Beyond Static Datasets: Robust Offline Policy Optimization via Vetted Synthetic Transitions
作者: Pedram Agand, Mo Chen
分类: cs.LG, cs.HC, cs.RO
发布日期: 2026-01-26
备注: 11 pages, 2 figures, 2 tables
💡 一句话要点
MoReBRAC:通过可信合成数据提升离线强化学习在机器人领域的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 模型基强化学习 合成数据 不确定性估计 机器人 分布偏移 变分自编码器
📋 核心要点
- 离线强化学习受限于静态数据集,策略学习易受分布偏移影响,导致保守策略和性能下降。
- MoReBRAC通过双重循环世界模型合成可信的转移样本,并利用分层不确定性流程筛选高质量数据。
- 在D4RL Gym-MuJoCo基准测试中,MoReBRAC在随机和次优数据集上表现出显著的性能提升。
📝 摘要(中文)
离线强化学习(ORL)在工业机器人等安全关键领域具有巨大潜力,但由于无法进行实时环境交互,面临着静态数据集与学习策略之间的分布偏移问题。这通常需要高度保守的策略,限制了潜在的策略改进。本文提出了一种基于模型的框架MoReBRAC,通过不确定性感知的潜在空间合成来解决这一限制。MoReBRAC利用双重循环世界模型合成高保真度的转移样本,以扩充训练数据。为了保证合成数据的可靠性,我们实现了一个分层不确定性流程,整合了变分自编码器(VAE)流形检测、模型敏感性分析和蒙特卡洛(MC) dropout。这种多层过滤过程保证了只有位于学习动力学高置信度区域内的转移样本才会被使用。在D4RL Gym-MuJoCo基准测试上的结果表明,该方法获得了显著的性能提升,尤其是在“随机”和“次优”数据情况下。我们进一步深入研究了VAE作为几何锚的作用,并讨论了从接近最优的数据集中学习时遇到的分布权衡。
🔬 方法详解
问题定义:离线强化学习(ORL)旨在利用静态数据集训练强化学习策略,避免与环境的直接交互。然而,由于训练数据与策略执行时遇到的状态分布存在差异(分布偏移),导致策略泛化能力差,性能受限。现有方法通常采用保守策略,但会牺牲策略的探索能力和潜在的性能提升。
核心思路:MoReBRAC的核心思路是利用学习到的世界模型生成额外的、高质量的合成数据,以扩充训练数据集,缓解分布偏移问题。通过仔细筛选合成数据,确保其可靠性,从而在不引入过多噪声的情况下,提升策略的性能。
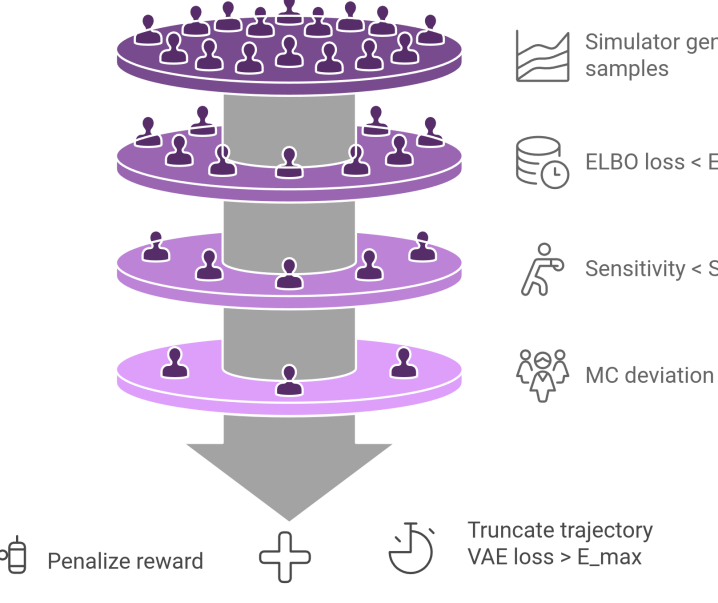
技术框架:MoReBRAC包含以下主要模块:1) 双重循环世界模型:用于学习环境的动态模型,并生成合成转移样本。2) 分层不确定性流程:包括VAE流形检测、模型敏感性分析和MC dropout,用于评估和过滤合成数据的质量。3) 策略优化:利用原始数据集和筛选后的合成数据,训练强化学习策略。
关键创新:MoReBRAC的关键创新在于其分层不确定性流程,能够有效地评估和过滤合成数据的质量。通过VAE流形检测,可以判断合成数据是否位于原始数据的流形附近;模型敏感性分析可以评估模型对输入变化的敏感程度;MC dropout可以估计模型预测的不确定性。这些方法共同作用,保证了只有高质量的合成数据才会被用于策略训练。
关键设计:双重循环世界模型采用循环神经网络结构,能够捕捉环境的动态特性。VAE用于学习原始数据的潜在空间表示,并用于流形检测。模型敏感性分析通过计算梯度来评估模型对输入变化的敏感程度。MC dropout通过多次dropout采样来估计模型预测的不确定性。损失函数包括重构损失、KL散度损失和强化学习目标函数。
🖼️ 关键图片
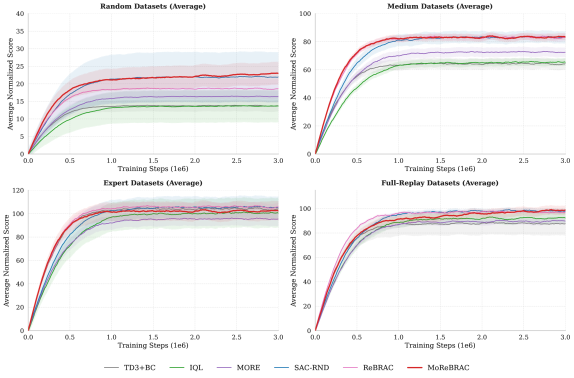
📊 实验亮点
