AttenMIA: LLM Membership Inference Attack through Attention Signals
作者: Pedram Zaree, Md Abdullah Al Mamun, Yue Dong, Ihsen Alouani, Nael Abu-Ghazaleh
分类: cs.LG
发布日期: 2026-01-26
💡 一句话要点
AttenMIA:利用注意力信号的大语言模型成员推断攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 大型语言模型 注意力机制 隐私安全 Transformer模型
📋 核心要点
- 现有成员推断攻击(MIA)方法依赖于输出置信度或嵌入特征,但这些信号脆弱,攻击成功率受限。
- AttenMIA利用Transformer模型的自注意力模式,通过分析注意力头的信息和扰动散度来推断成员关系。
- 实验表明,AttenMIA在多个开源LLM上显著优于现有方法,尤其在低假阳性率下表现突出,且具有泛化能力。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被部署以支持或改进各种实际应用。鉴于其训练数据集的庞大规模,LLM记忆训练数据的倾向引发了严重的隐私和知识产权问题。一个关键威胁是成员推断攻击(MIA),旨在确定给定样本是否包含在模型的训练集中。现有的LLM的MIA主要依赖于输出置信度分数或基于嵌入的特征,但这些信号通常是脆弱的,导致攻击成功率有限。我们引入了AttenMIA,这是一个新的MIA框架,它利用Transformer模型内部的自注意力模式来推断成员关系。注意力控制着Transformer内部的信息流,暴露了不同的记忆模式,可用于识别数据集的成员。我们的方法使用来自跨层注意力头的信息,并将它们与基于扰动的散度指标相结合,以训练有效的MIA分类器。通过对包括LLaMA-2、Pythia和Opt模型在内的开源模型进行的大量实验,我们表明,基于注意力的特征始终优于基线,尤其是在重要的低假阳性指标下(例如,在使用Llama2-13b的WikiMIA-32基准测试中,实现了高达0.996的ROC AUC和87.9%的TPR@1%FPR)。我们表明,注意力信号可以跨数据集和架构泛化,并提供了层和头级别的分析,以了解成员泄漏最明显的地方。我们还表明,在数据提取框架中使用AttenMIA替换其他成员推断攻击,可以实现优于现有技术水平的训练数据提取攻击。我们的研究结果表明,最初引入以增强可解释性的注意力机制可能会无意中放大LLM中的隐私风险,突显了对新防御措施的需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的成员推断攻击(MIA)问题。现有的MIA方法,如基于输出置信度或嵌入特征的方法,在面对LLM时表现出脆弱性,攻击成功率较低。这是因为LLM的复杂性和规模使得这些简单信号难以有效区分训练集成员和非成员。
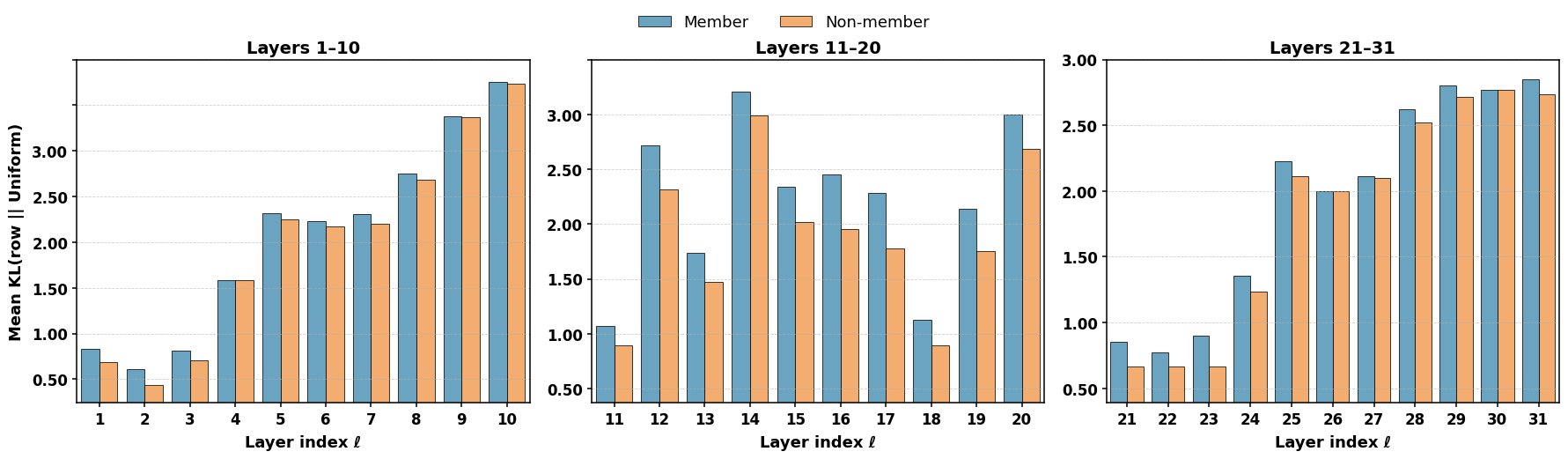
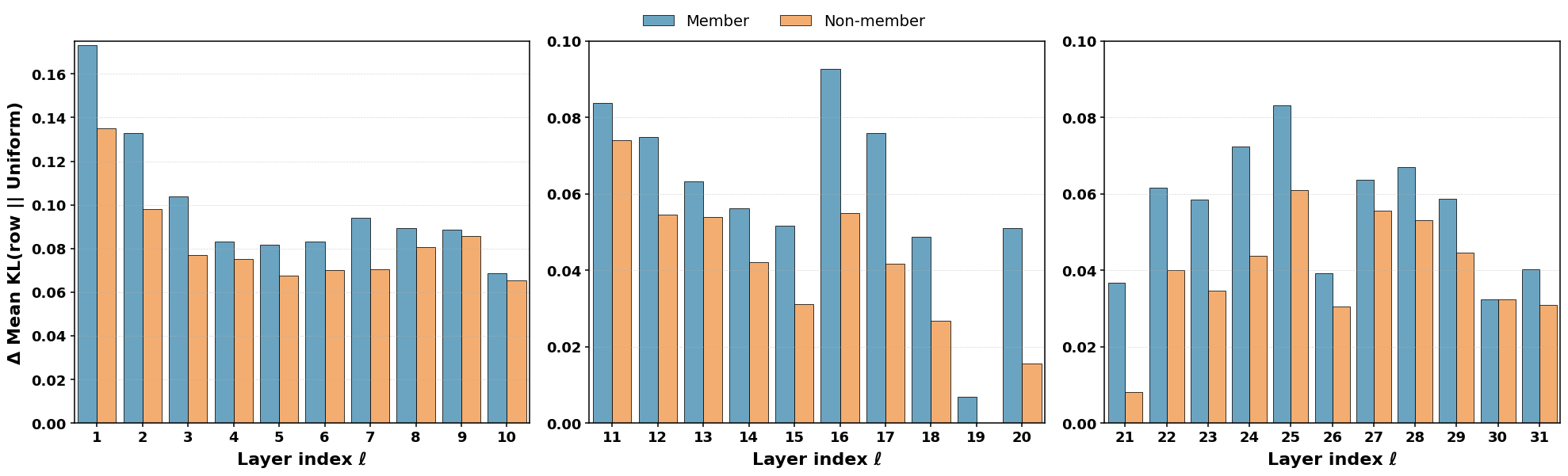
