DRPG (Decompose, Retrieve, Plan, Generate): An Agentic Framework for Academic Rebuttal
作者: Peixuan Han, Yingjie Yu, Jingjun Xu, Jiaxuan You
分类: cs.LG
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出DRPG框架,用于自动生成学术反驳,显著提升反驳质量并超越人类平均水平。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学术反驳 自然语言处理 大型语言模型 Agent框架 自动生成 评审意见 策略规划
📋 核心要点
- 现有学术反驳方法依赖通用LLM或简单流程,难以处理长文本,缺乏针对性和说服力。
- DRPG框架通过分解、检索、规划和生成四个步骤,实现自动学术反驳,提升反驳质量。
- 实验表明,DRPG优于现有方法,仅用8B模型即超越人类平均水平,规划器准确率超98%。
📝 摘要(中文)
尽管大型语言模型(LLMs)在科学研究工作流程中得到越来越多的应用,但对学术反驳的自动化支持仍然很大程度上未被探索。学术反驳是学术交流和同行评审的关键步骤。现有方法通常依赖于现成的LLMs或简单的流程,难以理解长上下文,并且常常无法产生有针对性和说服力的回应。本文提出了DRPG,一个用于自动生成学术反驳的Agent框架,它通过四个步骤运行:将评审分解为原子关注点,从论文中检索相关证据,规划反驳策略,并相应地生成回应。值得注意的是,DRPG中的规划器在识别最可行的反驳方向时达到了超过98%的准确率。在顶级会议数据上的实验表明,DRPG显著优于现有的反驳流程,并且仅使用一个8B模型就实现了超越平均人类水平的性能。我们的分析进一步证明了规划器设计的有效性及其在提供多角度和可解释建议方面的价值。我们还表明,DRPG在更复杂的多轮环境中也能很好地工作。这些结果突出了DRPG的有效性及其提供高质量反驳内容和支持学术讨论扩展的潜力。该工作的代码可在https://github.com/ulab-uiuc/DRPG-RebuttalAgent 获取。
🔬 方法详解
问题定义:论文旨在解决学术评审反驳自动化的问题。现有方法,如直接使用大型语言模型或简单的pipeline,无法充分理解评审意见中的长上下文信息,导致生成的反驳缺乏针对性和说服力。此外,现有方法缺乏对反驳策略的有效规划,难以提供多角度和可解释的建议。
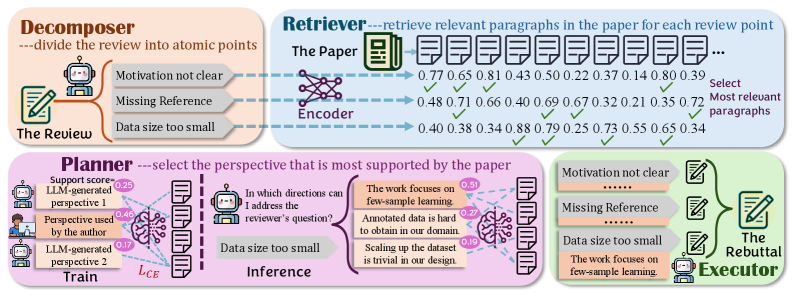
核心思路:DRPG的核心思路是将反驳过程分解为四个可控的步骤:分解(Decompose)、检索(Retrieve)、规划(Plan)和生成(Generate)。通过分解评审意见,精准定位问题;检索论文证据,提供支撑;规划反驳策略,确保有效性;最终生成高质量的反驳内容。这种模块化的设计使得每个步骤都可以独立优化,从而提升整体反驳效果。
技术框架:DRPG框架包含四个主要模块:1) 分解器(Decomposer):将评审意见分解为更小的、原子级别的关注点。2) 检索器(Retriever):从论文中检索与这些关注点相关的证据。3) 规划器(Planner):根据分解的关注点和检索到的证据,规划反驳策略。4) 生成器(Generator):根据规划的反驳策略,生成最终的反驳文本。整个流程是顺序执行的,每个模块的输出作为下一个模块的输入。
关键创新:DRPG的关键创新在于引入了规划器(Planner)模块,该模块负责根据分解的评审意见和检索到的论文证据,智能地规划反驳策略。规划器能够识别最可行的反驳方向,并为生成器提供指导,从而确保生成的反驳具有针对性和说服力。此外,DRPG框架的模块化设计也使得每个模块都可以独立优化,从而提升整体反驳效果。
关键设计:规划器(Planner)的设计是DRPG的关键。论文中提到规划器在识别最可行的反驳方向时达到了超过98%的准确率,但具体实现细节(例如,规划器的网络结构、损失函数等)在论文中没有详细描述,属于未知信息。论文中也没有提及其他模块的具体参数设置或网络结构等技术细节。
