Auto-Regressive Masked Diffusion Models
作者: Mahdi Karami, Ali Ghodsi
分类: cs.LG
发布日期: 2026-01-23
期刊: 29th International Conference on Artificial Intelligence and Statistics (AISTATS) 2026
💡 一句话要点
提出自回归掩码扩散模型(ARMD),提升语言建模效率和并行生成能力。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 自回归模型 掩码扩散模型 语言建模 并行生成 置换等变性 因果模型 文本生成 深度学习
📋 核心要点
- 现有掩码扩散模型在语言建模中性能不及自回归模型,且训练效率较低。
- ARMD将掩码扩散过程视为块状因果模型,实现并行计算条件概率和自回归解码。
- 实验表明,ARMD在语言建模基准上超越现有扩散模型,并为并行文本生成设立新基准。
📝 摘要(中文)
掩码扩散模型(MDM)在语言建模中展现出潜力,但与自回归模型(ARM)相比仍存在性能差距,且需要更多训练迭代。本文提出了自回归掩码扩散(ARMD)模型,旨在通过结合自回归模型的训练效率和基于扩散模型的并行生成能力来弥合这一差距。核心思想是将掩码扩散过程重新定义为块状因果模型。这种视角允许设计一个严格因果、置换等变的架构,在单个并行前向传递中计算多个去噪步骤中的所有条件概率。该架构支持高效的自回归式解码和渐进式置换训练方案,使模型能够学习规范的从左到右和随机token排序。利用这种灵活性,引入了一种新颖的步进并行生成策略,通过并行流生成token,同时保持全局一致性,从而加速推理。实验结果表明,ARMD在标准语言建模基准测试中取得了最先进的性能,优于已建立的扩散基线,同时需要的训练步骤显著减少。此外,它为并行文本生成建立了一个新的基准,有效地弥合了并行和顺序解码之间的性能差距。
🔬 方法详解
问题定义:论文旨在解决掩码扩散模型(MDMs)在语言建模任务中,性能不如自回归模型(ARMs)且训练效率较低的问题。现有MDMs需要更多的训练迭代才能达到与ARMs相当的性能,限制了其在实际应用中的潜力。
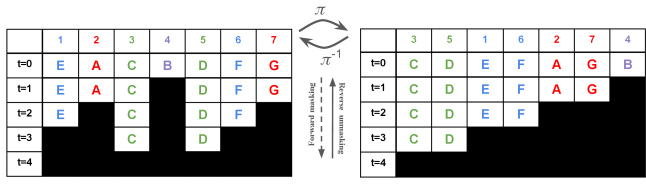
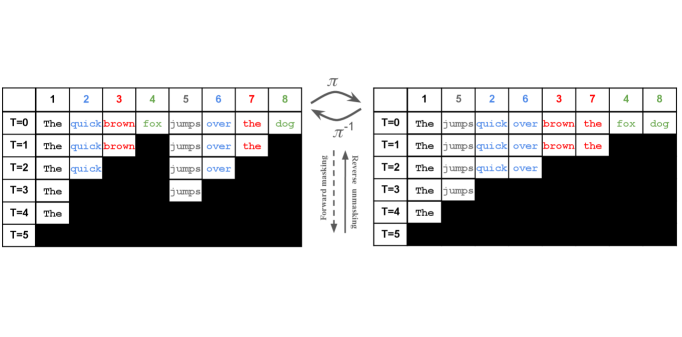
核心思路:论文的核心思路是将掩码扩散过程重新建模为一个块状因果模型。通过这种方式,可以将扩散模型的并行生成能力与自回归模型的训练效率相结合。关键在于设计一个置换等变且严格因果的架构,使得模型可以在一个前向传播中并行计算多个去噪步骤的条件概率。
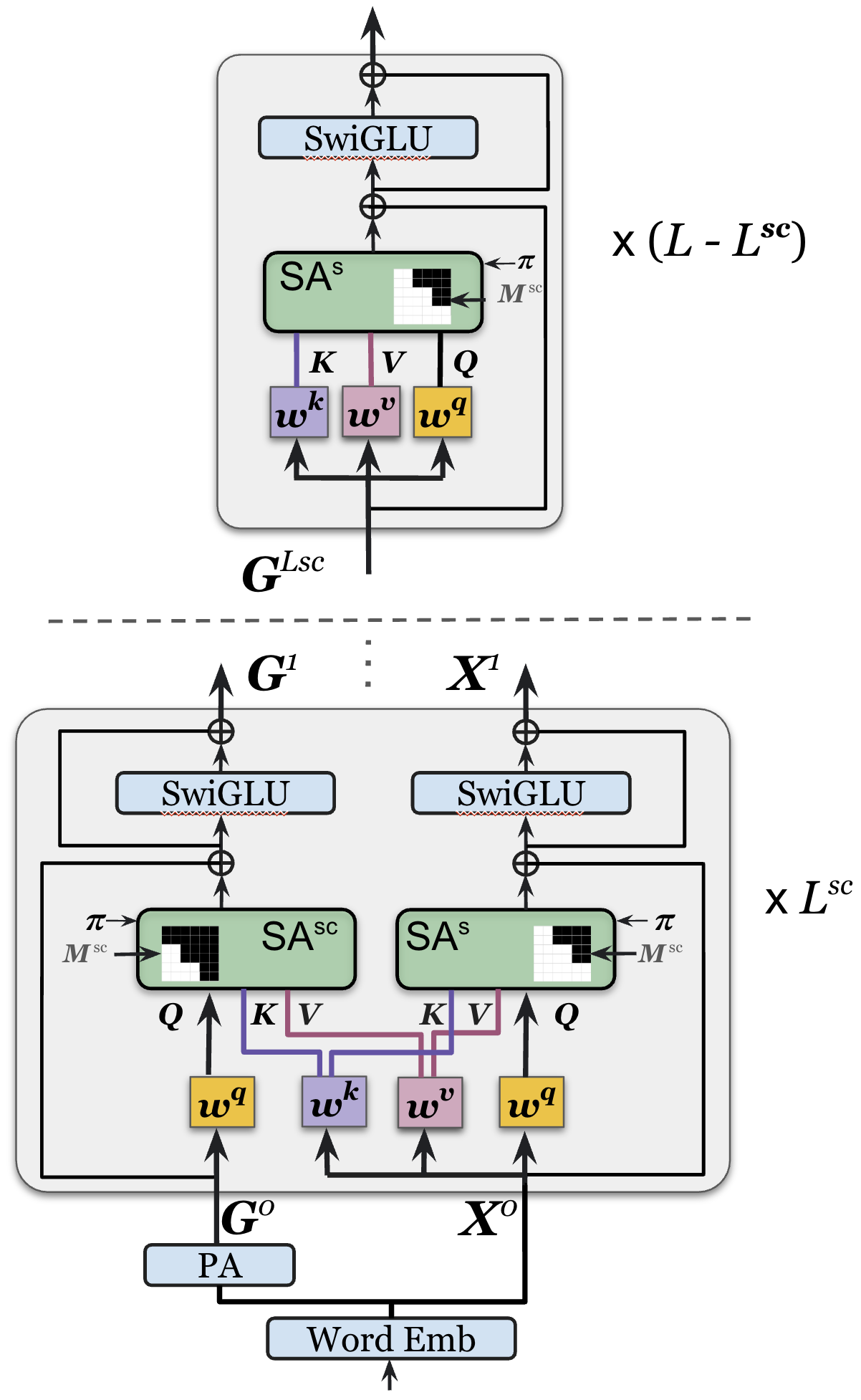
技术框架:ARMD模型包含以下几个主要组成部分:1) 一个置换等变的编码器,用于处理输入序列;2) 一个扩散过程,用于逐步添加噪声;3) 一个去噪网络,用于预测原始序列;4) 一个自回归解码器,用于生成最终的文本序列。训练过程采用渐进式置换训练方案,使模型能够学习不同的token排序方式。推理阶段采用步进并行生成策略,通过并行流生成token,从而加速推理过程。
关键创新:ARMD的关键创新在于将掩码扩散过程与自回归建模相结合,设计了一个严格因果且置换等变的架构。这种架构允许模型在一个前向传播中并行计算多个去噪步骤的条件概率,从而提高了训练效率。此外,步进并行生成策略进一步加速了推理过程,弥合了并行和顺序解码之间的性能差距。
关键设计:ARMD模型采用Transformer架构作为其核心组件。损失函数包括一个去噪损失和一个自回归损失。置换等变性通过使用位置编码来实现。步进并行生成策略通过将序列分成多个块,并并行生成这些块来实现。具体的参数设置(如Transformer的层数、头数、隐藏层大小等)需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
