Mechanistic Analysis of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
作者: Olaf Yunus Laitinen Imanov
分类: cs.LG, cs.CL
发布日期: 2026-01-26
备注: 16 pages, 16 figures (6 main + 10 supplementary)
💡 一句话要点
揭示大语言模型持续微调中灾难性遗忘的内在机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灾难性遗忘 持续学习 大语言模型 微调 梯度干扰 表征漂移 注意力机制
📋 核心要点
- 大型语言模型在持续学习中面临灾难性遗忘问题,即新任务的学习会损害先前学习的知识,现有方法对此现象的内在机制理解不足。
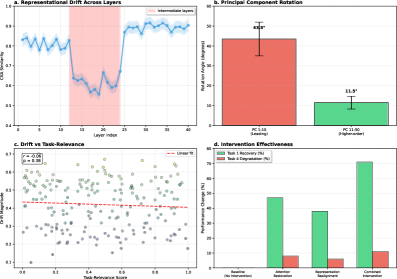
- 该研究通过系统实验,从梯度干扰、表征漂移和损失景观变化三个方面,揭示了灾难性遗忘的内在机制。
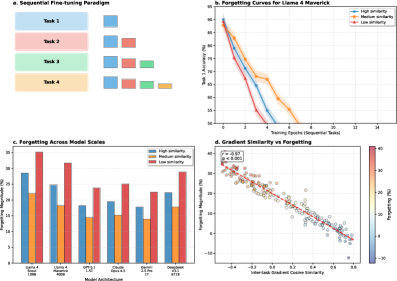
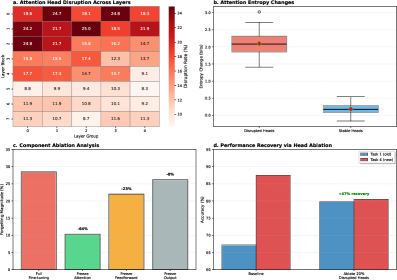
- 实验结果表明,遗忘程度与任务相似性高度相关,且注意力机制中的部分神经元在微调中受到严重干扰,为后续研究提供了重要依据。
📝 摘要(中文)
大型语言模型通过预训练和微调在各种任务中表现出卓越的性能。然而,在顺序任务上持续微调会导致灾难性遗忘,即新获得的知识会干扰先前学习的能力。尽管这种现象已被广泛观察到,但对其内在机制的理解仍然有限。本文对基于Transformer的LLM在顺序微调过程中出现的灾难性遗忘进行了全面的机制分析。通过跨多个模型规模(109B到400B总参数)和任务序列的系统实验,我们确定了驱动遗忘的三个主要机制:注意力权重中的梯度干扰、中间层的表征漂移以及损失景观的扁平化。我们证明了遗忘的严重程度与任务相似性(Pearson r = 0.87)和梯度对齐指标密切相关。我们的分析表明,大约15%到23%的注意力头在微调过程中经历了严重的破坏,并且较低的层更容易受到影响。这些发现为开发持续学习系统中具有针对性的缓解策略奠定了机制基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在持续微调过程中出现的灾难性遗忘问题。现有方法缺乏对这种现象的内在机制的深入理解,导致难以有效地缓解遗忘。
核心思路:论文的核心思路是通过系统性的实验分析,揭示导致灾难性遗忘的关键因素。具体而言,研究关注梯度干扰、表征漂移和损失景观变化这三个方面,并分析它们与遗忘程度之间的关系。通过量化这些因素的影响,从而为设计更有效的持续学习算法提供理论基础。
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 选择不同规模的Transformer模型(109B到400B参数)。 2. 构建包含多个任务的序列,用于持续微调。 3. 在微调过程中,监测和量化注意力权重中的梯度干扰、中间层的表征漂移以及损失景观的扁平化程度。 4. 分析这些因素与遗忘程度之间的相关性。 5. 识别在微调过程中受到严重干扰的注意力头。
关键创新:该研究的关键创新在于对灾难性遗忘现象进行了深入的机制分析,并量化了不同因素对遗忘程度的影响。与以往的研究主要关注缓解遗忘的算法设计不同,该研究侧重于理解遗忘的根本原因,从而为更有针对性的算法设计提供指导。
关键设计:研究中关键的设计包括: 1. 使用不同规模的模型,以验证结论的普适性。 2. 设计具有不同相似度的任务序列,以分析任务相似性对遗忘的影响。 3. 使用Pearson相关系数来量化任务相似性与遗忘程度之间的关系。 4. 定义梯度对齐指标,以量化梯度干扰的程度。 5. 分析不同层中注意力头的变化情况,以识别容易受到干扰的层。
🖼️ 关键图片
📊 实验亮点
实验结果表明,遗忘的严重程度与任务相似性高度相关(Pearson r = 0.87)。研究还发现,大约15%到23%的注意力头在微调过程中经历了严重的破坏,并且较低的层更容易受到影响。这些发现为理解和缓解灾难性遗忘提供了重要的量化依据。
🎯 应用场景
该研究成果可应用于开发更有效的持续学习算法,提升大型语言模型在不断学习新知识时的性能。例如,可以设计针对性的正则化方法,以减少梯度干扰和表征漂移,从而缓解灾难性遗忘。此外,该研究还可以指导模型架构的设计,例如,通过增强模型的记忆能力来减少遗忘。
📄 摘要(原文)
Large language models exhibit remarkable performance across diverse tasks through pre-training and fine-tuning paradigms. However, continual fine-tuning on sequential tasks induces catastrophic forgetting, where newly acquired knowledge interferes with previously learned capabilities. Despite widespread observations of this phenomenon, the mechanistic understanding remains limited. Here, we present a comprehensive mechanistic analysis of catastrophic forgetting in transformer-based LLMs during sequential fine-tuning. Through systematic experiments across multiple model scales (109B to 400B total parameters) and task sequences, we identify three primary mechanisms driving forgetting: gradient interference in attention weights, representational drift in intermediate layers, and loss landscape flattening. We demonstrate that forgetting severity correlates strongly with task similarity (Pearson r = 0.87) and gradient alignment metrics. Our analysis reveals that approximately 15 to 23 percent of attention heads undergo severe disruption during fine-tuning, with lower layers showing greater susceptibility. These findings establish mechanistic foundations for developing targeted mitigation strategies in continual learning systems.