GRIP: Algorithm-Agnostic Machine Unlearning for Mixture-of-Experts via Geometric Router Constraints
作者: Andy Zhu, Rongzhe Wei, Yupu Gu, Pan Li
分类: cs.LG, cs.AI
发布日期: 2026-01-23
💡 一句话要点
GRIP:通过几何路由约束实现MoE模型算法无关的机器遗忘
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器遗忘 混合专家模型 几何约束 路由稳定 AI安全
📋 核心要点
- 现有机器遗忘方法在MoE模型上表现不佳,它们通过操纵路由而非擦除知识来实现遗忘,导致模型性能下降。
- GRIP框架通过引入几何约束,将路由器梯度更新投影到专家特定的零空间,从而稳定路由选择并促进知识擦除。
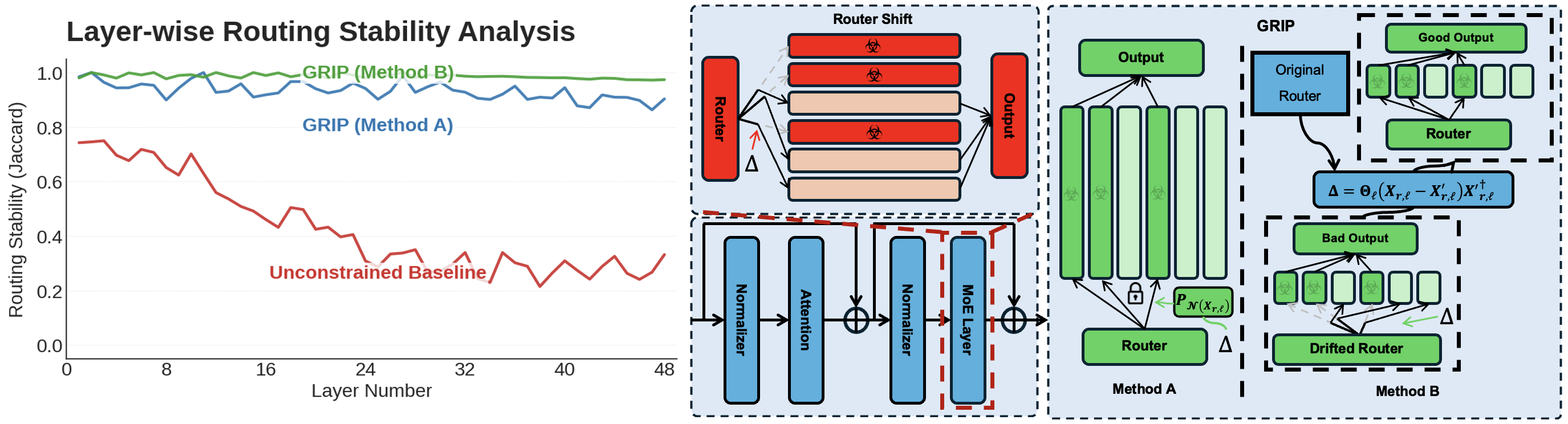
- 实验表明,GRIP能显著提升MoE模型的遗忘效果,在保持模型效用的同时,实现超过95%的路由稳定性。
📝 摘要(中文)
针对大型语言模型的机器遗忘(MU)对于AI安全至关重要,但现有方法难以泛化到混合专家(MoE)架构。我们发现,传统遗忘方法利用了MoE的架构漏洞:它们操纵路由器将查询重定向到远离知识渊博的专家,而不是真正擦除知识,导致模型效用损失和表面遗忘。我们提出了几何路由不变性保持(GRIP),这是一个用于MoE遗忘的算法无关框架。我们的核心贡献是一个几何约束,通过将路由器梯度更新投影到特定专家的零空间来实现。至关重要的是,这解耦了路由稳定性和参数刚性:虽然离散的专家选择对于保留的知识保持稳定,但连续的路由器参数在零空间内保持可塑性,允许模型进行必要的内部重配置以满足遗忘目标。这迫使遗忘优化直接从专家参数中擦除知识,而不是利用表面路由器操纵的捷径。GRIP作为一个适配器,约束路由器参数更新而不修改底层遗忘算法。在大型MoE模型上的大量实验表明,我们的适配器消除了专家选择的转移(在所有测试的遗忘方法中实现了超过95%的路由稳定性),同时保留了它们的效用。通过防止现有算法利用MoE模型的路由器漏洞,GRIP将现有的从密集架构到MoE的遗忘研究进行了调整。
🔬 方法详解
问题定义:现有机器遗忘方法在应用于混合专家模型(MoE)时,容易通过操纵路由器的行为来实现“遗忘”,而不是真正地从专家模型的参数中删除需要遗忘的知识。这种方法导致模型性能下降,并且遗忘效果不彻底,仅仅是表面上的遗忘。
核心思路:GRIP的核心思路是通过引入几何约束来稳定MoE模型中的路由选择。具体来说,它将路由器参数的梯度更新投影到特定专家的零空间中,从而保证在遗忘过程中,路由器对于保留知识的路由选择保持稳定,同时允许路由器参数在零空间内进行调整,以便模型能够进行必要的内部重配置,从而实现真正的知识擦除。
技术框架:GRIP作为一个适配器,可以与现有的机器遗忘算法结合使用。其主要流程包括:首先,计算路由器参数的梯度更新;然后,将这些梯度更新投影到特定专家的零空间中,从而得到约束后的梯度更新;最后,使用约束后的梯度更新来更新路由器参数。这个过程在不改变底层遗忘算法的前提下,有效地约束了路由器参数的更新,从而避免了对路由器的过度操纵。
关键创新:GRIP的关键创新在于提出了几何约束,并将路由器梯度更新投影到专家特定的零空间中。这种方法解耦了路由稳定性和参数刚性,使得模型能够在保持路由稳定的同时,进行必要的参数调整,从而实现真正的知识擦除。与现有方法相比,GRIP能够更有效地防止模型通过操纵路由器来实现“遗忘”,从而提高了遗忘效果和模型性能。
关键设计:GRIP的关键设计在于零空间的构建和投影操作。具体来说,对于每个专家,GRIP都会构建一个对应的零空间,该零空间包含了所有不会影响该专家路由选择的参数更新方向。然后,GRIP使用投影矩阵将路由器梯度更新投影到该零空间中,从而得到约束后的梯度更新。投影矩阵的计算依赖于专家路由选择的梯度信息,需要根据具体的MoE模型和遗忘任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GRIP能够显著提升MoE模型的遗忘效果,在所有测试的遗忘方法中实现了超过95%的路由稳定性,同时保留了模型的效用。这表明GRIP能够有效地防止模型通过操纵路由器来实现“遗忘”,从而提高了遗忘效果和模型性能。GRIP作为一个适配器,可以与现有的机器遗忘算法结合使用,具有良好的通用性和可扩展性。
