Closing the Modality Gap Aligns Group-Wise Semantics
作者: Eleonora Grassucci, Giordano Cicchetti, Emanuele Frasca, Aurelio Uncini, Danilo Comminiello
分类: cs.LG, cs.CV
发布日期: 2026-01-26
备注: ICLR 2026
💡 一句话要点
提出一种对齐组级别语义的方法,缩小多模态学习中的模态差距,提升聚类等组级别任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 模态差距 语义对齐 组级别任务 CLIP 聚类 跨模态检索
📋 核心要点
- 现有基于CLIP的多模态学习方法存在模态差距,导致潜在空间未能完全共享,影响下游任务性能。
- 论文提出一种新方法,旨在缩小多模态学习中的模态差距,特别是在组级别任务中。
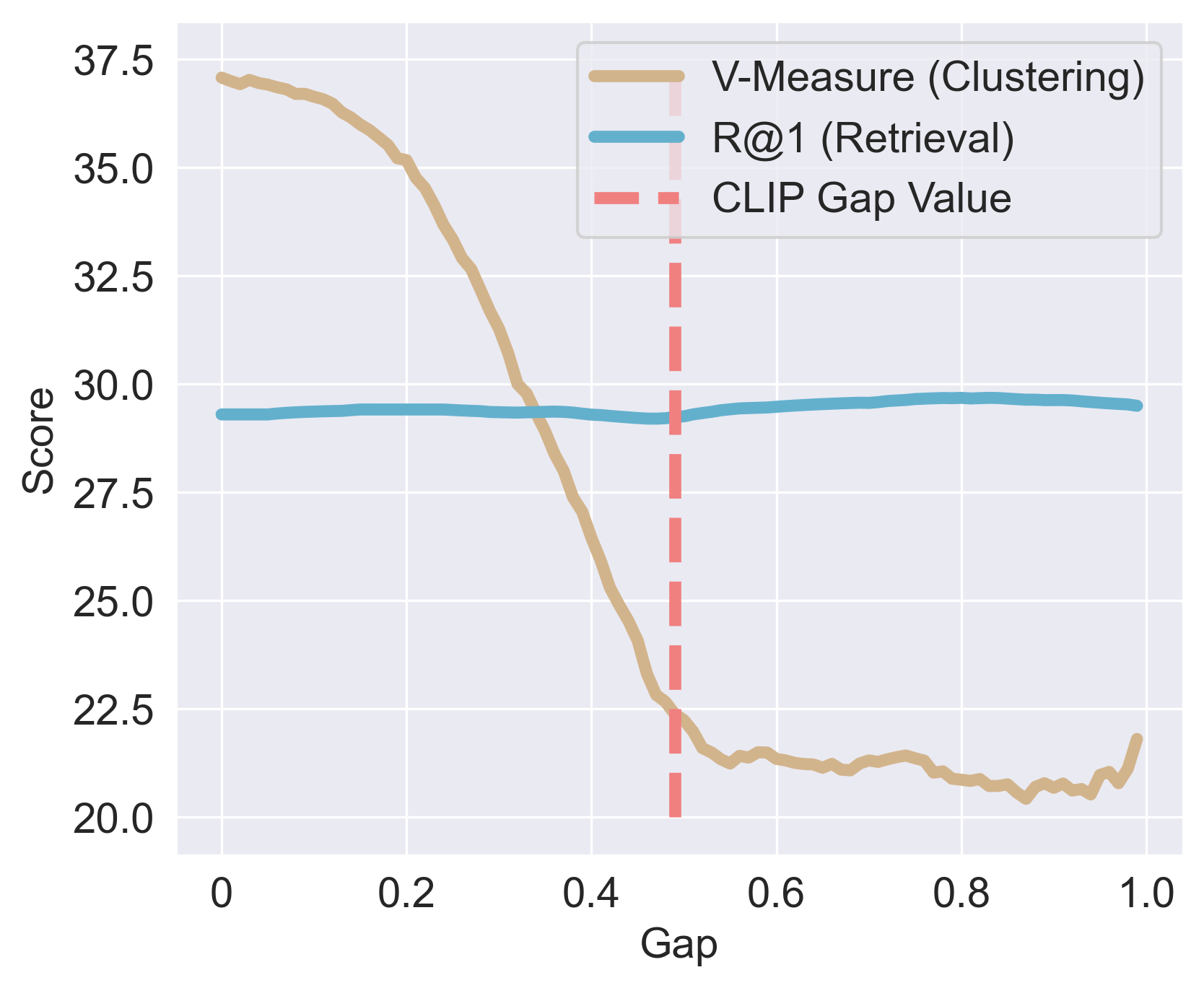
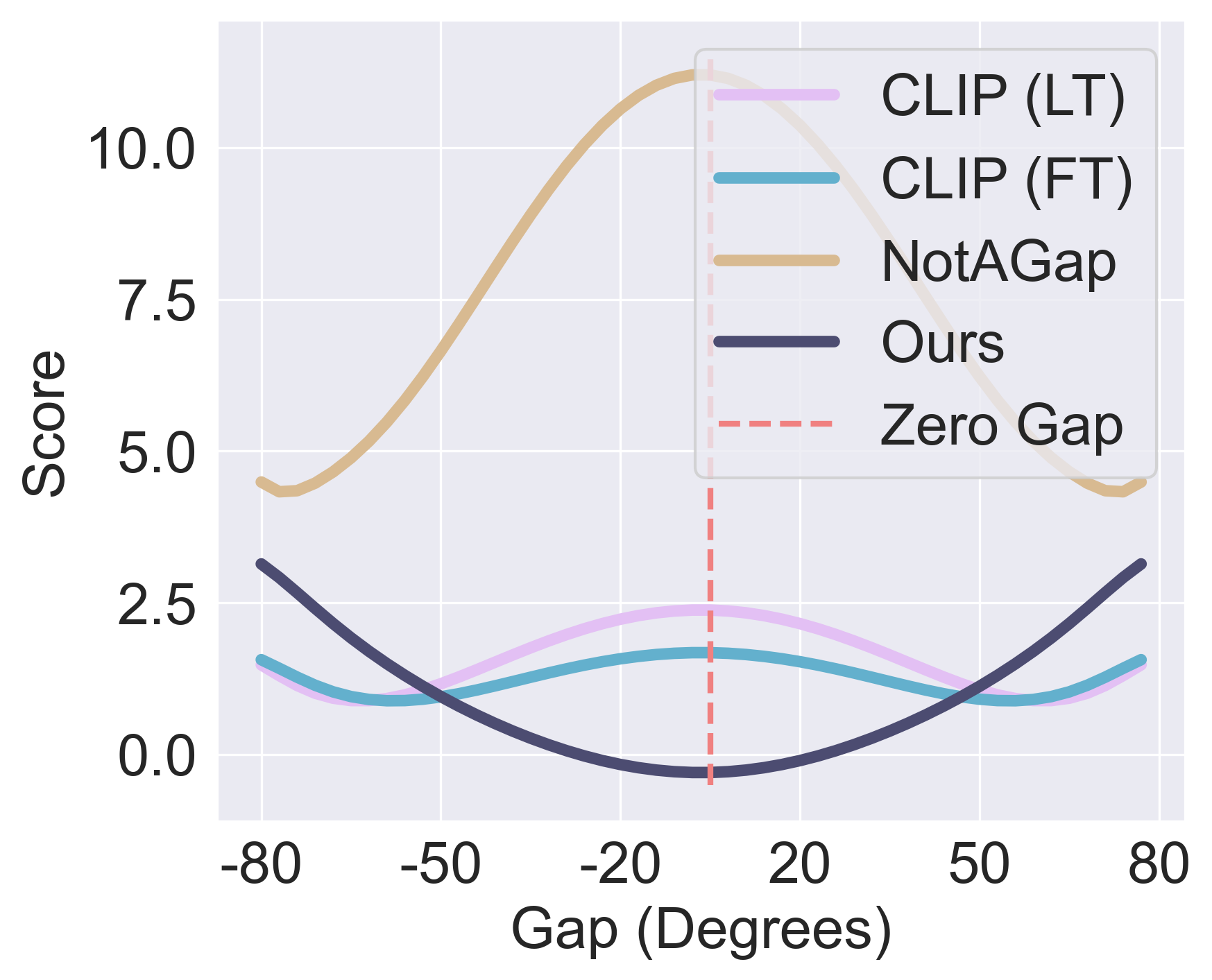
- 实验表明,该方法在实例级任务上提升有限,但在聚类等组级别任务上性能显著提升。
📝 摘要(中文)
在多模态学习中,CLIP已被公认为学习跨多种模态共享潜在空间的实际方法,它将相似的表示放置得更近,并将它们从不相似的表示中移开。虽然基于CLIP的损失有效地在语义级别上对齐模态,但由此产生的潜在空间通常仅部分共享,从而揭示了一种称为模态差距的结构性不匹配。尽管解决这种现象的必要性仍然存在争议,特别是考虑到其对实例级任务(例如,检索)的有限影响,但我们证明了其影响在组级别任务(例如,聚类)中却非常明显。为了支持这一说法,我们引入了一种新方法,旨在持续减少双模态设置中的这种差异,并可直接扩展到一般的$n$模态情况。