并在9个LLM骨干网络上取得了SOTA性能。
📝 摘要(中文)
大型语言模型(LLM)在医疗、法律和科学发现等高风险领域的可靠性常常因幻觉而受损。这些失败通常源于两个方面:数据驱动的幻觉和推理驱动的幻觉。然而,现有的检测方法通常只针对其中一种来源,并且依赖于特定任务的启发式方法,限制了它们在复杂场景中的泛化能力。为了克服这些限制,我们引入了幻觉风险界限,这是一个统一的理论框架,它将幻觉风险正式分解为数据驱动和推理驱动的组成部分,分别与训练时的不匹配和推理时的不稳定性相关联。这为分析幻觉如何产生和演变提供了原则性基础。在此基础上,我们引入了HalluGuard,一种基于NTK的分数,它利用NTK的诱导几何和捕获的表示来共同识别数据驱动和推理驱动的幻觉。我们在10个不同的基准、11个有竞争力的基线和9个流行的LLM骨干上评估了HalluGuard,在检测各种形式的LLM幻觉方面始终实现了最先进的性能。
🔬 方法详解
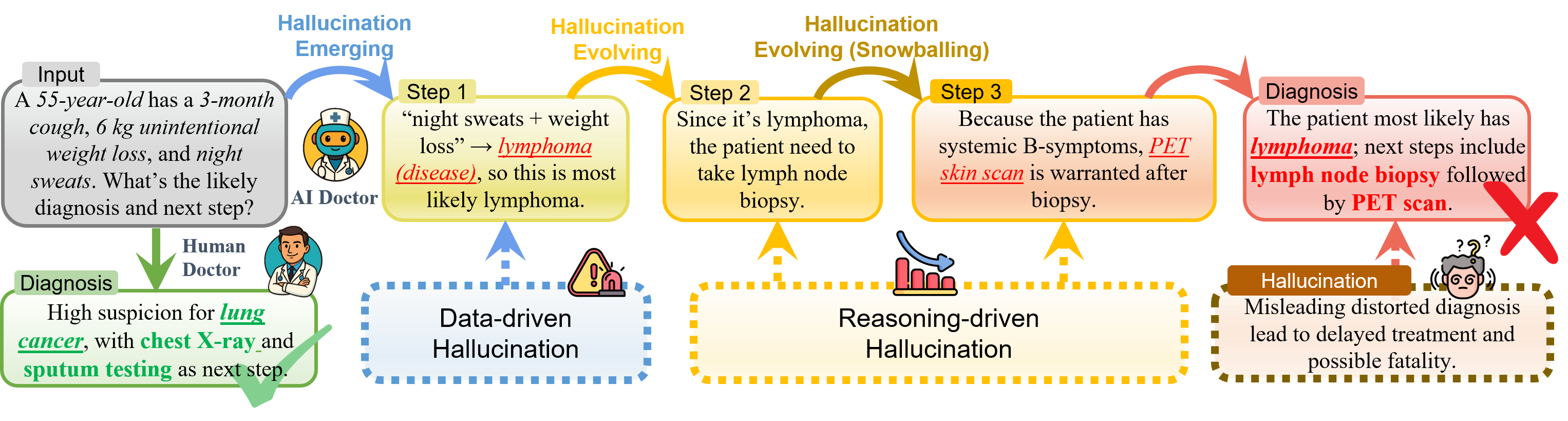
问题定义:现有LLM幻觉检测方法存在局限性,主要体现在两个方面:一是通常只针对数据驱动或推理驱动的幻觉中的一种,无法全面覆盖;二是依赖于特定任务的启发式规则,泛化能力较差,难以应对复杂场景。因此,需要一种更通用、更有效的幻觉检测方法。
核心思路:HalluGuard的核心思路是利用神经切核(NTK)的几何特性来同时识别数据驱动和推理驱动的幻觉。NTK能够捕捉模型在训练过程中学习到的数据表示和推理模式,通过分析NTK的几何结构,可以判断模型在推理时是否偏离了训练数据的分布,从而检测出幻觉。
技术框架:HalluGuard的技术框架主要包括以下几个阶段:1) 利用LLM生成文本;2) 计算该文本对应的NTK矩阵;3) 基于NTK矩阵计算HalluGuard分数,该分数反映了文本中出现幻觉的风险;4) 根据HalluGuard分数判断文本是否存在幻觉。
关键创新:HalluGuard的关键创新在于提出了一个统一的理论框架,将幻觉风险分解为数据驱动和推理驱动两个组成部分,并利用NTK的几何特性来同时检测这两种类型的幻觉。与现有方法相比,HalluGuard不需要依赖于特定任务的启发式规则,具有更好的泛化能力。
