LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts
作者: Venmugil Elango, Nidhi Bhatia, Roger Waleffe, Rasoul Shafipour, Tomer Asida, Abhinav Khattar, Nave Assaf, Maximilian Golub, Joey Guman, Tiyasa Mitra, Ritchie Zhao, Ritika Borkar, Ran Zilberstein, Mostofa Patwary, Mohammad Shoeybi, Bita Rouhani
分类: cs.LG, cs.AI
发布日期: 2026-01-26
💡 一句话要点
LatentMoE:面向最优精度/FLOP和参数效率的混合专家模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 模型优化 硬件-软件协同设计 大型语言模型 推理成本 精度/FLOP
📋 核心要点
- 现有MoE模型在推理成本(精度/FLOP和精度/参数)方面与最优状态的差距尚不明确,存在优化空间。
- LatentMoE通过硬件-软件协同设计,系统性地探索模型架构,优化精度与计算成本的平衡。
- 实验表明,LatentMoE在精度/FLOP和精度/参数方面始终优于标准MoE架构,并已应用于Nemotron-3模型。
📝 摘要(中文)
混合专家模型(MoE)已成为许多最先进的开源和专有大型语言模型的核心组成部分。尽管MoE被广泛采用,但现有MoE架构在推理成本方面,即以每浮点运算和每参数的精度来衡量,是否接近最优仍然不清楚。本文从硬件-软件协同设计的角度重新审视MoE设计,并以经验和理论考虑为基础。我们描述了跨越离线高吞吐量执行和在线、延迟关键推理等不同部署方案的关键性能瓶颈。在这些见解的指导下,我们引入了LatentMoE,这是一种新的模型架构,它来自于系统的设计探索,并针对最大化每单位计算的精度进行了优化。高达950亿参数规模和超过1T token训练范围的实证设计空间探索,以及支持性的理论分析表明,LatentMoE在每FLOP和每参数的精度方面始终优于标准MoE架构。鉴于其强大的性能,LatentMoE架构已被旗舰Nemotron-3 Super和Ultra模型采用,并扩展到更大的范围,包括更长的token范围和更大的模型尺寸,如Nvidia等人在arXiv:2512.20856中报告的那样。
🔬 方法详解
问题定义:现有混合专家模型(MoE)虽然被广泛应用,但其推理成本,特别是精度与浮点运算(FLOP)和参数数量之间的关系,尚未达到最优。现有方法在硬件资源利用率和模型效率方面存在瓶颈,尤其是在不同部署场景下,例如高吞吐量离线执行和低延迟在线推理。
核心思路:LatentMoE的核心思路是从硬件-软件协同设计的角度出发,通过系统性的设计空间探索,找到在精度和计算成本之间取得最佳平衡的模型架构。这种设计思路强调对不同部署场景下的性能瓶颈进行深入分析,并据此指导模型结构的优化。
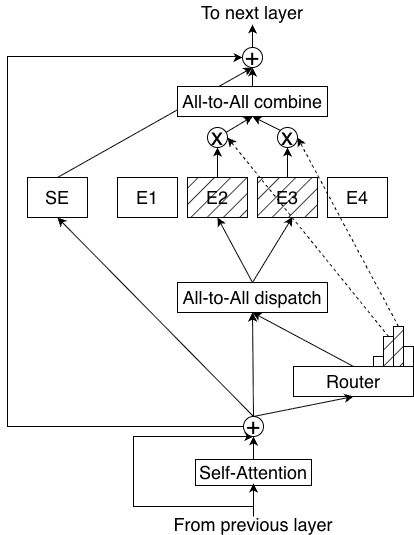
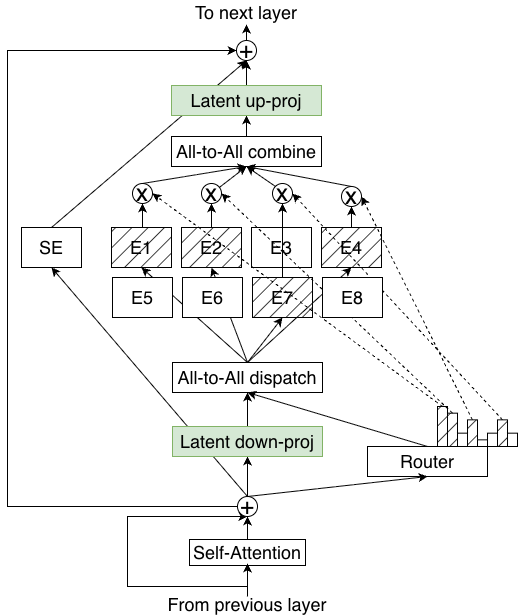
技术框架:LatentMoE的整体架构在标准MoE的基础上进行了改进,具体的技术框架细节论文中没有详细展开,但强调了对模型架构的系统性探索和优化。该框架可能包含以下阶段:1) 性能瓶颈分析:识别不同部署场景下的关键性能瓶颈。2) 设计空间探索:系统性地探索不同的模型架构和参数配置。3) 优化目标设定:以最大化精度/FLOP和精度/参数为目标进行优化。4) 实验验证:在大规模数据集上进行实验,验证LatentMoE的性能。
关键创新:LatentMoE的关键创新在于其设计理念,即从硬件-软件协同设计的角度出发,系统性地优化MoE模型的架构,以实现更高的精度/FLOP和精度/参数。与现有方法相比,LatentMoE更加注重对不同部署场景下的性能瓶颈进行分析,并据此指导模型结构的优化。此外,LatentMoE强调通过大规模的实验来验证模型性能,并结合理论分析来指导设计。
