The Trajectory Alignment Coefficient in Two Acts: From Reward Tuning to Reward Learning
作者: Calarina Muslimani, Yunshu Du, Kenta Kawamoto, Kaushik Subramanian, Peter Stone, Peter Wurman
分类: cs.LG, cs.HC
发布日期: 2026-01-23
💡 一句话要点
提出Soft-TAC,用于从人类偏好数据中学习奖励函数,提升强化学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 奖励函数学习 人类偏好 轨迹对齐系数 可微优化
📋 核心要点
- 奖励函数设计是强化学习的关键挑战,手动调整权重耗时且易出错,影响最终策略性能。
- 论文提出Soft-TAC,一种可微的轨迹对齐系数近似,直接从人类偏好数据中学习奖励模型。
- 实验表明,Soft-TAC能有效捕捉人类偏好,在复杂赛车游戏中生成更具区分性的智能体行为。
📝 摘要(中文)
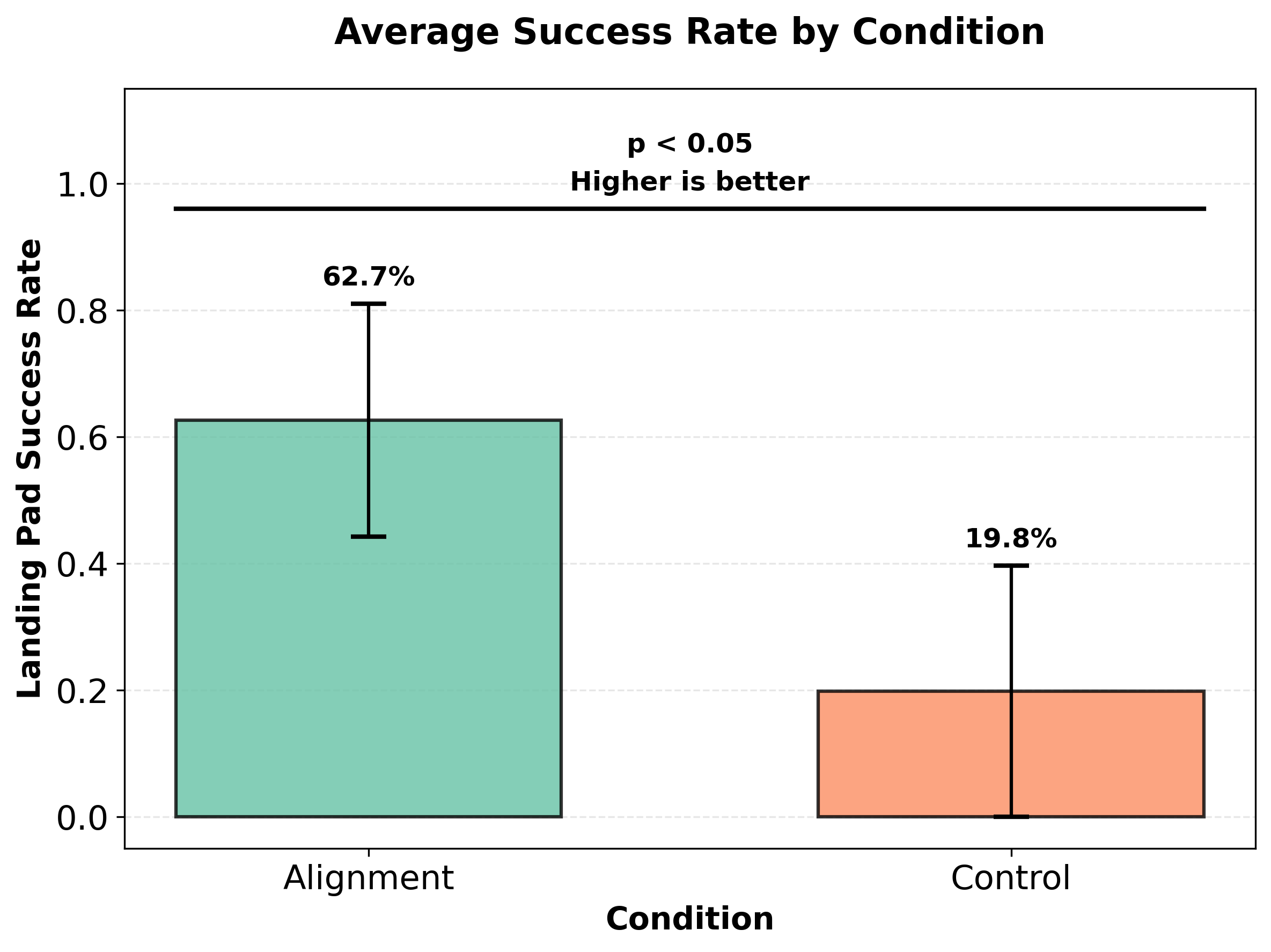
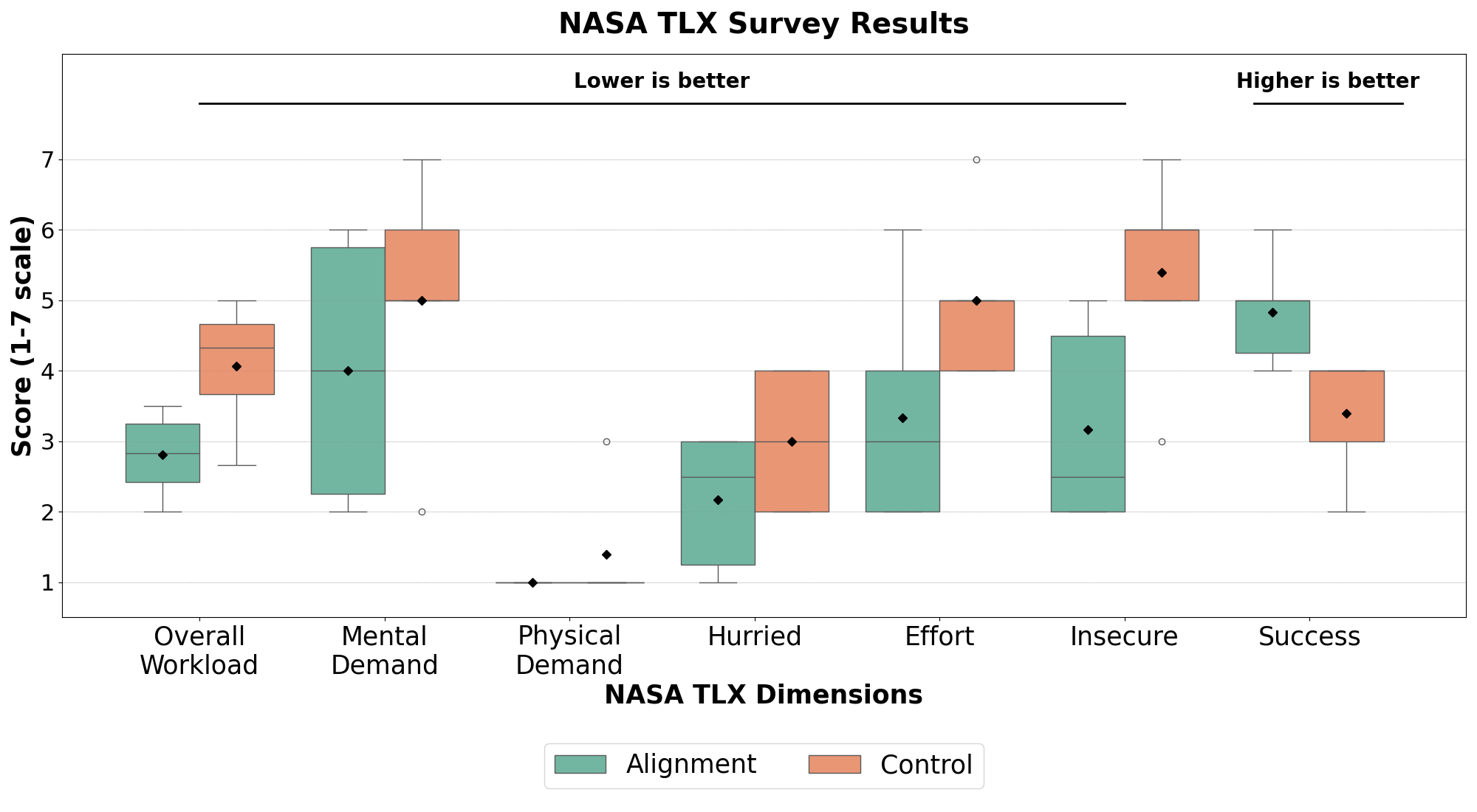
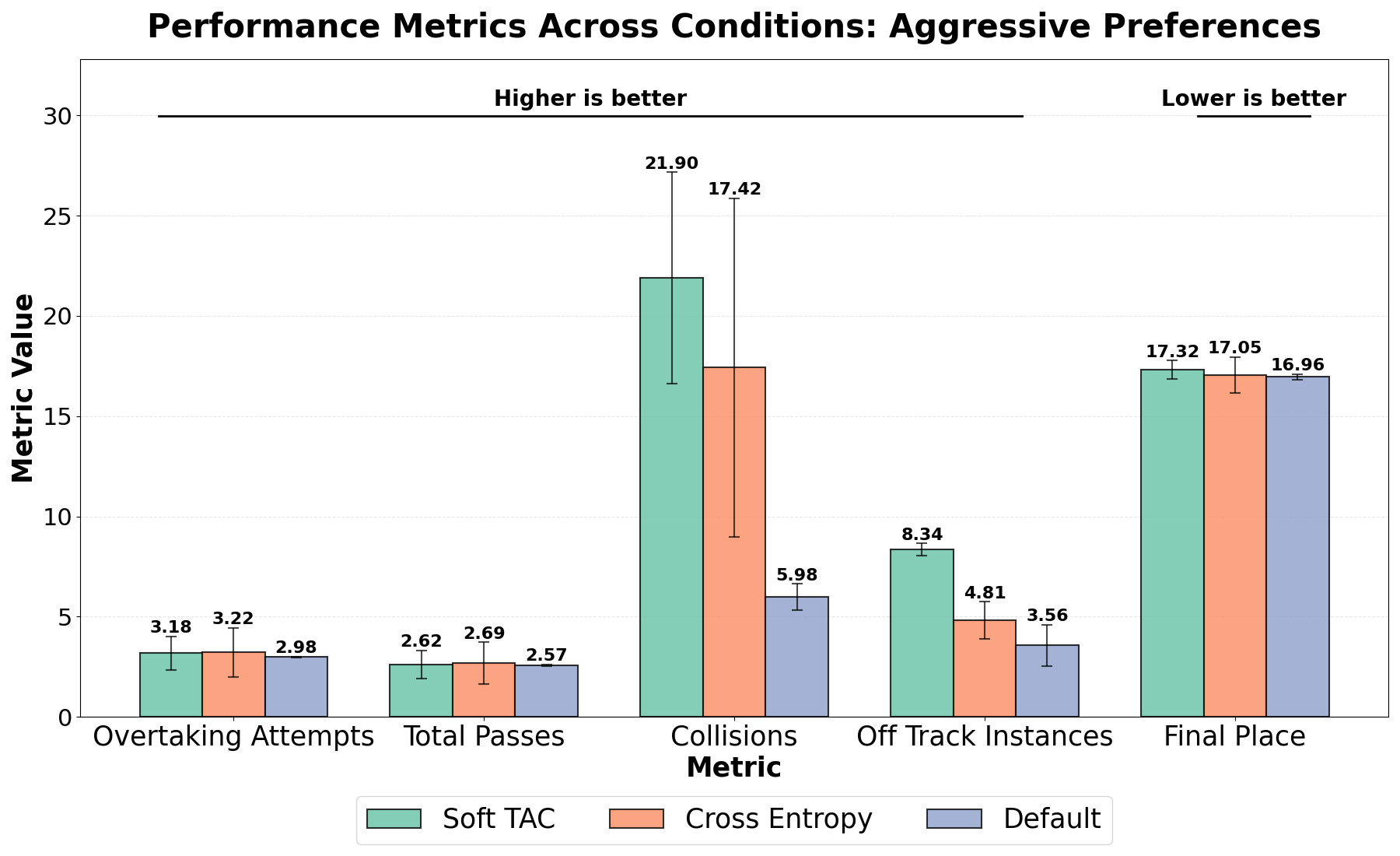
强化学习的成功与奖励函数能否准确反映任务目标密切相关。然而,设计奖励函数非常耗时且容易出错。为了解决这个问题,本文首先旨在帮助强化学习从业者为奖励函数指定合适的权重。本文利用轨迹对齐系数(TAC)来评估奖励函数诱导的偏好与领域专家偏好之间的匹配程度。通过对Lunar Lander进行人工实验,发现提供TAC可以帮助参与者产生性能更好的奖励函数,并降低认知负荷。然而,即使有TAC,手动奖励设计仍然非常耗力。因此,本文提出了Soft-TAC,一种可微的TAC近似,可以用作损失函数,从人类偏好数据中训练奖励模型。在Gran Turismo 7中验证表明,使用Soft-TAC训练的奖励模型成功地捕捉了特定偏好的目标,从而产生了比使用标准交叉熵损失训练的模型具有更高质量行为的策略。这项工作表明,TAC既可以作为指导奖励调整的实用工具,也可以作为复杂领域中的奖励学习目标。
