Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
作者: Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, Aditya Grover
分类: cs.LG, cs.CL
发布日期: 2026-01-26
备注: 13 pages
💡 一句话要点
提出On-Policy自蒸馏框架,提升大语言模型在数学推理任务上的token效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自蒸馏 On-Policy学习 知识蒸馏 大语言模型 数学推理
📋 核心要点
- 现有On-policy蒸馏依赖独立的教师模型,且未充分利用推理数据集中已有的正确推理过程。
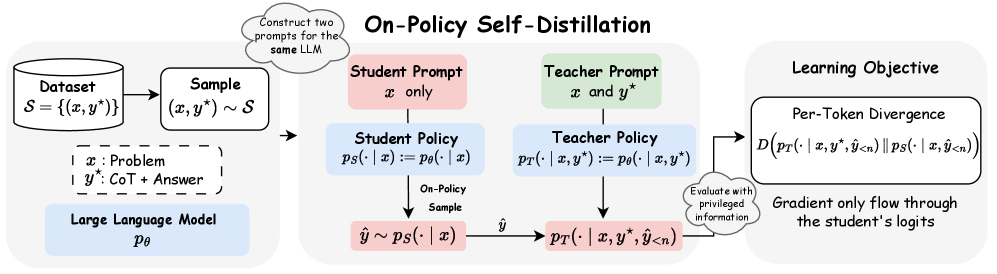
- 论文提出On-Policy Self-Distillation (OPSD)框架,单一模型通过不同上下文充当教师和学生。
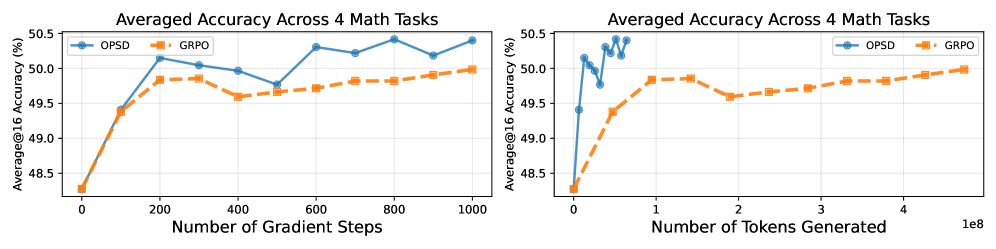
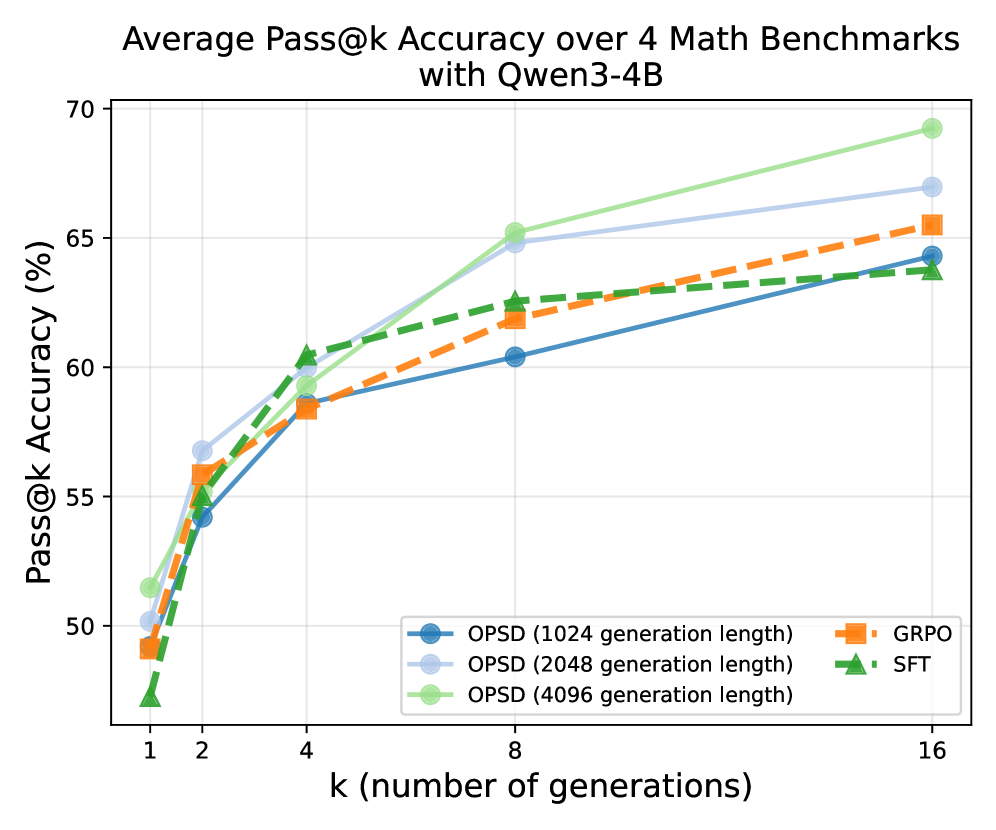
- 实验表明,OPSD在数学推理任务上,相比强化学习方法token效率提升4-8倍,优于Off-policy蒸馏。
📝 摘要(中文)
知识蒸馏通过将大型语言模型(LLM)的知识压缩到较小的LLM中来提高LLM的推理能力。On-policy蒸馏通过让学生模型采样自己的轨迹,同时教师LLM提供密集的token级别监督,从而改进了这种方法,解决了off-policy蒸馏方法中训练和推理之间的分布不匹配问题。然而,on-policy蒸馏通常需要一个单独的、通常更大的教师LLM,并且没有明确地利用推理数据集中可用的ground-truth解决方案。受到足够强大的LLM可以合理化外部特权推理轨迹并教导其较弱的自身(即没有访问特权信息的版本)的直觉的启发,我们引入了On-Policy Self-Distillation(OPSD),这是一个框架,其中单个模型通过调节不同的上下文来充当教师和学生。教师策略以特权信息(例如,经过验证的推理轨迹)为条件,而学生策略仅看到问题;训练最小化学生自身rollout上这些分布之间的每个token的差异。我们在多个数学推理基准上证明了我们方法的有效性,与GRPO等强化学习方法相比,实现了4-8倍的token效率,并且性能优于off-policy蒸馏方法。
🔬 方法详解
问题定义:现有On-policy知识蒸馏方法通常需要一个独立的、通常更大的教师模型,这增加了计算成本和模型复杂性。此外,这些方法通常没有充分利用推理数据集中可用的ground-truth解决方案,导致训练效率低下。因此,需要一种更高效、更有效的知识蒸馏方法,能够利用自身知识和外部信息来提高推理能力。
核心思路:论文的核心思路是让一个足够强大的LLM既充当教师又充当学生,通过调节不同的上下文来实现知识的自我蒸馏。教师策略以特权信息(例如,验证过的推理轨迹)为条件,而学生策略仅看到问题。通过最小化学生自身rollout上教师和学生策略之间的token级别差异,实现知识的传递和模型的改进。
技术框架:OPSD框架包含以下主要步骤:1) 使用LLM作为教师模型,并提供特权信息(例如,正确的推理步骤)。2) 使用同一个LLM作为学生模型,但只提供问题作为输入。3) 学生模型生成自己的推理轨迹(rollout)。4) 计算教师模型和学生模型在每个token上的概率分布差异。5) 使用损失函数(例如,交叉熵)最小化这些差异,从而训练学生模型。
关键创新:OPSD的关键创新在于使用单一模型同时充当教师和学生,避免了对独立教师模型的依赖。此外,OPSD通过利用特权信息(例如,验证过的推理轨迹)来指导学生模型的训练,提高了训练效率和模型性能。这种自蒸馏的方法能够更好地利用模型自身的知识和外部信息,从而提高推理能力。
