From LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models
作者: Longwei Ding, Anhao Zhao, Fanghua Ye, Ziyang Chen, Xiaoyu Shen
分类: cs.LG
发布日期: 2026-01-26
备注: 18 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
针对推理增强型LLM,提出更有效的模型剪枝策略,显著提升推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型剪枝 大型语言模型 推理增强 深度剪枝 宽度剪枝 动态剪枝 模型压缩
📋 核心要点
- 现有模型剪枝方法主要针对指令跟随型LLM,缺乏对推理增强型LLM的有效剪枝策略研究。
- 通过对齐剪枝校准和恢复数据与原始训练分布,实现更稳定可靠的剪枝行为,并区分指令跟随和推理增强模型。
- 实验表明,深度剪枝适合分类,宽度剪枝适合生成和推理,静态剪枝更利于保留推理能力。
📝 摘要(中文)
大型语言模型(LLM)的部署成本日益增加,促使了对模型剪枝的广泛研究。然而,现有研究大多集中在指令跟随型LLM上,尚不清楚已有的剪枝策略是否适用于显式生成长中间推理轨迹的推理增强型模型。本文对指令跟随型(LLM-instruct)和推理增强型(LLM-think)模型进行了受控剪枝研究。为了隔离剪枝的影响,我们将剪枝校准和剪枝后恢复数据与每个模型的原始训练分布对齐,这使得剪枝行为更加稳定和可靠。我们评估了静态深度剪枝、静态宽度剪枝和动态剪枝在涵盖分类、生成和推理的17个任务上的性能。结果表明,存在明显的范式依赖差异:深度剪枝在分类任务上优于宽度剪枝,而宽度剪枝对于生成和推理更稳健。此外,静态剪枝更好地保留了推理性能,而动态剪枝在分类和生成方面表现出色,但在长链推理方面仍然具有挑战性。这些发现强调了需要明确考虑推理增强型LLM独特特征的剪枝策略。代码已公开。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)剪枝研究主要集中在指令跟随型LLM上,而忽略了推理增强型LLM。推理增强型LLM通过生成中间推理步骤来提高解决复杂问题的能力,但现有的剪枝方法是否适用于此类模型,以及如何针对此类模型设计更有效的剪枝策略,尚不明确。现有方法可能无法有效保留推理能力,导致性能下降。
核心思路:本文的核心思路是针对指令跟随型LLM和推理增强型LLM的特性,分别研究不同的剪枝策略。通过控制实验,分析不同剪枝方法对不同类型任务的影响。关键在于将剪枝校准和剪枝后恢复数据与模型的原始训练分布对齐,以保证剪枝过程的稳定性和可靠性。
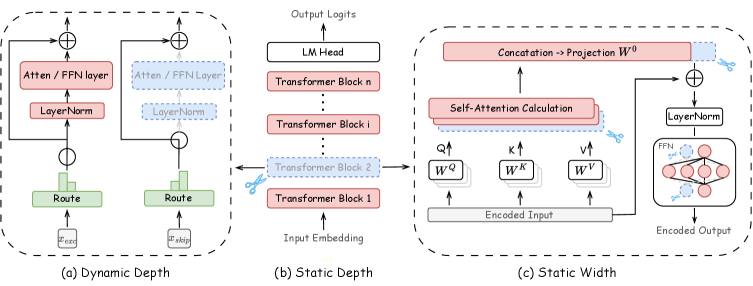
技术框架:该研究的技术框架主要包括以下几个步骤:1)构建指令跟随型(LLM-instruct)和推理增强型(LLM-think)两种类型的LLM;2)设计剪枝校准和剪枝后恢复数据与原始训练分布对齐的实验方案;3)评估静态深度剪枝、静态宽度剪枝和动态剪枝三种剪枝策略;4)在17个涵盖分类、生成和推理的任务上进行实验,对比不同剪枝策略的性能。
关键创新:该研究的关键创新在于:1)首次系统性地研究了针对推理增强型LLM的剪枝问题;2)提出了将剪枝校准和剪枝后恢复数据与原始训练分布对齐的方法,提高了剪枝的稳定性和可靠性;3)发现了不同剪枝策略对指令跟随型和推理增强型LLM的影响存在差异,为针对不同类型的LLM设计更有效的剪枝策略提供了指导。
关键设计:在实验设计方面,作者精心选择了17个任务,涵盖分类、生成和推理,以全面评估不同剪枝策略的性能。在数据处理方面,作者特别强调了剪枝校准和剪枝后恢复数据与原始训练分布的对齐,具体实现方式未知。三种剪枝策略(静态深度剪枝、静态宽度剪枝和动态剪枝)的具体实现细节也未在摘要中详细描述。
🖼️ 关键图片

📊 实验亮点
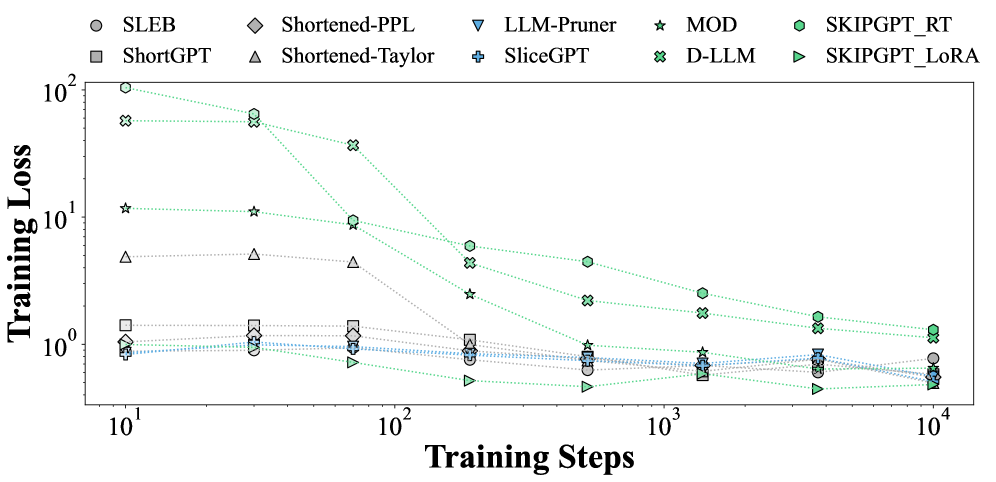