通过我们广泛的评估,我们证明了我们的新颖见解:虽然缩小差距仅在传统的实例级任务中提供边际或不一致的改进,但它显着增强了组级别任务。这些发现可能会重塑我们对模态差距的理解,突出其在提高需要语义分组的任务的性能方面的关键作用。
🔬 方法详解
问题定义:论文旨在解决多模态学习中存在的模态差距问题。现有基于CLIP的方法虽然能在语义层面对齐不同模态,但模态间的潜在空间仍然存在结构性差异,导致在需要语义分组的组级别任务(如聚类)中表现不佳。现有方法未能充分利用模态间的内在联系,导致信息损失和性能瓶颈。
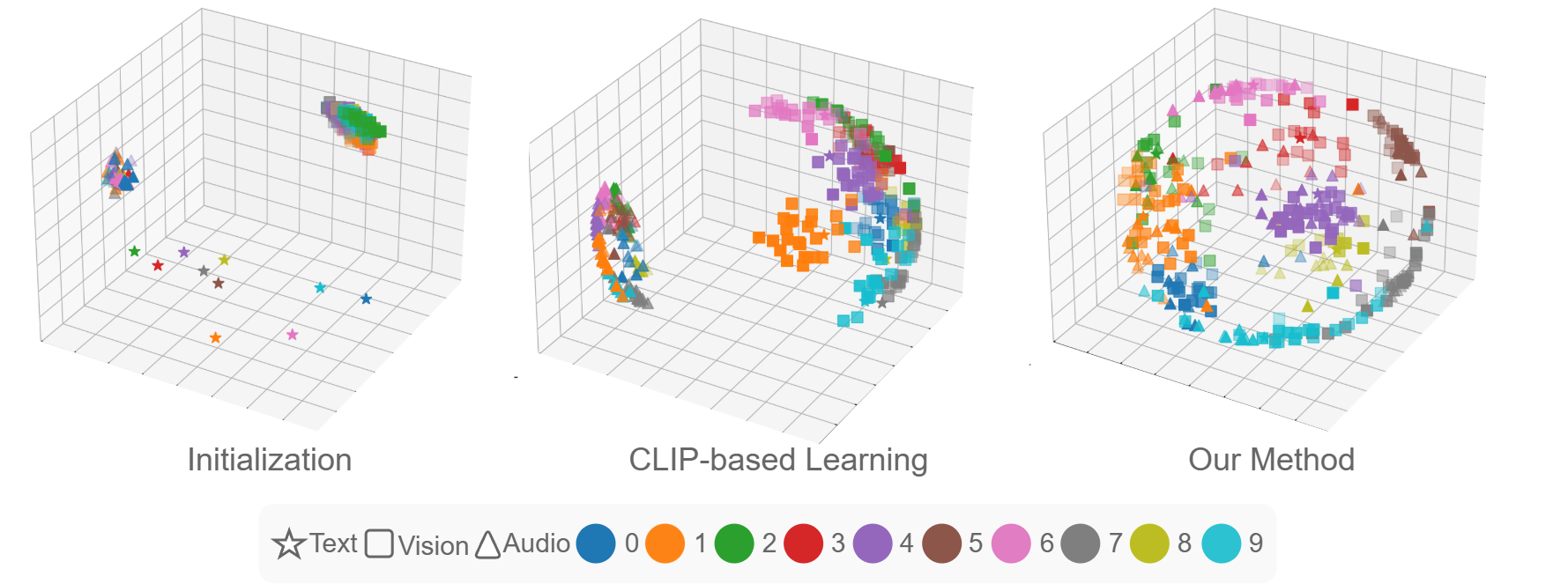
核心思路:论文的核心思路是通过对齐组级别语义来缩小模态差距。具体来说,就是让来自不同模态的、属于同一语义组的样本在潜在空间中更加接近。这种对齐不仅关注实例级别的相似性,更关注组级别的语义一致性,从而更好地利用多模态信息。
技术框架:该方法主要包含以下几个阶段:1) 使用CLIP或其他多模态编码器提取不同模态的特征表示;2) 对特征表示进行分组,例如使用聚类算法;3) 设计损失函数,促使同一组内的不同模态特征表示在潜在空间中更加接近;4) 使用优化算法训练模型,缩小模态差距。该框架可以扩展到处理多个模态的情况。
关键创新:论文的关键创新在于提出了组级别语义对齐的概念,并将其应用于缩小多模态学习中的模态差距。与以往关注实例级别对齐的方法不同,该方法更加关注语义组的整体一致性,从而更好地利用多模态信息,提升组级别任务的性能。
关键设计:论文的关键设计包括:1) 如何定义和提取语义组,例如使用聚类算法或预定义的类别标签;2) 如何设计损失函数,促使同一组内的不同模态特征表示在潜在空间中更加接近,例如可以使用对比损失或三元组损失;3) 