Learned harmonic mean estimation of the marginal likelihood for multimodal posteriors with flow matching
作者: Alicja Polanska, Jason D. McEwen
分类: stat.ME, astro-ph.IM, cs.LG
发布日期: 2026-01-26
备注: Submitted to 44th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering
💡 一句话要点
提出基于Flow Matching的调和平均估计器,提升多峰后验分布下边缘似然的计算精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘似然估计 贝叶斯模型比较 Flow Matching 连续归一化流 多峰后验分布
📋 核心要点
- 传统边缘似然估计方法在复杂模型和多峰后验分布下计算成本高昂或精度不足。
- 利用Flow Matching构建连续归一化流,作为学习调和平均估计器的内部密度估计器,提升对复杂后验分布的建模能力。
- 实验表明,该方法能够有效处理高维多峰后验分布,无需额外的微调或启发式修改。
📝 摘要(中文)
边缘似然(或贝叶斯证据)是贝叶斯模型比较的关键量,但对于复杂模型,即使在适度维度的参数空间中,其计算也可能具有挑战性。已证明,学习的调和平均估计器仅使用后验样本即可提供准确且稳健的边缘似然估计。它与采样策略无关,这意味着可以使用任何方法获得样本。这使得可以使用最适合该任务的任何采样方法进行边缘似然计算和模型比较。然而,先前用于学习的调和平均的内部密度估计器在处理高度多峰后验时可能会遇到困难。在这项工作中,我们引入了基于Flow Matching的连续归一化流,作为学习的调和平均的内部密度估计的强大架构。我们展示了处理具有挑战性的多峰后验的能力,包括一个20个参数维度的示例,展示了该方法处理复杂后验的能力,而无需对基本分布进行微调或启发式修改。
🔬 方法详解
问题定义:论文旨在解决贝叶斯模型比较中边缘似然难以精确计算的问题,尤其是在后验分布呈现高度多峰特性时。现有的学习调和平均估计器在处理此类复杂后验分布时,其内部密度估计器往往表现不佳,导致边缘似然的估计精度下降。