🔬 方法详解
问题定义:强化学习依赖于精心设计的奖励函数,但手动设计奖励函数既耗时又容易出错,导致最终策略性能不佳。现有方法难以有效利用人类偏好数据来自动学习奖励函数,尤其是在复杂环境中。
核心思路:论文的核心思路是利用轨迹对齐系数(TAC)来衡量奖励函数诱导的偏好与人类专家偏好之间的匹配程度。通过最大化TAC,可以学习到更符合人类意图的奖励函数。为了实现可微优化,论文提出了Soft-TAC,作为TAC的平滑近似。
技术框架:整体框架包含两个主要阶段:1) 人工奖励函数调整实验,验证TAC作为辅助工具的有效性;2) 基于Soft-TAC的奖励模型学习。在奖励模型学习阶段,首先收集人类偏好数据,然后使用Soft-TAC作为损失函数训练奖励模型,最后使用学习到的奖励函数训练强化学习智能体。
关键创新:关键创新在于提出了Soft-TAC,它是TAC的可微近似,允许使用梯度下降等优化方法直接从人类偏好数据中学习奖励函数。与传统的交叉熵损失相比,Soft-TAC能够更好地捕捉人类偏好的细微差别,从而学习到更有效的奖励函数。
关键设计:Soft-TAC的设计基于Gumbel-Max技巧,使得原本离散的TAC计算过程变得可微。具体来说,Soft-TAC通过引入温度参数来控制近似的平滑程度。损失函数采用Soft-TAC的负值,通过最小化损失来最大化轨迹对齐程度。在Gran Turismo 7实验中,奖励模型采用神经网络结构,输入为游戏状态,输出为奖励值。
🖼️ 关键图片
📊 实验亮点
在Lunar Lander人工实验中,使用TAC辅助奖励调整的参与者获得了更高的策略性能,并报告了更低的认知负荷。在Gran Turismo 7实验中,使用Soft-TAC训练的奖励模型能够生成比使用交叉熵损失训练的模型更具区分性的策略行为,表明Soft-TAC能够有效捕捉人类偏好。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域,通过学习人类偏好来自动设计奖励函数,从而简化强化学习任务的开发流程,并提升智能体的性能和安全性。尤其适用于难以手动设计奖励函数的复杂环境。