如何平衡实例级别对齐和组级别对齐,避免过度优化组级别对齐而损害实例级别的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在组级别任务(如聚类)上取得了显著的性能提升,验证了缩小模态差距对于提升组级别任务性能的重要性。虽然在实例级任务上提升有限,但并未损害原有性能。该方法为多模态学习提供了一种新的思路,有望推动相关领域的发展。
🎯 应用场景
该研究成果可应用于多种需要多模态信息融合和语义分组的场景,例如:多模态医学图像分析(疾病诊断、病灶分割)、跨模态视频理解(事件检测、行为识别)、多模态情感分析(用户画像、舆情监控)等。通过缩小模态差距,可以提升这些应用场景中算法的准确性和鲁棒性,具有重要的实际价值和潜在的应用前景。
📄 摘要(原文)
In multimodal learning, CLIP has been recognized as the \textit{de facto} method for learning a shared latent space across multiple modalities, placing similar representations close to each other and moving them away from dissimilar ones. Although CLIP-based losses effectively align modalities at the semantic level, the resulting latent spaces often remain only partially shared, revealing a structural mismatch known as the modality gap. While the necessity of addressing this phenomenon remains debated, particularly given its limited impact on instance-wise tasks (e.g., retrieval), we prove that its influence is instead strongly pronounced in group-level tasks (e.g., clustering). To support this claim, we introduce a novel method designed to consistently reduce this discrepancy in two-modal settings, with a straightforward extension to the general $n$-modal case. Through our extensive evaluation, we demonstrate our novel insight: while reducing the gap provides only marginal or inconsistent improvements in traditional instance-wise tasks, it significantly enhances group-wise tasks. These findings may reshape our understanding of the modality gap, highlighting its key role in improving performance on tasks requiring semantic grouping.