实验结果表明,深度剪枝在分类任务上优于宽度剪枝,而宽度剪枝对于生成和推理任务更稳健。静态剪枝更好地保留了推理性能,而动态剪枝在分类和生成方面表现出色,但在长链推理方面仍然具有挑战性。这些发现为针对不同类型的LLM选择合适的剪枝策略提供了重要的依据。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,尤其是在资源受限的环境中,例如移动设备、边缘计算等。通过选择合适的剪枝策略,可以在保证模型性能的前提下,显著降低模型的计算复杂度和存储空间,从而实现更高效的模型部署和推理。
📄 摘要(原文)
Large language models (LLMs) are increasingly costly to deploy, motivating extensive research on model pruning. However, most existing studies focus on instruction-following LLMs, leaving it unclear whether established pruning strategies transfer to reasoning-augmented models that explicitly generate long intermediate reasoning traces. In this work, we conduct a controlled study of pruning for both instruction-following ($\textbf{LLM-instruct}$) and reasoning-augmented ($\textbf{LLM-think}$) models. To isolate the effects of pruning, we align pruning calibration and post-pruning recovery data with each model's original training distribution, which we show yields more stable and reliable pruning behavior. We evaluate static depth pruning, static width pruning, and dynamic pruning across 17 tasks spanning classification, generation, and reasoning. Our results reveal clear paradigm-dependent differences: depth pruning outperforms width pruning on classification tasks, while width pruning is more robust for generation and reasoning. Moreover, static pruning better preserves reasoning performance, whereas dynamic pruning excels on classification and generation but remains challenging for long-chain reasoning. These findings underscore the need for pruning strategies that explicitly account for the distinct characteristics of reasoning-augmented LLMs. Our code is publicly available at https://github.com/EIT-NLP/LRM-Pruning.