🖼️ 关键图片

📊 实验亮点
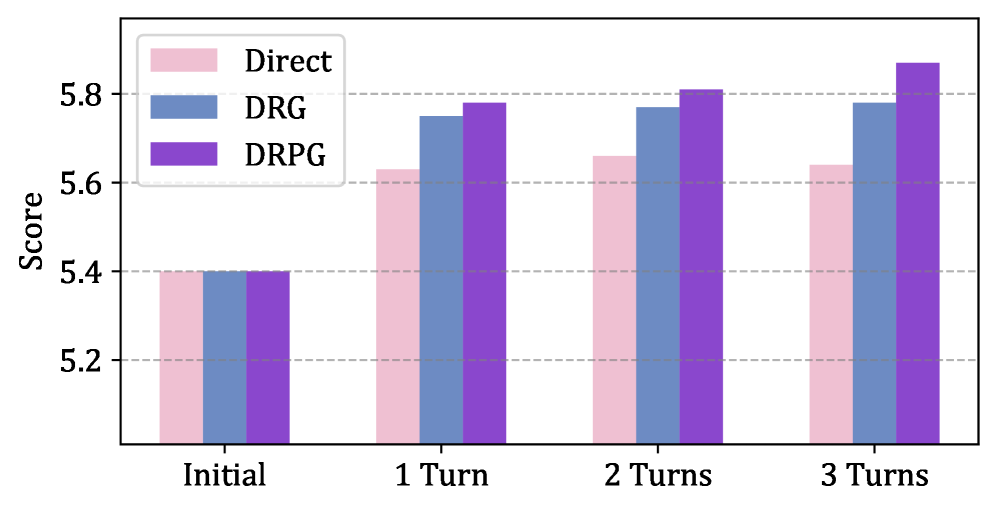
DRPG在顶级会议数据上的实验结果表明,其性能显著优于现有的反驳流程。更重要的是,DRPG仅使用一个8B模型就实现了超越平均人类水平的性能。规划器在识别最可行的反驳方向时达到了超过98%的准确率,证明了其有效性。此外,DRPG在复杂的多轮反驳环境中也表现良好,验证了其鲁棒性。
🎯 应用场景
DRPG框架可应用于学术论文评审流程,辅助作者高效生成高质量的反驳意见,提升学术交流效率。该研究具有实际应用价值,有助于缓解评审压力,促进更深入的学术讨论。未来,DRPG可扩展到其他需要论证和辩护的场景,例如法律辩护、产品推广等。
📄 摘要(原文)
Despite the growing adoption of large language models (LLMs) in scientific research workflows, automated support for academic rebuttal, a crucial step in academic communication and peer review, remains largely underexplored. Existing approaches typically rely on off-the-shelf LLMs or simple pipelines, which struggle with long-context understanding and often fail to produce targeted and persuasive responses. In this paper, we propose DRPG, an agentic framework for automatic academic rebuttal generation that operates through four steps: Decompose reviews into atomic concerns, Retrieve relevant evidence from the paper, Plan rebuttal strategies, and Generate responses accordingly. Notably, the Planner in DRPG reaches over 98% accuracy in identifying the most feasible rebuttal direction. Experiments on data from top-tier conferences demonstrate that DRPG significantly outperforms existing rebuttal pipelines and achieves performance beyond the average human level using only an 8B model. Our analysis further demonstrates the effectiveness of the planner design and its value in providing multi-perspective and explainable suggestions. We also showed that DRPG works well in a more complex multi-round setting. These results highlight the effectiveness of DRPG and its potential to provide high-quality rebuttal content and support the scaling of academic discussions. Codes for this work are available at https://github.com/ulab-uiuc/DRPG-RebuttalAgent.