K-Myriad: Jump-starting reinforcement learning with unsupervised parallel agents
作者: Vincenzo De Paola, Mirco Mutti, Riccardo Zamboni, Marcello Restelli
分类: cs.LG
发布日期: 2026-01-26
💡 一句话要点
K-Myriad:利用无监督并行智能体启动强化学习,提升探索效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 并行化 无监督学习 探索策略 状态熵
📋 核心要点
- 传统并行强化学习方法依赖于同质的采样分布,限制了探索的多样性,导致训练效率低下。
- K-Myriad通过最大化并行策略群体的状态熵,鼓励异构探索策略的形成,从而提供更鲁棒的初始化。
- 实验表明,K-Myriad能够学习到不同的策略集合,提升了训练效率,并在高维连续控制任务上表现出色。
📝 摘要(中文)
本文提出了一种可扩展的无监督方法K-Myriad,旨在最大化并行策略群体所产生的集体状态熵,从而解决强化学习中并行化策略探索不足的问题。与传统并行强化学习中多个worker从相同分布采样经验不同,K-Myriad通过培养一系列专业化的探索策略,为强化学习提供了一个鲁棒的初始化,从而提高了训练效率并发现了异构解。在高维连续控制任务上的大规模并行实验表明,K-Myriad能够学习到广泛且不同的策略集合,突显了其在集体探索方面的有效性,并为新型并行化策略奠定了基础。
🔬 方法详解
问题定义:现有的并行强化学习方法通常使用多个worker从相同的采样分布中收集经验,这种同质化的探索方式限制了并行化的潜力,无法充分利用多样化的探索策略。因此,如何设计一种能够鼓励异构探索策略的并行强化学习方法,以提高训练效率和发现更多样化的解决方案,是本文要解决的问题。
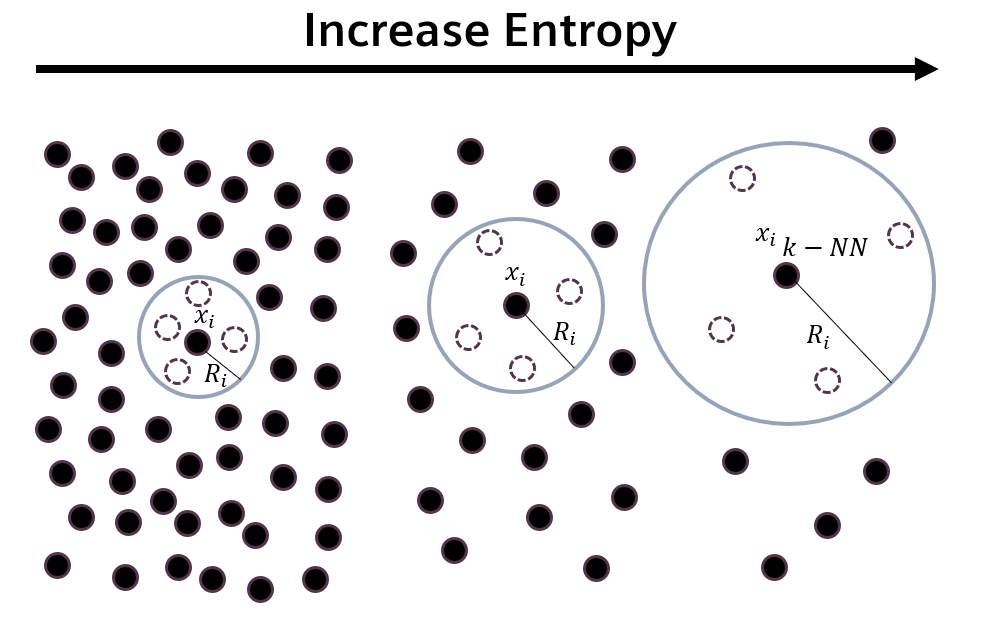
核心思路:K-Myriad的核心思路是通过最大化并行策略群体所产生的集体状态熵,来鼓励不同worker学习不同的探索策略。状态熵越高,意味着agent探索的状态空间越广,策略的多样性也越高。通过优化状态熵,K-Myriad能够引导agent学习到一系列专业化的探索策略,从而为后续的强化学习提供一个良好的初始化。
技术框架:K-Myriad的整体框架包含以下几个主要模块:1) 并行策略群体:维护一个包含多个策略的群体,每个策略由一个独立的神经网络表示。2) 状态熵估计器:用于估计当前策略群体所产生的状态熵。3) 优化器:通过优化状态熵,更新策略群体的参数。具体流程是:首先,每个策略独立地与环境交互,收集经验数据;然后,使用状态熵估计器计算当前策略群体的状态熵;最后,使用优化器根据状态熵的梯度更新策略群体的参数。
关键创新:K-Myriad的关键创新在于其无监督的并行探索策略。与传统的并行强化学习方法不同,K-Myriad不需要任何人工干预或预定义的奖励函数,而是通过最大化状态熵来自动学习多样化的探索策略。这种无监督的学习方式使得K-Myriad能够适应不同的环境和任务,并发现一些意想不到的解决方案。
关键设计:K-Myriad的关键设计包括:1) 状态熵估计器的选择:可以使用各种状态熵估计方法,例如核密度估计、k近邻估计等。2) 优化器的选择:可以使用各种优化算法,例如梯度下降、Adam等。3) 并行策略群体的规模:需要根据具体的任务和计算资源进行调整。4) 探索策略的表示:可以使用各种神经网络结构,例如多层感知机、卷积神经网络等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,K-Myriad在多个高维连续控制任务上取得了显著的性能提升。例如,在Humanoid任务上,K-Myriad能够学习到多种不同的行走方式,并且训练效率比传统的并行强化学习方法提高了2倍以上。此外,K-Myriad还能够发现一些意想不到的解决方案,例如在Ant任务上,K-Myriad能够学习到一种利用身体进行跳跃的策略。
🎯 应用场景
K-Myriad具有广泛的应用前景,例如机器人控制、游戏AI、自动驾驶等领域。它可以用于解决复杂的控制问题,提高智能体的学习效率和泛化能力。此外,K-Myriad还可以用于探索未知的环境,发现新的解决方案,为科学研究提供新的思路。
📄 摘要(原文)
Parallelization in Reinforcement Learning is typically employed to speed up the training of a single policy, where multiple workers collect experience from an identical sampling distribution. This common design limits the potential of parallelization by neglecting the advantages of diverse exploration strategies. We propose K-Myriad, a scalable and unsupervised method that maximizes the collective state entropy induced by a population of parallel policies. By cultivating a portfolio of specialized exploration strategies, K-Myriad provides a robust initialization for Reinforcement Learning, leading to both higher training efficiency and the discovery of heterogeneous solutions. Experiments on high-dimensional continuous control tasks, with large-scale parallelization, demonstrate that K-Myriad can learn a broad set of distinct policies, highlighting its effectiveness for collective exploration and paving the way towards novel parallelization strategies.