📄 摘要(原文)
The success of reinforcement learning (RL) is fundamentally tied to having a reward function that accurately reflects the task objective. Yet, designing reward functions is notoriously time-consuming and prone to misspecification. To address this issue, our first goal is to understand how to support RL practitioners in specifying appropriate weights for a reward function. We leverage the Trajectory Alignment Coefficient (TAC), a metric that evaluates how closely a reward function's induced preferences match those of a domain expert. To evaluate whether TAC provides effective support in practice, we conducted a human-subject study in which RL practitioners tuned reward weights for Lunar Lander. We found that providing TAC during reward tuning led participants to produce more performant reward functions and report lower cognitive workload relative to standard tuning without TAC. However, the study also underscored that manual reward design, even with TAC, remains labor-intensive. This limitation motivated our second goal: to learn a reward model that maximizes TAC directly. Specifically, we propose Soft-TAC, a differentiable approximation of TAC that can be used as a loss function to train reward models from human preference data. Validated in the racing simulator Gran Turismo 7, reward models trained using Soft-TAC successfully captured preference-specific objectives, resulting in policies with qualitatively more distinct behaviors than models trained with standard Cross-Entropy loss. This work demonstrates that TAC can serve as both a practical tool for guiding reward tuning and a reward learning objective in complex domains.