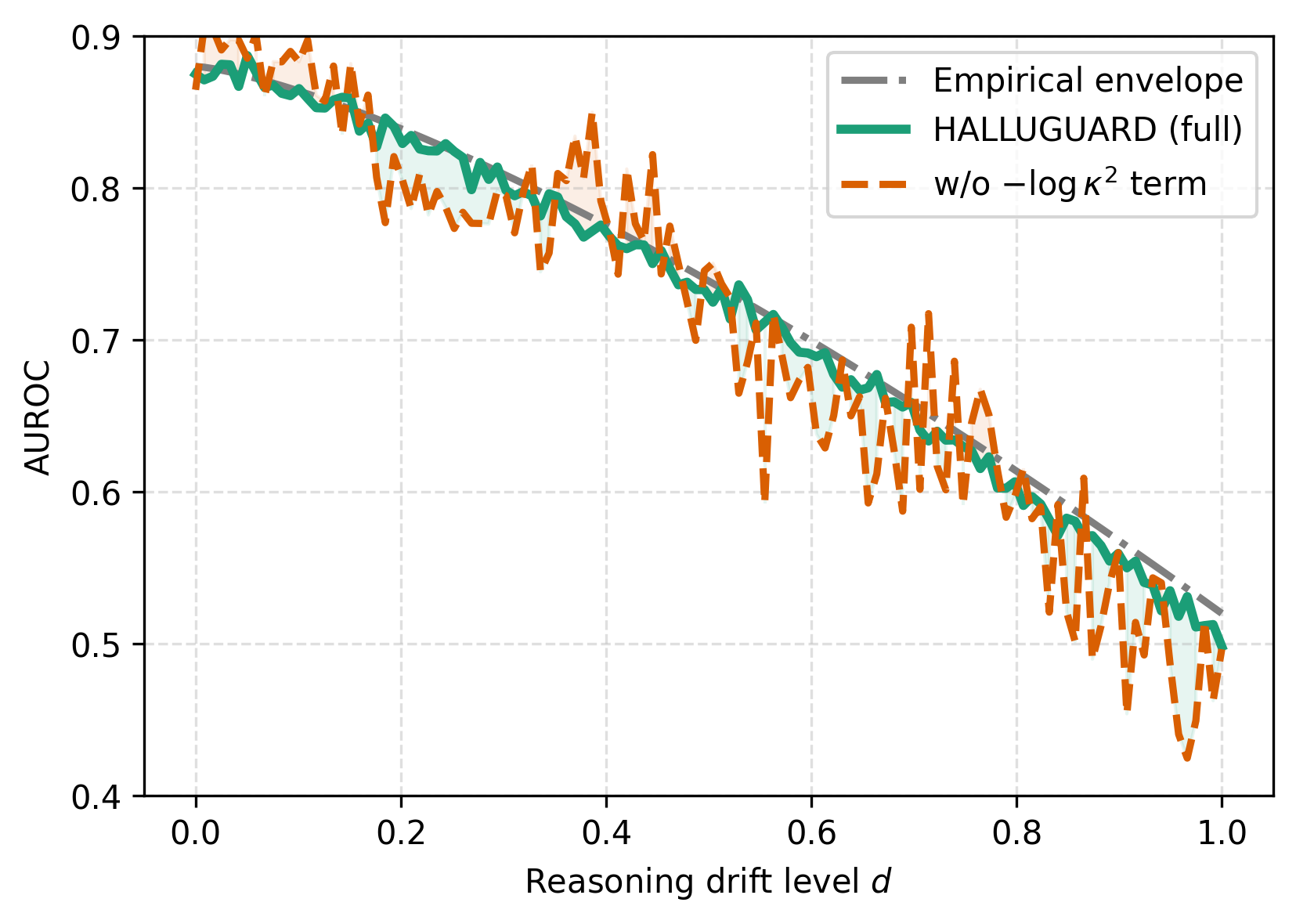
关键设计:HalluGuard的关键设计包括:1) Hallucination Risk Bound:一个理论框架,用于分解幻觉风险;2) NTK-based score:基于NTK矩阵计算的幻觉风险评分,用于衡量文本中出现幻觉的可能性。具体来说,HalluGuard分数基于NTK矩阵的特征值和特征向量计算,通过分析这些特征值和特征向量的分布,可以判断模型在推理时是否偏离了训练数据的分布。
🖼️ 关键图片
📊 实验亮点
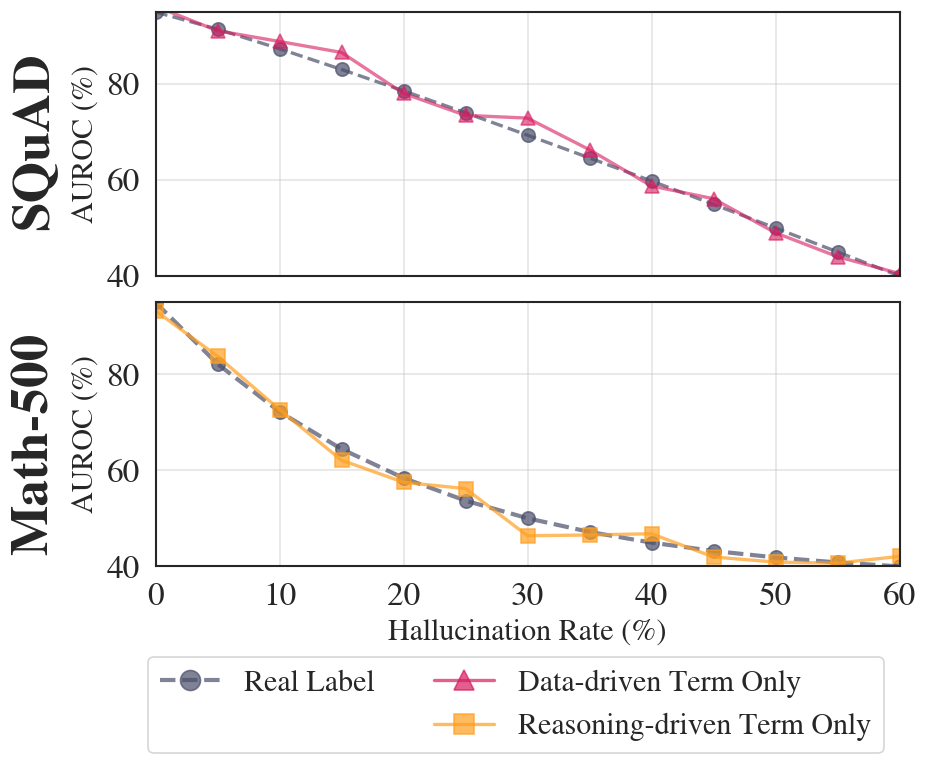
HalluGuard在10个不同的基准测试中,超越了11个有竞争力的基线模型,并在9个流行的LLM骨干网络上取得了SOTA性能。实验结果表明,HalluGuard能够有效检测各种类型的LLM幻觉,并且具有良好的泛化能力。具体性能数据未知,但论文强调了其一致性地超越了现有方法。
🎯 应用场景
HalluGuard可应用于各种需要LLM提供可靠信息的场景,如医疗诊断、法律咨询、科学研究等。通过检测和减少LLM的幻觉,可以提高其在这些领域的应用价值,并避免因错误信息造成的潜在风险。未来,该技术有望集成到LLM的开发和部署流程中,成为保障LLM可靠性的重要工具。
📄 摘要(原文)
The reliability of Large Language Models (LLMs) in high-stakes domains such as healthcare, law, and scientific discovery is often compromised by hallucinations. These failures typically stem from two sources: data-driven hallucinations and reasoning-driven hallucinations. However, existing detection methods usually address only one source and rely on task-specific heuristics, limiting their generalization to complex scenarios. To overcome these limitations, we introduce the Hallucination Risk Bound, a unified theoretical framework that formally decomposes hallucination risk into data-driven and reasoning-driven components, linked respectively to training-time mismatches and inference-time instabilities. This provides a principled foundation for analyzing how hallucinations emerge and evolve. Building on this foundation, we introduce HalluGuard, an NTK-based score that leverages the induced geometry and captured representations of the NTK to jointly identify data-driven and reasoning-driven hallucinations. We evaluate HalluGuard on 10 diverse benchmarks, 11 competitive baselines, and 9 popular LLM backbones, consistently achieving state-of-the-art performance in detecting diverse forms of LLM hallucinations.