关键设计:OPSD的关键设计包括:1) 使用交叉熵损失函数来衡量教师模型和学生模型之间的token级别差异。2) 通过控制教师模型和学生模型的输入上下文来调节它们的行为。3) 使用rollout方法生成学生模型的推理轨迹。4) 实验中使用了多个数学推理基准数据集来评估OPSD的性能。具体的参数设置和网络结构信息在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OPSD在多个数学推理基准上取得了显著的性能提升。与强化学习方法(如GRPO)相比,OPSD实现了4-8倍的token效率。此外,OPSD的性能也优于off-policy蒸馏方法,证明了其在知识蒸馏方面的有效性。具体的性能数据和对比基线需要在论文中查找(未知)。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、自然语言理解等。通过自蒸馏,可以训练出更小、更高效的LLM,降低部署成本,并提升在资源受限设备上的推理性能。未来,该方法有望扩展到其他类型的任务和模型,进一步推动LLM在实际应用中的普及。
📄 摘要(原文)
Knowledge distillation improves large language model (LLM) reasoning by compressing the knowledge of a teacher LLM to train smaller LLMs. On-policy distillation advances this approach by having the student sample its own trajectories while a teacher LLM provides dense token-level supervision, addressing the distribution mismatch between training and inference in off-policy distillation methods. However, on-policy distillation typically requires a separate, often larger, teacher LLM and does not explicitly leverage ground-truth solutions available in reasoning datasets. Inspired by the intuition that a sufficiently capable LLM can rationalize external privileged reasoning traces and teach its weaker self (i.e., the version without access to privileged information), we introduce On-Policy Self-Distillation (OPSD), a framework where a single model acts as both teacher and student by conditioning on different contexts. The teacher policy conditions on privileged information (e.g., verified reasoning traces) while the student policy sees only the question; training minimizes the per-token divergence between these distributions over the student's own rollouts. We demonstrate the efficacy of our method on multiple mathematical reasoning benchmarks, achieving 4-8x token efficiency compared to reinforcement learning methods such as GRPO and superior performance over off-policy distillation methods.