核心思路:论文的核心思路是利用Flow Matching训练的连续归一化流(CNF)来构建更强大的内部密度估计器。Flow Matching能够学习数据分布与简单先验分布之间的连续变换,从而更好地捕捉复杂后验分布的结构,特别是多峰特性。通过提升内部密度估计器的精度,可以提高学习调和平均估计器对边缘似然的估计精度。
技术框架:整体框架包括以下几个步骤:1) 使用任意采样方法(如MCMC)从后验分布中抽取样本;2) 使用Flow Matching训练一个CNF,使其能够将这些后验样本映射到简单的先验分布(如高斯分布);3) 使用训练好的CNF作为学习调和平均估计器的内部密度估计器,计算边缘似然。
关键创新:最重要的技术创新在于将Flow Matching引入到学习调和平均估计器的内部密度估计中。与传统的密度估计方法相比,Flow Matching能够学习数据分布与简单先验分布之间的连续变换,从而更好地捕捉复杂后验分布的结构,特别是多峰特性。这使得该方法能够处理具有挑战性的多峰后验,而无需对基本分布进行微调或启发式修改。
关键设计:Flow Matching的具体实现细节包括:选择合适的向量场模型(如神经网络),定义合适的损失函数(如最小化向量场与真实速度场的差异),以及选择合适的数值积分方法来求解常微分方程。此外,还需要选择合适的CNF架构,例如使用残差块或注意力机制来提高模型的表达能力。
🖼️ 关键图片
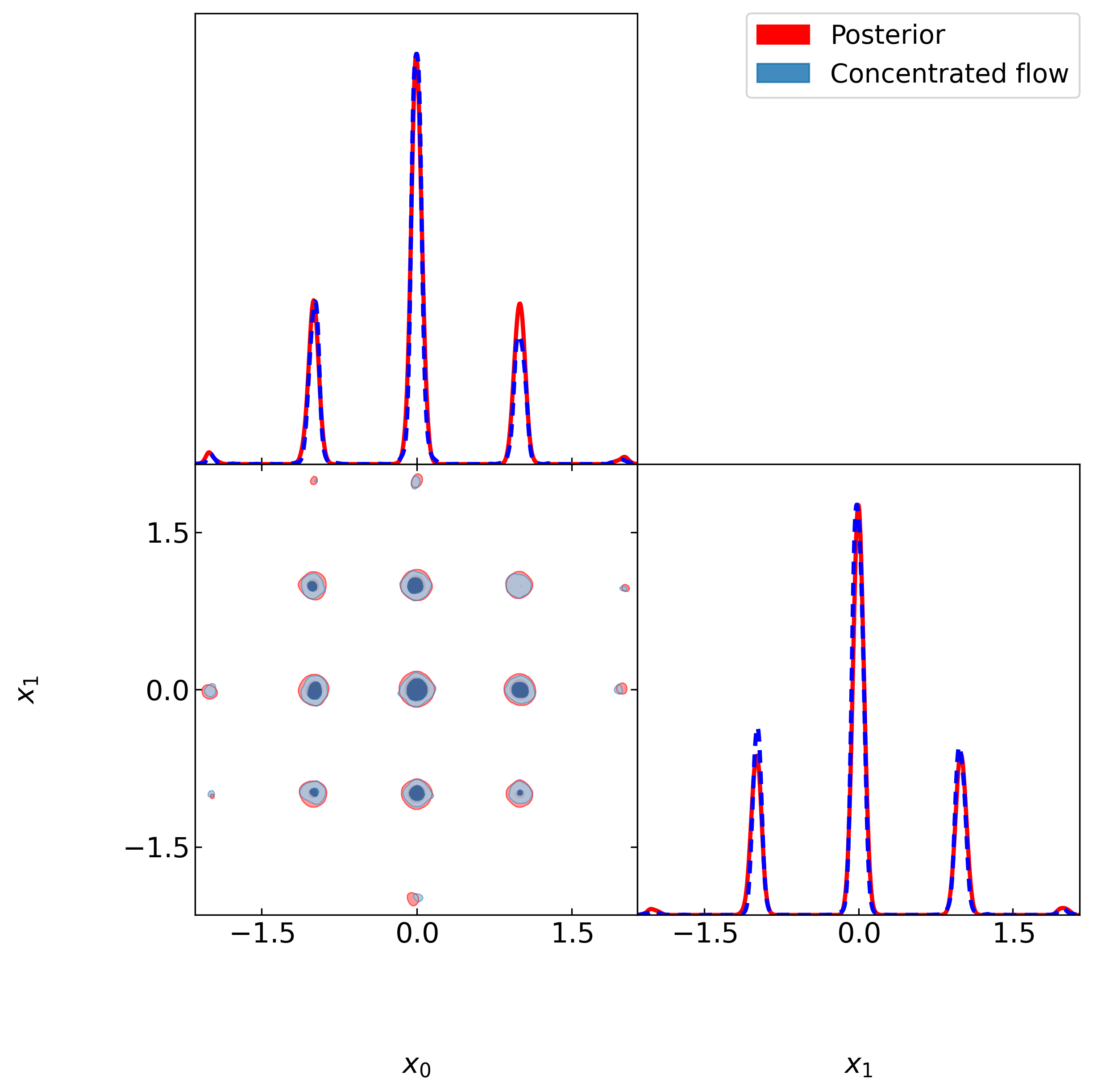

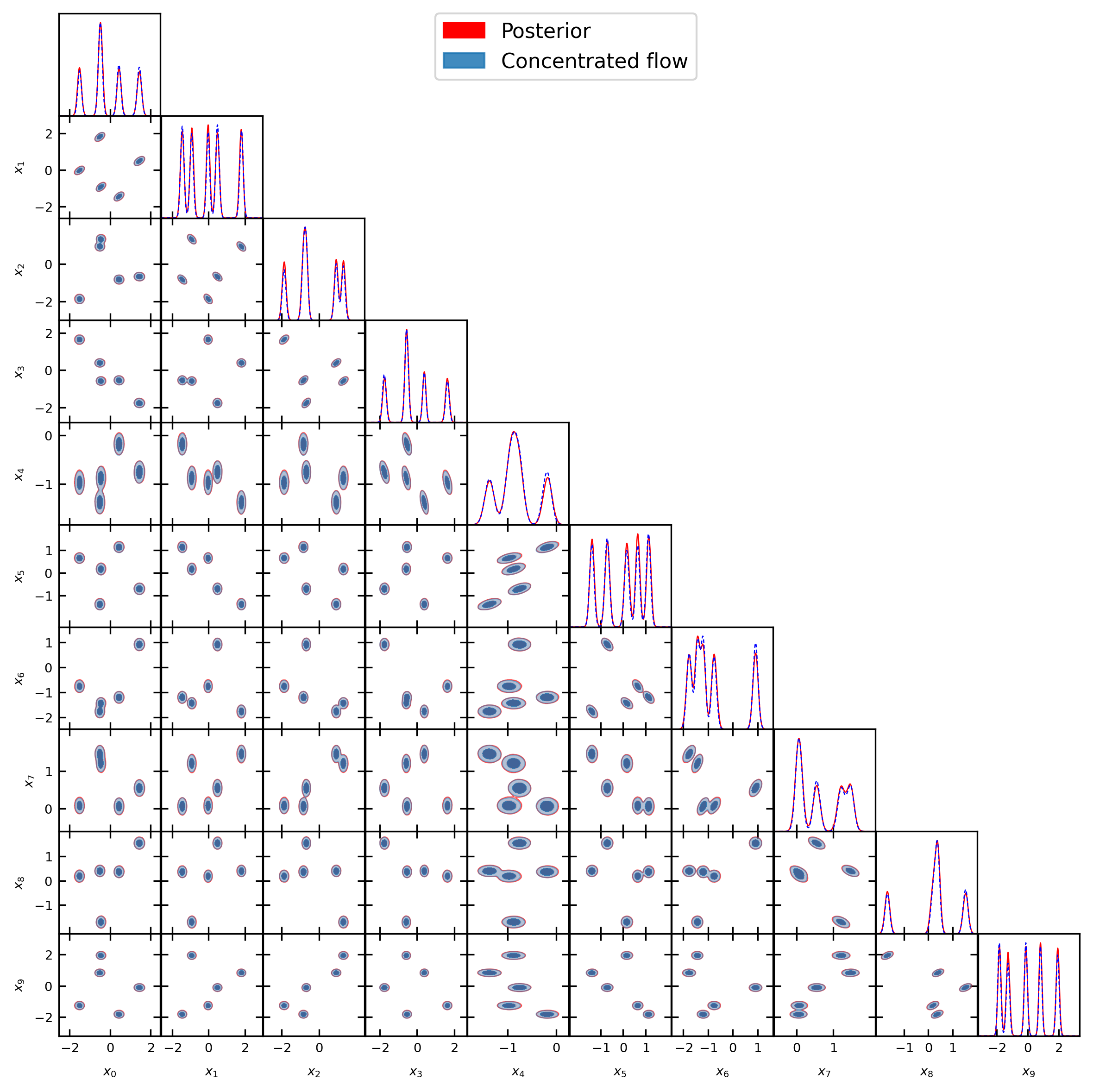
📊 实验亮点
论文通过实验验证了所提出方法的有效性。在包含20个参数维度的复杂多峰后验分布上,该方法能够准确估计边缘似然,无需额外的微调或启发式修改。实验结果表明,基于Flow Matching的调和平均估计器显著优于传统的密度估计方法,能够更准确地捕捉复杂后验分布的结构。
🎯 应用场景
该研究成果可广泛应用于贝叶斯模型选择、超参数优化、以及其他需要精确计算边缘似然的领域。例如,在科学建模中,可以用于比较不同物理模型的优劣;在机器学习中,可以用于选择最佳的模型结构和超参数。该方法能够处理复杂模型和高维数据,具有重要的实际应用价值。
📄 摘要(原文)
The marginal likelihood, or Bayesian evidence, is a crucial quantity for Bayesian model comparison but its computation can be challenging for complex models, even in parameters space of moderate dimension. The learned harmonic mean estimator has been shown to provide accurate and robust estimates of the marginal likelihood simply using posterior samples. It is agnostic to the sampling strategy, meaning that the samples can be obtained using any method. This enables marginal likelihood calculation and model comparison with whatever sampling is most suitable for the task. However, the internal density estimators considered previously for the learned harmonic mean can struggle with highly multimodal posteriors. In this work we introduce flow matching-based continuous normalizing flows as a powerful architecture for the internal density estimation of the learned harmonic mean. We demonstrate the ability to handle challenging multimodal posteriors, including an example in 20 parameter dimensions, showcasing the method's ability to handle complex posteriors without the need for fine-tuning or heuristic modifications to the base distribution.