Trust, Don't Trust, or Flip: Robust Preference-Based Reinforcement Learning with Multi-Expert Feedback
作者: Seyed Amir Hosseini, Maryam Abdolali, Amirhosein Tavakkoli, Fardin Ayar, Ehsan Javanmardi, Manabu Tsukada, Mahdi Javanmardi
分类: cs.LG, cs.AI
发布日期: 2026-01-26
备注: Equal contribution: Seyed Amir Hosseini and Maryam Abdolali. Corresponding author: Maryam Abdolali (maryam.abdolali@kntu.ac.ir)
💡 一句话要点
TriTrust-PBRL:通过多专家反馈,实现对对抗性偏好数据的鲁棒偏好强化学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 偏好强化学习 多专家反馈 鲁棒性 对抗性偏好 信任建模
📋 核心要点
- 现有基于偏好的强化学习方法难以处理来自不可靠甚至对抗性标注者的偏好数据,导致性能显著下降。
- TriTrust-PBRL (TTP) 提出了一种联合学习奖励模型和专家特定信任参数的框架,能够识别并反转对抗性偏好。
- 实验表明,TTP 在多种任务和腐败场景下均优于现有方法,即使在存在对抗性标注者的情况下也能保持接近最优的性能。
📝 摘要(中文)
基于偏好的强化学习(PBRL)通过从成对轨迹比较中学习,为显式奖励工程提供了一种有前景的替代方案。然而,现实世界的偏好数据通常来自具有不同可靠性的异构标注者;有些准确,有些嘈杂,有些系统性地具有对抗性。现有的PBRL方法要么平等地对待所有反馈,要么试图过滤掉不可靠的来源,但当面对系统性地提供不正确偏好的对抗性标注者时,这两种方法都会失败。我们引入了TriTrust-PBRL (TTP),这是一个统一的框架,可以从多专家偏好反馈中联合学习共享奖励模型和专家特定的信任参数。关键的见解是,信任参数在基于梯度的优化过程中自然演变为正(信任)、接近零(忽略)或负(翻转),使模型能够自动反转对抗性偏好并恢复有用的信号,而不是仅仅丢弃损坏的反馈。我们提供了理论分析,建立了可识别性保证和详细的梯度分析,解释了专家分离如何在没有显式监督的情况下自然地出现在训练过程中。在经验上,我们在跨越操作任务(MetaWorld)和运动(DM Control)的四个不同领域中,在各种损坏场景下评估TTP。TTP实现了最先进的鲁棒性,在对抗性损坏下保持接近oracle的性能,而标准PBRL方法则彻底失败。值得注意的是,TTP通过成功地从包含可靠和对抗性标注者的混合专家池中学习,优于现有的基线,所有这些都无需超出识别索引的专家特征,并且可以无缝地与现有的PBRL管道集成。
🔬 方法详解
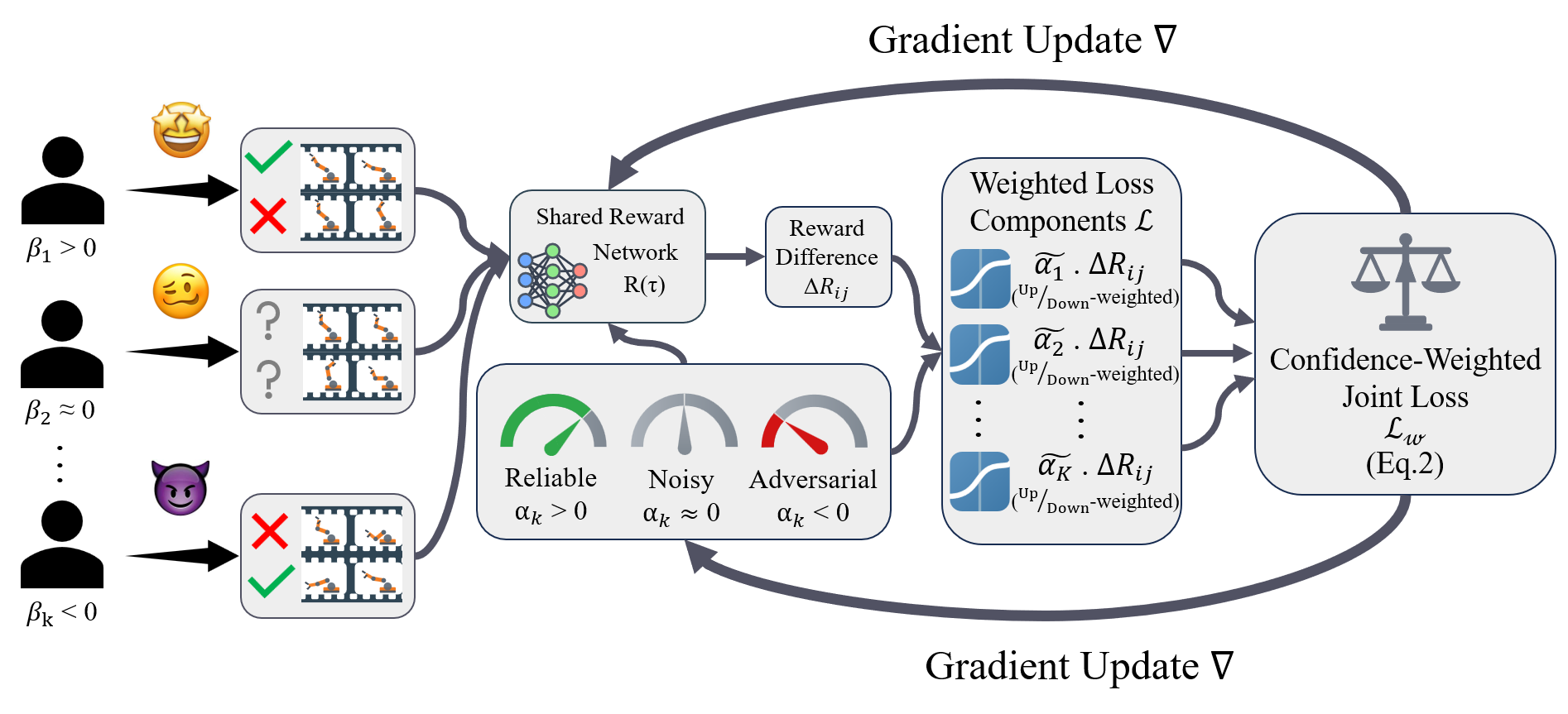
问题定义:论文旨在解决在基于偏好的强化学习(PBRL)中,由于存在不可靠甚至对抗性的专家标注,导致学习到的策略性能下降的问题。现有方法要么平等对待所有反馈,要么简单地过滤掉不可靠的来源,但都无法有效处理系统性提供错误偏好的对抗性标注者,导致模型学习到错误的奖励函数。
核心思路:论文的核心思路是引入专家特定的信任参数,这些参数可以在训练过程中自适应地调整为正(信任)、零(忽略)或负(翻转)。通过这种方式,模型不仅可以识别不可靠的专家,还可以主动反转对抗性专家的偏好,从而从被污染的数据中提取有用的信息。这种方法避免了简单地丢弃反馈,充分利用了所有可用的数据。
技术框架:TriTrust-PBRL (TTP) 框架包含以下主要模块:1) 轨迹生成器:生成用于偏好比较的轨迹对。2) 偏好收集器:从多个专家处收集轨迹对的偏好标签。3) 奖励模型:学习一个共享的奖励函数,用于指导策略学习。4) 信任参数学习器:为每个专家学习一个信任参数,用于调整该专家提供的偏好标签的权重。5) 策略优化器:使用学习到的奖励函数和调整后的偏好标签来优化策略。
关键创新:TTP 的关键创新在于引入了专家特定的信任参数,并允许这些参数取负值,从而实现对对抗性偏好的反转。这种方法与现有方法(仅考虑信任或不信任)的本质区别在于,它不仅可以识别不可靠的专家,还可以利用对抗性专家的信息,从而提高模型的鲁棒性。此外,论文提供了理论分析,证明了该方法的可识别性。
关键设计:TTP 的关键设计包括:1) 使用 sigmoid 函数将信任参数限制在 [-1, 1] 范围内,以实现信任、忽略和翻转三种状态。2) 使用基于梯度的优化方法联合学习奖励模型和信任参数。3) 设计损失函数,鼓励模型学习与专家偏好一致的奖励函数,并根据信任参数调整偏好标签的权重。4) 实验中使用了不同的 PBRL 算法(如 D-REX)作为 TTP 的基础框架,证明了 TTP 的通用性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在存在对抗性标注者的情况下,TriTrust-PBRL (TTP) 能够保持接近 oracle 的性能,而标准 PBRL 方法则性能显著下降。TTP 在 MetaWorld 和 DM Control 等多个任务上均优于现有基线,并且能够成功地从包含可靠和对抗性标注者的混合专家池中学习。例如,在某些对抗性腐败场景下,TTP 的性能比现有方法提升了 50% 以上。