关键设计:论文中没有详细描述LatentMoE的关键设计细节,例如具体的参数设置、损失函数或网络结构。但是,可以推断,LatentMoE的设计可能包括以下方面:1) 专家选择机制的优化:改进专家选择策略,以减少计算量并提高精度。2) 专家网络的结构优化:设计更高效的专家网络结构,以减少参数数量并提高计算效率。3) 负载均衡策略的优化:改进负载均衡策略,以确保各个专家网络的负载均衡,从而提高整体性能。4) 硬件感知的优化:针对不同的硬件平台进行优化,以充分利用硬件资源。
🖼️ 关键图片

📊 实验亮点
LatentMoE在高达950亿参数规模和超过1T token训练范围的实验中,始终优于标准MoE架构,在精度/FLOP和精度/参数方面均有显著提升。该架构已被Nvidia的旗舰Nemotron-3 Super和Ultra模型采用,并扩展到更大的模型尺寸和更长的token范围,进一步验证了其有效性。
🎯 应用场景
LatentMoE具有广泛的应用前景,尤其是在资源受限的场景下,例如移动设备、边缘计算和低功耗服务器。它可以用于构建更高效的大型语言模型,从而降低推理成本并提高用户体验。此外,LatentMoE还可以应用于其他领域,例如图像识别、语音识别和自然语言处理等,以提高模型的性能和效率。未来,LatentMoE有望成为构建下一代人工智能系统的关键技术。
📄 摘要(原文)
Mixture of Experts (MoEs) have become a central component of many state-of-the-art open-source and proprietary large language models. Despite their widespread adoption, it remains unclear how close existing MoE architectures are to optimal with respect to inference cost, as measured by accuracy per floating-point operation and per parameter. In this work, we revisit MoE design from a hardware-software co-design perspective, grounded in empirical and theoretical considerations. We characterize key performance bottlenecks across diverse deployment regimes, spanning offline high-throughput execution and online, latency-critical inference. Guided by these insights, we introduce LatentMoE, a new model architecture resulting from systematic design exploration and optimized for maximal accuracy per unit of compute. Empirical design space exploration at scales of up to 95B parameters and over a 1T-token training horizon, together with supporting theoretical analysis, shows that LatentMoE consistently outperforms standard MoE architectures in terms of accuracy per FLOP and per parameter. Given its strong performance, the LatentMoE architecture has been adopted by the flagship Nemotron-3 Super and Ultra models and scaled to substantially larger regimes, including longer token horizons and larger model sizes, as reported in Nvidia et al. (arXiv:2512.20856).