核心思路:论文的核心思路是利用Transformer模型中的自注意力机制来提取更具区分性的特征。注意力机制控制着模型内部的信息流动,能够揭示模型在记忆训练数据时形成的独特模式。通过分析这些注意力模式,可以更准确地判断一个样本是否属于训练集。
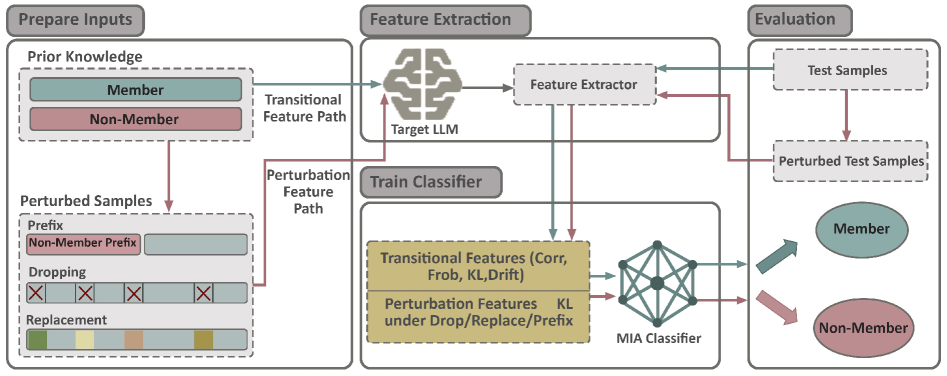
技术框架:AttenMIA框架主要包含以下几个阶段:1) 输入样本通过目标LLM模型,提取每一层中各个注意力头的注意力权重;2) 对提取的注意力权重进行处理,例如计算不同层之间的注意力差异或使用扰动方法;3) 将处理后的注意力特征输入到一个分类器中,该分类器被训练用于区分训练集成员和非成员。分类器的输出即为成员推断的结果。
关键创新:AttenMIA的关键创新在于利用了Transformer模型内部的注意力信号进行成员推断。与以往依赖于输出或嵌入的方法不同,AttenMIA深入模型内部,挖掘更细粒度的信息。此外,论文还结合了扰动分析,进一步增强了注意力特征的区分能力。
关键设计:AttenMIA的关键设计包括:1) 选择哪些层和哪些注意力头的注意力权重作为特征;2) 如何处理这些注意力权重,例如计算层间差异或应用扰动;3) 分类器的选择和训练方法。论文可能探索了不同的层、头组合,以及不同的扰动策略和分类器模型,以找到最佳的攻击配置。损失函数的设计目标是最大化成员和非成员之间的区分度。
🖼️ 关键图片
📊 实验亮点
AttenMIA在LLaMA-2、Pythia和Opt等开源LLM上进行了广泛的实验,结果表明,基于注意力的特征始终优于基线方法。特别是在低假阳性率(TPR@1%FPR)指标下,AttenMIA在WikiMIA-32基准测试中,使用Llama2-13b模型实现了高达0.996的ROC AUC和87.9%的TPR@1%FPR,显著提升了攻击性能。
🎯 应用场景
AttenMIA的研究成果可应用于评估和提升大型语言模型的隐私安全性。通过该方法,可以更有效地检测LLM是否存在过度记忆训练数据的问题,并为开发更有效的防御机制提供指导。此外,该研究也警示了开发者,在追求模型性能的同时,需要重视注意力机制可能带来的隐私风险。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed to enable or improve a multitude of real-world applications. Given the large size of their training data sets, their tendency to memorize training data raises serious privacy and intellectual property concerns. A key threat is the membership inference attack (MIA), which aims to determine whether a given sample was included in the model's training set. Existing MIAs for LLMs rely primarily on output confidence scores or embedding-based features, but these signals are often brittle, leading to limited attack success. We introduce AttenMIA, a new MIA framework that exploits self-attention patterns inside the transformer model to infer membership. Attention controls the information flow within the transformer, exposing different patterns for memorization that can be used to identify members of the dataset. Our method uses information from attention heads across layers and combines them with perturbation-based divergence metrics to train an effective MIA classifier. Using extensive experiments on open-source models including LLaMA-2, Pythia, and Opt models, we show that attention-based features consistently outperform baselines, particularly under the important low-false-positive metric (e.g., achieving up to 0.996 ROC AUC & 87.9% TPR@1%FPR on the WikiMIA-32 benchmark with Llama2-13b). We show that attention signals generalize across datasets and architectures, and provide a layer- and head-level analysis of where membership leakage is most pronounced. We also show that using AttenMIA to replace other membership inference attacks in a data extraction framework results in training data extraction attacks that outperform the state of the art. Our findings reveal that attention mechanisms, originally introduced to enhance interpretability, can inadvertently amplify privacy risks in LLMs, underscoring the need for new defenses.