Beyond Retention: Orchestrating Structural Safety and Plasticity in Continual Learning for LLMs
作者: Fei Meng
分类: cs.LG, cs.AI
发布日期: 2026-01-26
💡 一句话要点
提出OSW方法,解决LLM持续学习中结构安全与可塑性的平衡难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 大型语言模型 灾难性遗忘 正交子空间 结构安全 可塑性 经验回放
📋 核心要点
- 现有经验回放方法在LLM持续学习中,对不同类型的任务表现出差异性,在结构化任务上存在负迁移问题。
- 论文提出正交子空间唤醒(OSW)方法,通过正交更新保证先前任务的关键知识结构不受破坏。
- 实验证明OSW在保持新任务可塑性的同时,有效避免了在代码生成等结构化任务上的灾难性遗忘。
📝 摘要(中文)
大型语言模型(LLM)的持续学习面临着平衡稳定性和可塑性的关键挑战。经验回放(ER)是应对灾难性遗忘的标准方法,但其在不同能力上的影响仍未被充分探索。本文揭示了ER行为中的一个关键二分法:它在鲁棒的、非结构化任务上诱导积极的后向迁移(例如,通过重复排练提高先前NLP分类任务的性能),但对脆弱的、结构化领域(如代码生成)造成严重的负向迁移(例如,编码准确性的显著相对下降)。这表明ER以结构完整性换取广泛的巩固。为了解决这个难题,我们提出了正交子空间唤醒(OSW)。OSW通过一个简短的“唤醒”阶段识别先前任务的关键参数子空间,并强制新任务进行正交更新,为已建立的知识结构提供数学上的“安全保证”。在四个任务序列上的实验结果表明,OSW成功地保留了ER失败的脆弱编码能力,同时保持了新任务的高可塑性。我们的研究结果强调了在LLM持续学习中评估结构安全以及平均保留的必要性。
🔬 方法详解
问题定义:大型语言模型在持续学习过程中,如何在学习新任务的同时,保持对先前任务的知识?经验回放(ER)虽然能缓解灾难性遗忘,但会损害某些结构化任务(如代码生成)的性能,导致负迁移。现有方法未能有效区分不同类型任务的特点,并采取针对性的保护措施。
核心思路:论文的核心思路是识别并保护先前任务的关键参数子空间。通过限制新任务的更新方向,使其与先前任务的关键子空间正交,从而避免对先前知识结构的破坏。这种方法旨在在保持模型可塑性的同时,确保结构化知识的安全性。
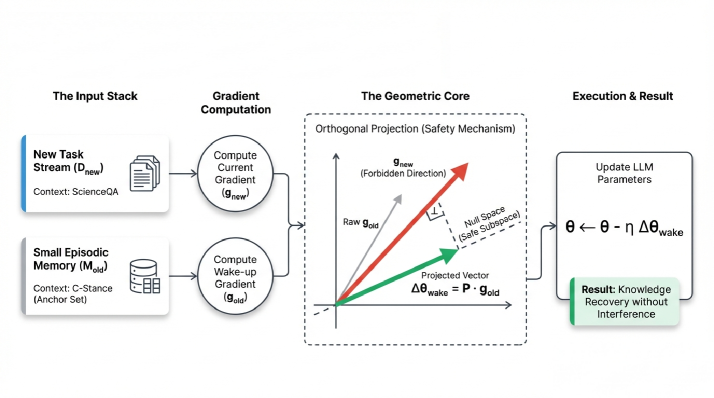
技术框架:OSW方法包含两个主要阶段:1) 唤醒阶段:对于每个先前学习的任务,通过少量数据进行微调,以识别对该任务至关重要的参数子空间。2) 正交更新阶段:在学习新任务时,将参数更新投影到与先前任务的关键子空间正交的子空间中。这样可以确保新任务的更新不会显著改变先前任务的知识。
关键创新:OSW的关键创新在于其正交更新机制,它提供了一种数学上可证明的“安全保证”,确保先前任务的知识结构在学习新任务时不会被破坏。与经验回放等方法相比,OSW能够更精细地控制知识的更新,从而避免负迁移。
关键设计:OSW的关键设计包括:1) 子空间识别:使用少量数据微调先前任务,并计算参数梯度,以确定关键参数子空间。2) 正交投影:使用Gram-Schmidt正交化等方法,将新任务的参数更新投影到与先前任务的关键子空间正交的子空间中。3) 损失函数:可以使用标准的交叉熵损失函数进行训练,同时添加一个正则化项,以鼓励参数更新的正交性。
🖼️ 关键图片
📊 实验亮点
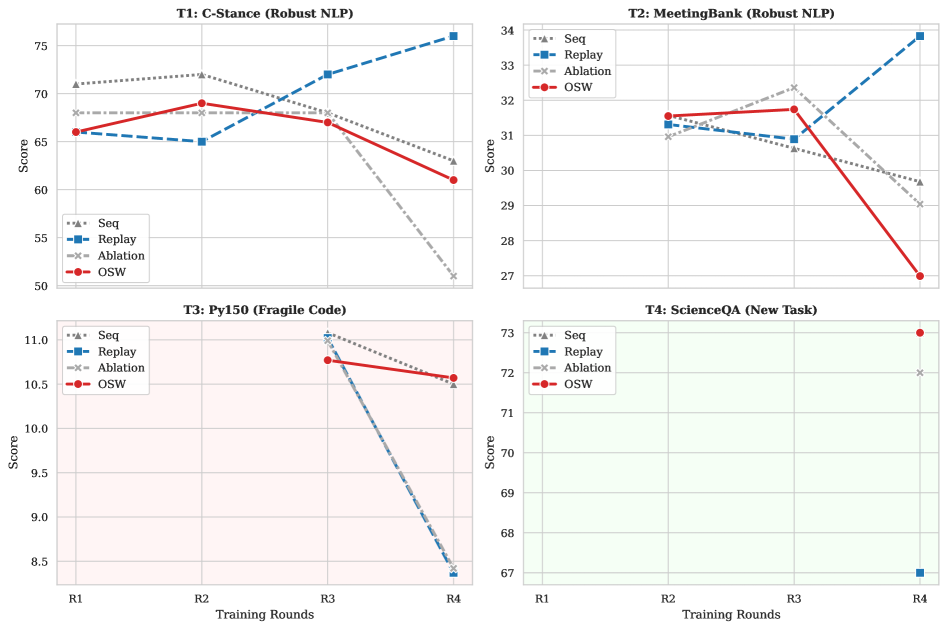