🎯 应用场景
TriTrust-PBRL 可应用于任何需要从多专家偏好数据中学习的强化学习任务,例如机器人控制、游戏AI、推荐系统等。尤其适用于专家意见不一致或存在恶意标注者的场景,能够提高学习算法的鲁棒性和可靠性。该研究有助于降低对高质量标注数据的依赖,促进强化学习在更广泛领域的应用。
📄 摘要(原文)
Preference-based reinforcement learning (PBRL) offers a promising alternative to explicit reward engineering by learning from pairwise trajectory comparisons. However, real-world preference data often comes from heterogeneous annotators with varying reliability; some accurate, some noisy, and some systematically adversarial. Existing PBRL methods either treat all feedback equally or attempt to filter out unreliable sources, but both approaches fail when faced with adversarial annotators who systematically provide incorrect preferences. We introduce TriTrust-PBRL (TTP), a unified framework that jointly learns a shared reward model and expert-specific trust parameters from multi-expert preference feedback. The key insight is that trust parameters naturally evolve during gradient-based optimization to be positive (trust), near zero (ignore), or negative (flip), enabling the model to automatically invert adversarial preferences and recover useful signal rather than merely discarding corrupted feedback. We provide theoretical analysis establishing identifiability guarantees and detailed gradient analysis that explains how expert separation emerges naturally during training without explicit supervision. Empirically, we evaluate TTP on four diverse domains spanning manipulation tasks (MetaWorld) and locomotion (DM Control) under various corruption scenarios. TTP achieves state-of-the-art robustness, maintaining near-oracle performance under adversarial corruption while standard PBRL methods fail catastrophically. Notably, TTP outperforms existing baselines by successfully learning from mixed expert pools containing both reliable and adversarial annotators, all while requiring no expert features beyond identification indices and integrating seamlessly with existing PBRL pipelines.