MoReBRAC在D4RL Gym-MuJoCo基准测试中取得了显著的性能提升,尤其是在“随机”和“次优”数据集上。与现有离线强化学习算法相比,MoReBRAC能够更好地利用离线数据,并生成高质量的合成数据,从而提升策略的性能和鲁棒性。实验结果表明,MoReBRAC能够有效地缓解分布偏移问题,并在不同数据集上表现出良好的泛化能力。
🎯 应用场景
MoReBRAC适用于需要在安全关键环境中进行策略学习的场景,例如工业机器人、自动驾驶和医疗诊断。通过利用离线数据和合成数据,可以在避免与环境直接交互的情况下,训练出高性能的强化学习策略,降低试错成本和风险。该方法还可以应用于数据稀缺或难以获取的领域,例如罕见疾病的治疗方案优化。
📄 摘要(原文)
Offline Reinforcement Learning (ORL) holds immense promise for safety-critical domains like industrial robotics, where real-time environmental interaction is often prohibitive. A primary obstacle in ORL remains the distributional shift between the static dataset and the learned policy, which typically mandates high degrees of conservatism that can restrain potential policy improvements. We present MoReBRAC, a model-based framework that addresses this limitation through Uncertainty-Aware latent synthesis. Instead of relying solely on the fixed data, MoReBRAC utilizes a dual-recurrent world model to synthesize high-fidelity transitions that augment the training manifold. To ensure the reliability of this synthetic data, we implement a hierarchical uncertainty pipeline integrating Variational Autoencoder (VAE) manifold detection, model sensitivity analysis, and Monte Carlo (MC) dropout. This multi-layered filtering process guarantees that only transitions residing within high-confidence regions of the learned dynamics are utilized. Our results on D4RL Gym-MuJoCo benchmarks reveal significant performance gains, particularly in
random'' andsuboptimal'' data regimes. We further provide insights into the role of the VAE as a geometric anchor and discuss the distributional trade-offs encountered when learning from near-optimal datasets.