ARMD在标准语言建模基准测试中取得了最先进的性能,超越了已有的扩散模型。实验结果表明,ARMD在训练步骤显著减少的情况下,仍然能够达到甚至超过现有模型的性能。此外,ARMD在并行文本生成方面也取得了显著的成果,有效地弥合了并行和顺序解码之间的性能差距,为并行文本生成建立了一个新的基准。
🎯 应用场景
ARMD模型可应用于各种自然语言处理任务,如文本生成、机器翻译、文本摘要等。其高效的训练和并行生成能力使其特别适用于需要快速生成大量文本的应用场景,例如对话系统、内容创作和数据增强。该研究有望推动并行文本生成技术的发展,并促进更高效、更强大的语言模型的构建。
📄 摘要(原文)
Masked diffusion models (MDMs) have emerged as a promising approach for language modeling, yet they face a performance gap compared to autoregressive models (ARMs) and require more training iterations. In this work, we present the Auto-Regressive Masked Diffusion (ARMD) model, an architecture designed to close this gap by unifying the training efficiency of autoregressive models with the parallel generation capabilities of diffusion-based models. Our key insight is to reframe the masked diffusion process as a block-wise causal model. This perspective allows us to design a strictly causal, permutation-equivariant architecture that computes all conditional probabilities across multiple denoising steps in a single, parallel forward pass. The resulting architecture supports efficient, autoregressive-style decoding and a progressive permutation training scheme, allowing the model to learn both canonical left-to-right and random token orderings. Leveraging this flexibility, we introduce a novel strided parallel generation strategy that accelerates inference by generating tokens in parallel streams while maintaining global coherence. Empirical results demonstrate that ARMD achieves state-of-the-art performance on standard language modeling benchmarks, outperforming established diffusion baselines while requiring significantly fewer training steps. Furthermore, it establishes a new benchmark for parallel text generation, effectively bridging the performance gap between parallel and sequential decoding.