实验结果表明,OSW方法在保持新任务可塑性的同时,显著提高了LLM在结构化任务上的性能。例如,在代码生成任务中,OSW成功避免了经验回放导致的性能下降,并取得了优于其他基线方法的结果。这证明了OSW在平衡稳定性和可塑性方面的有效性。
🎯 应用场景
该研究成果可应用于需要持续学习新技能的LLM,例如智能助手、代码生成工具等。通过OSW方法,这些模型可以在不断学习新知识的同时,保持其在先前任务上的性能,避免因学习新任务而忘记旧技能。这对于构建可靠且适应性强的AI系统至关重要。
📄 摘要(原文)
Continual learning in Large Language Models (LLMs) faces the critical challenge of balancing stability (retaining old knowledge) and plasticity (learning new tasks). While Experience Replay (ER) is a standard countermeasure against catastrophic forgetting, its impact across diverse capabilities remains underexplored. In this work, we uncover a critical dichotomy in ER's behavior: while it induces positive backward transfer on robust, unstructured tasks (e.g., boosting performance on previous NLP classification tasks through repeated rehearsal), it causes severe negative transfer on fragile, structured domains like code generation (e.g., a significant relative drop in coding accuracy). This reveals that ER trades structural integrity for broad consolidation. To address this dilemma, we propose \textbf{Orthogonal Subspace Wake-up (OSW)}. OSW identifies essential parameter subspaces of previous tasks via a brief "wake-up" phase and enforces orthogonal updates for new tasks, providing a mathematically grounded "safety guarantee" for established knowledge structures. Empirical results across a diverse four-task sequence demonstrate that OSW uniquely succeeds in preserving fragile coding abilities where Replay fails, while simultaneously maintaining high plasticity for novel tasks. Our findings emphasize the necessity of evaluating structural safety alongside average retention in LLM continual learning.