FGGM: Fisher-Guided Gradient Masking for Continual Learning
作者: Chao-Hong Tan, Qian Chen, Wen Wang, Yukun Ma, Chong Zhang, Chong Deng, Qinglin Zhang, Xiangang Li, Jieping Ye
分类: cs.LG, cs.CL
发布日期: 2026-01-26
备注: Accepted by ICASSP 2026
💡 一句话要点
提出FGGM,利用Fisher信息引导梯度掩码,缓解大语言模型持续学习中的灾难性遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 灾难性遗忘 Fisher信息 梯度掩码 大语言模型
📋 核心要点
- 持续学习中,大模型面临灾难性遗忘问题,现有方法难以在保持旧知识和学习新知识间平衡。
- FGGM利用Fisher信息估计参数重要性,动态生成梯度掩码,选择性更新参数,无需历史数据。
- 实验表明,FGGM在TRACE基准和代码生成任务上,显著优于监督微调和MIGU等方法,有效缓解遗忘。
📝 摘要(中文)
灾难性遗忘阻碍了大语言模型的持续学习。本文提出了一种名为Fisher引导梯度掩码(FGGM)的框架,通过使用对角Fisher信息策略性地选择参数进行更新,从而缓解这一问题。FGGM动态生成具有自适应阈值的二元掩码,保留关键参数,在稳定性和可塑性之间取得平衡,且无需历史数据。与基于幅度的方法(如MIGU)不同,我们的方法提供了一种数学上合理的参数重要性估计。在TRACE基准测试中,FGGM在保持通用能力方面,相对于监督微调(SFT)表现出9.6%的相对改进,相对于TRACE任务上的MIGU表现出4.4%的改进。对代码生成任务的额外分析证实了FGGM的卓越性能和减少的遗忘,证明了它是一种有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决大语言模型在持续学习过程中出现的灾难性遗忘问题。现有方法,如微调,容易覆盖先前学习的知识,导致模型性能下降。基于幅度的方法(如MIGU)虽然尝试保留重要参数,但缺乏数学上的严谨性,参数重要性估计不够准确。
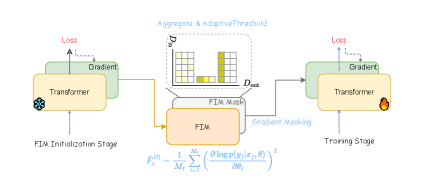
核心思路:FGGM的核心思路是利用Fisher信息来估计模型参数的重要性,并根据重要性对梯度进行掩码,从而在更新模型时优先保留对先前任务重要的参数,同时允许模型学习新任务的知识。这种方法旨在平衡模型的稳定性和可塑性,避免灾难性遗忘。
技术框架:FGGM框架主要包含以下几个步骤:1) 计算每个参数的对角Fisher信息,作为参数重要性的度量。2) 基于Fisher信息,动态生成二元掩码,用于选择性地更新参数。掩码的阈值是自适应的,可以根据任务的难度和模型的学习状态进行调整。3) 在模型训练过程中,只更新掩码允许的参数,而保持其他参数不变。
关键创新:FGGM的关键创新在于使用Fisher信息作为参数重要性的度量,并基于此动态生成梯度掩码。与基于幅度的方法相比,Fisher信息提供了一种数学上更合理的参数重要性估计,能够更准确地识别对先前任务重要的参数。此外,FGGM的掩码阈值是自适应的,可以根据任务的难度和模型的学习状态进行调整,从而更好地平衡模型的稳定性和可塑性。
关键设计:FGGM使用对角Fisher信息矩阵的对角元素作为参数重要性的度量。具体来说,对于每个参数,其Fisher信息等于损失函数对该参数的二阶导数的期望。在实际计算中,可以使用一阶导数的平方来近似二阶导数。掩码的生成方式是:对于每个参数,如果其Fisher信息大于一个阈值,则该参数对应的掩码值为1,否则为0。阈值的选择可以基于一个固定的百分比,例如,保留Fisher信息最高的50%的参数。损失函数采用标准的交叉熵损失函数,没有引入额外的正则化项。
🖼️ 关键图片

📊 实验亮点
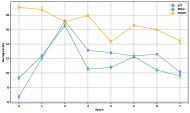
FGGM在TRACE基准测试中,相对于监督微调(SFT)在保持通用能力方面取得了9.6%的相对改进,相对于MIGU取得了4.4%的改进。在代码生成任务上的实验也表明,FGGM能够显著减少灾难性遗忘,并提高模型的生成质量。这些结果表明,FGGM是一种有效的持续学习方法。
🎯 应用场景
FGGM可应用于各种需要持续学习的大语言模型场景,例如:持续学习新语言、持续学习新领域的知识、持续适应用户偏好等。该方法能够提升模型在不断变化的环境中的适应能力,降低维护成本,并为用户提供更个性化的服务。未来,FGGM有望在智能客服、机器翻译、内容生成等领域发挥重要作用。
📄 摘要(原文)
Catastrophic forgetting impairs the continuous learning of large language models. We propose Fisher-Guided Gradient Masking (FGGM), a framework that mitigates this by strategically selecting parameters for updates using diagonal Fisher Information. FGGM dynamically generates binary masks with adaptive thresholds, preserving critical parameters to balance stability and plasticity without requiring historical data. Unlike magnitude-based methods such as MIGU, our approach offers a mathematically principled parameter importance estimation. On the TRACE benchmark, FGGM shows a 9.6% relative improvement in retaining general capabilities over supervised fine-tuning (SFT) and a 4.4% improvement over MIGU on TRACE tasks. Additional analysis on code generation tasks confirms FGGM's superior performance and reduced forgetting, establishing it as an effective solution.