Rank-1 Approximation of Inverse Fisher for Natural Policy Gradients in Deep Reinforcement Learning
作者: Yingxiao Huo, Satya Prakash Dash, Radu Stoican, Samuel Kaski, Mingfei Sun
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-01-26
💡 一句话要点
提出基于逆Fisher信息矩阵秩-1近似的自然策略梯度方法,加速深度强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 自然策略梯度 Fisher信息矩阵 秩-1近似 策略优化 Actor-Critic 计算效率
📋 核心要点
- 自然梯度方法在深度强化学习中收敛快,但计算Fisher信息矩阵的逆矩阵开销大。
- 论文提出使用秩-1近似来估计逆Fisher信息矩阵,降低计算复杂度,加速策略优化。
- 实验表明,该方法在多个环境中优于标准Actor-Critic和Trust-Region等基线方法。
📝 摘要(中文)
自然梯度因其快速收敛性和协变权重更新特性,在深度强化学习中被广泛研究。然而,计算自然梯度需要在每次迭代时求逆Fisher信息矩阵(FIM),这在计算上是极其昂贵的。本文提出了一种高效且可扩展的自然策略优化技术,该技术利用全逆FIM的秩-1近似。我们从理论上证明,在特定条件下,逆FIM的秩-1近似比策略梯度收敛更快,并且在某些条件下,享有与随机策略梯度方法相同的样本复杂度。我们在各种环境中对我们的方法进行了基准测试,结果表明它比标准的Actor-Critic和Trust-Region基线方法表现更优异。
🔬 方法详解
问题定义:论文旨在解决深度强化学习中自然策略梯度方法计算复杂度过高的问题。自然策略梯度需要计算Fisher信息矩阵(FIM)的逆矩阵,而FIM的计算和求逆在大规模问题中非常耗时,成为应用瓶颈。现有方法通常采用近似方法,但精度和效率仍有提升空间。