🎯 应用场景
GRIP框架可应用于各种基于MoE架构的大型语言模型,以实现安全可靠的机器遗忘。这对于保护用户隐私、遵守数据法规以及防止模型泄露敏感信息至关重要。该研究成果有助于推动AI安全领域的发展,并为构建可信赖的人工智能系统奠定基础。
📄 摘要(原文)
Machine unlearning (MU) for large language models has become critical for AI safety, yet existing methods fail to generalize to Mixture-of-Experts (MoE) architectures. We identify that traditional unlearning methods exploit MoE's architectural vulnerability: they manipulate routers to redirect queries away from knowledgeable experts rather than erasing knowledge, causing a loss of model utility and superficial forgetting. We propose Geometric Routing Invariance Preservation (GRIP), an algorithm-agnostic framework for unlearning for MoE. Our core contribution is a geometric constraint, implemented by projecting router gradient updates into an expert-specific null-space. Crucially, this decouples routing stability from parameter rigidity: while discrete expert selections remain stable for retained knowledge, the continuous router parameters remain plastic within the null space, allowing the model to undergo necessary internal reconfiguration to satisfy unlearning objectives. This forces the unlearning optimization to erase knowledge directly from expert parameters rather than exploiting the superficial router manipulation shortcut. GRIP functions as an adapter, constraining router parameter updates without modifying the underlying unlearning algorithm. Extensive experiments on large-scale MoE models demonstrate that our adapter eliminates expert selection shift (achieving over 95% routing stability) across all tested unlearning methods while preserving their utility. By preventing existing algorithms from exploiting MoE model's router vulnerability, GRIP adapts existing unlearning research from dense architectures to MoEs.