Enhance the Safety in Reinforcement Learning by ADRC Lagrangian Methods
作者: Mingxu Zhang, Huicheng Zhang, Jiaming Ji, Yaodong Yang, Ying Sun
分类: cs.LG
发布日期: 2026-01-26
💡 一句话要点
提出ADRC-Lagrangian方法,提升强化学习安全性并减少振荡
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 主动抗扰控制 拉格朗日方法 机器人控制 自动驾驶
📋 核心要点
- 现有安全强化学习方法,如PID和经典拉格朗日方法,易受参数影响,存在振荡和安全违规问题。
- 论文提出ADRC-Lagrangian方法,利用主动抗扰控制(ADRC)增强鲁棒性,减少振荡,提升安全性。
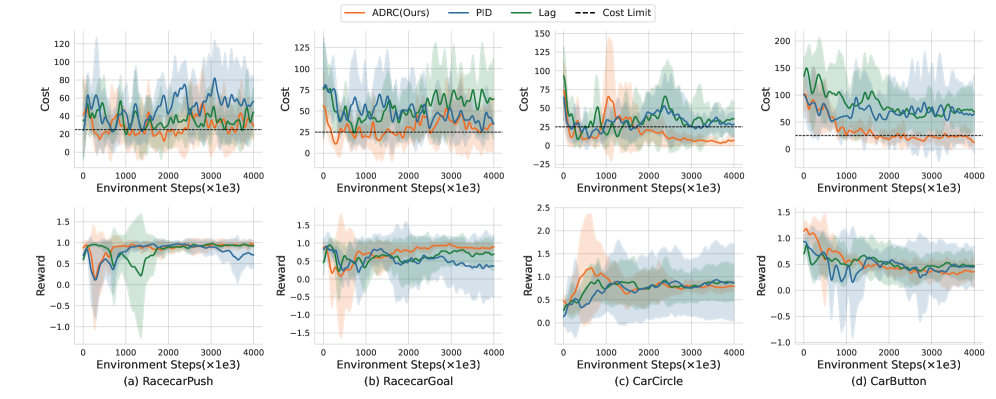
- 实验结果表明,该方法显著降低了安全违规、约束违规幅度和平均成本,提升效果明显。
📝 摘要(中文)
安全强化学习(Safe RL)旨在最大化奖励的同时满足安全约束,通常通过基于拉格朗日乘数的方法实现。然而,现有的方法,包括PID和经典拉格朗日方法,由于参数敏感性和固有的相位滞后,存在振荡和频繁违反安全约束的问题。为了解决这些限制,我们提出了ADRC-Lagrangian方法,该方法利用主动抗扰控制(ADRC)来增强鲁棒性并减少振荡。我们的统一框架涵盖了经典和PID拉格朗日方法作为特殊情况,同时显著提高了安全性能。大量实验表明,我们的方法将安全违规减少了高达74%,约束违规幅度减少了89%,平均成本降低了67%,从而确立了其在复杂环境中安全强化学习方面的卓越有效性。
🔬 方法详解
问题定义:安全强化学习旨在找到既能最大化奖励又能满足安全约束的策略。现有基于拉格朗日乘数的方法,如PID和经典拉格朗日方法,在复杂环境中表现出参数敏感性,容易产生振荡,导致频繁的安全约束违规。这些方法固有的相位滞后也是一个重要问题。
核心思路:论文的核心思路是将主动抗扰控制(ADRC)与拉格朗日方法相结合。ADRC能够有效地估计和补偿系统中的扰动,从而提高系统的鲁棒性和抗干扰能力。通过将ADRC集成到拉格朗日框架中,可以减少参数调整的敏感性,抑制振荡,并更有效地满足安全约束。
技术框架:该方法构建了一个统一的ADRC-Lagrangian框架,其中经典和PID拉格朗日方法可以被视为特殊情况。该框架主要包含以下几个模块:强化学习智能体,用于学习策略;拉格朗日乘数更新器,用于调整安全约束的权重;ADRC模块,用于估计和补偿系统扰动。整体流程是,智能体根据当前策略与环境交互,产生奖励和约束违反信号,拉格朗日乘数更新器根据这些信号调整拉格朗日乘数,ADRC模块估计和补偿扰动,最终更新策略。
关键创新:最重要的技术创新点在于将ADRC引入到拉格朗日安全强化学习框架中。与传统的PID或经典拉格朗日方法相比,ADRC能够更有效地处理系统中的不确定性和扰动,从而提高安全性和鲁棒性。ADRC通过扩张状态观测器(ESO)估计总扰动,并利用非线性状态误差反馈控制率进行补偿,无需精确的系统模型。
关键设计:ADRC模块的关键设计包括扩张状态观测器(ESO)的设计和非线性状态误差反馈控制率的设计。ESO用于估计系统中的总扰动,包括未建模的动态、外部扰动等。非线性状态误差反馈控制率用于根据状态误差和扰动估计来调整控制输入。拉格朗日乘数的更新通常采用梯度下降法,其学习率是一个重要的参数。此外,奖励函数和约束函数的设计也会影响最终的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的ADRC-Lagrangian方法在多个复杂环境中均取得了显著的性能提升。与现有的PID和经典拉格朗日方法相比,该方法将安全违规减少了高达74%,约束违规幅度减少了89%,平均成本降低了67%。这些数据表明,ADRC-Lagrangian方法在提高安全性和降低成本方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要安全保障的强化学习任务中,例如自动驾驶、机器人控制、资源调度等。在自动驾驶中,可以确保车辆在行驶过程中遵守交通规则和安全距离;在机器人控制中,可以防止机器人与环境发生碰撞;在资源调度中,可以避免资源过度消耗或分配不均。该方法具有很高的实际应用价值和潜力。
📄 摘要(原文)
Safe reinforcement learning (Safe RL) seeks to maximize rewards while satisfying safety constraints, typically addressed through Lagrangian-based methods. However, existing approaches, including PID and classical Lagrangian methods, suffer from oscillations and frequent safety violations due to parameter sensitivity and inherent phase lag. To address these limitations, we propose ADRC-Lagrangian methods that leverage Active Disturbance Rejection Control (ADRC) for enhanced robustness and reduced oscillations. Our unified framework encompasses classical and PID Lagrangian methods as special cases while significantly improving safety performance. Extensive experiments demonstrate that our approach reduces safety violations by up to 74%, constraint violation magnitudes by 89%, and average costs by 67\%, establishing superior effectiveness for Safe RL in complex environments.