核心思路:论文的核心思路是使用秩-1近似来估计逆Fisher信息矩阵。秩-1近似显著降低了计算复杂度,使得自然策略梯度方法能够应用于更大规模的问题。作者通过理论分析证明,在一定条件下,秩-1近似的收敛速度优于传统策略梯度方法,并且在某些情况下具有与随机策略梯度方法相当的样本复杂度。
技术框架:该方法沿用Actor-Critic框架,Actor网络负责策略学习,Critic网络负责价值评估。在Actor更新阶段,使用自然策略梯度,但将完整的逆Fisher信息矩阵替换为其秩-1近似。整体流程包括:1) 收集经验数据;2) 估计Fisher信息矩阵;3) 计算逆Fisher信息矩阵的秩-1近似;4) 使用近似的自然梯度更新Actor网络;5) 更新Critic网络。
关键创新:最关键的创新在于使用秩-1近似来替代完整的逆Fisher信息矩阵。与现有方法相比,该方法在计算效率上具有显著优势,同时在性能上也能达到甚至超过现有方法。这种近似方法在计算复杂度和性能之间取得了更好的平衡。
关键设计:论文中没有明确提及具体的网络结构或损失函数等细节,这些可以根据具体的应用场景进行选择。关键在于如何有效地计算和更新秩-1近似。一种可能的实现方式是使用随机梯度下降等优化算法来最小化秩-1近似与真实逆Fisher信息矩阵之间的差异。此外,还需要仔细选择用于计算Fisher信息矩阵的样本,以保证近似的准确性。论文中可能存在一些未公开的参数设置,这些参数可能对最终性能产生影响(未知)。
🖼️ 关键图片
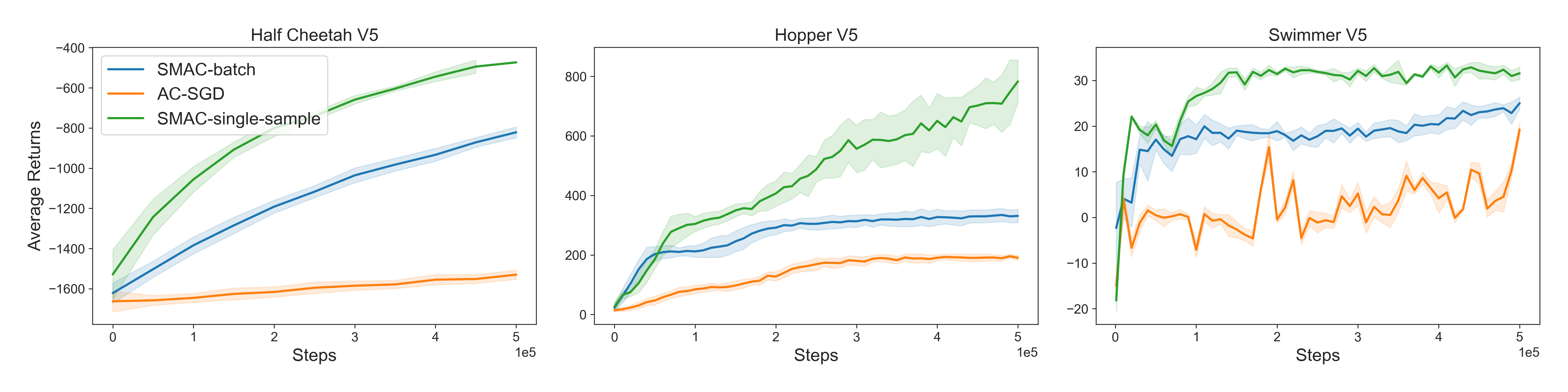
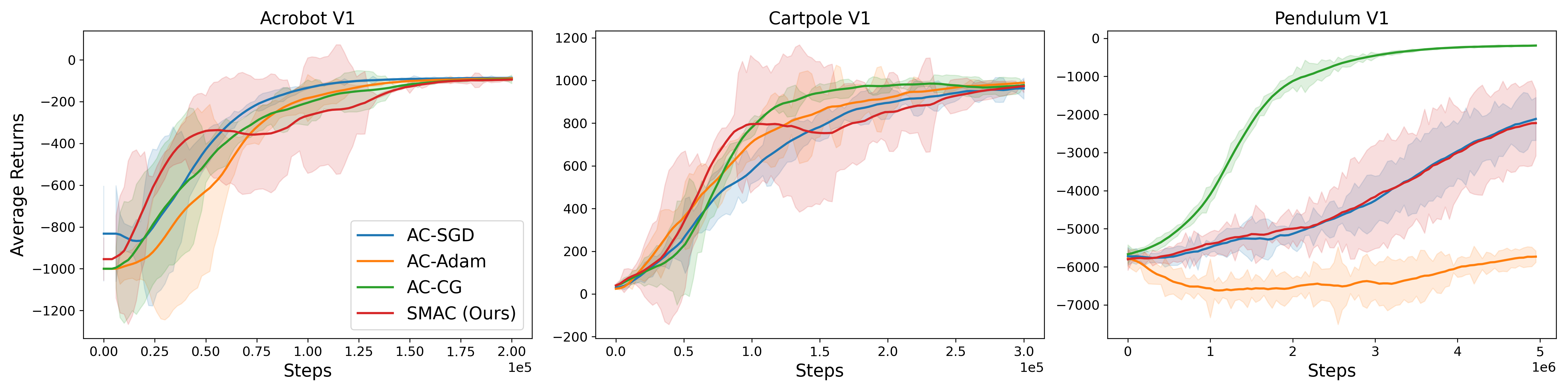
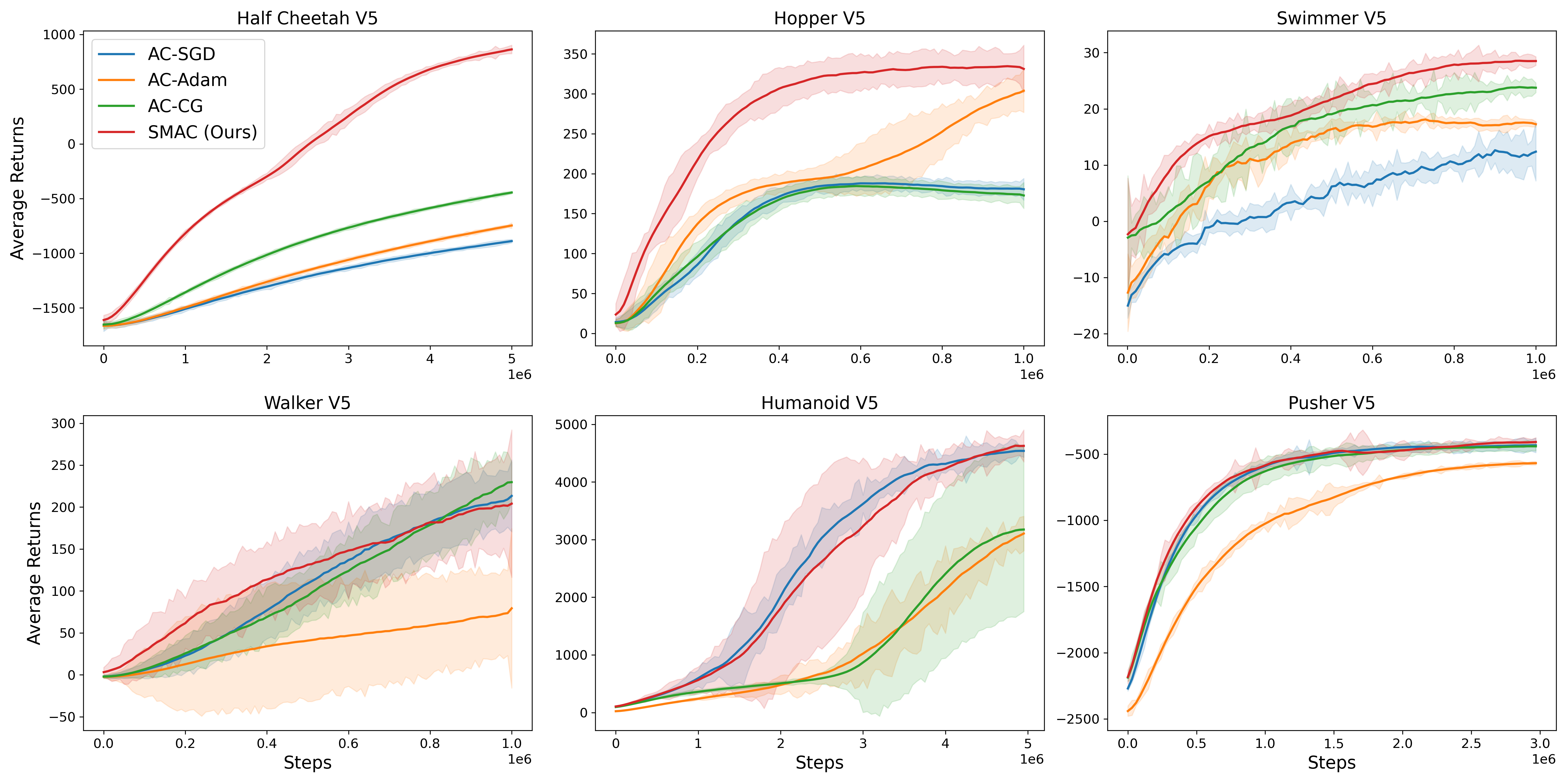
📊 实验亮点
实验结果表明,该方法在多个强化学习环境中(具体环境名称未知)均优于标准的Actor-Critic和Trust-Region基线方法。虽然论文中没有给出具体的性能提升数据,但摘要中明确指出该方法取得了“superior performance”,表明性能提升是显著的。此外,理论分析也支持了该方法在收敛速度和样本复杂度方面的优势。
🎯 应用场景
该研究成果可广泛应用于各种需要高效策略优化的强化学习任务中,例如机器人控制、游戏AI、自动驾驶、推荐系统等。通过降低自然策略梯度的计算复杂度,该方法使得在资源受限的环境中训练复杂的深度强化学习模型成为可能,加速了相关技术的落地和应用。
📄 摘要(原文)
Natural gradients have long been studied in deep reinforcement learning due to their fast convergence properties and covariant weight updates. However, computing natural gradients requires inversion of the Fisher Information Matrix (FIM) at each iteration, which is computationally prohibitive in nature. In this paper, we present an efficient and scalable natural policy optimization technique that leverages a rank-1 approximation to full inverse-FIM. We theoretically show that under certain conditions, a rank-1 approximation to inverse-FIM converges faster than policy gradients and, under some conditions, enjoys the same sample complexity as stochastic policy gradient methods. We benchmark our method on a diverse set of environments and show that it achieves superior performance to standard actor-critic and trust-region baselines.