Predicting Startup Success Using Large Language Models: A Novel In-Context Learning Approach
作者: Abdurahman Maarouf, Alket Bakiaj, Stefan Feuerriegel
分类: cs.LG
发布日期: 2026-01-23
💡 一句话要点
提出kNN-ICL框架,利用大语言模型解决早期创业公司成功预测的数据稀缺问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 创业公司成功预测 数据稀缺 k近邻算法
📋 核心要点
- 早期创业公司成功预测面临数据稀缺挑战,传统机器学习方法因缺乏足够标注数据而受限。
- 提出kNN-ICL框架,利用大语言模型的上下文学习能力,无需训练即可进行创业公司成功预测。
- 实验表明,kNN-ICL在真实数据集上优于监督学习基线和原始上下文学习,仅需少量示例即可达到较高精度。
📝 摘要(中文)
早期创业公司的风险投资回报潜力巨大,但由于数据稀缺(例如,许多风险投资公司仅掌握少量早期创业公司及其成功与否的信息),预测早期创业公司的成功仍然具有挑战性。这限制了依赖大型标注数据集进行模型训练的传统机器学习方法的有效性。为了解决这个问题,我们提出了一种基于大语言模型(LLM)的上下文学习框架,用于创业公司成功预测,该框架无需模型训练,仅利用少量标注的创业公司作为演示示例。具体来说,我们提出了一种新颖的基于k近邻的上下文学习框架,称为kNN-ICL,它根据相似性选择最相关的过去创业公司作为示例。使用来自Crunchbase的真实世界数据,我们发现kNN-ICL方法比监督机器学习基线和原始上下文学习实现了更高的预测准确率。此外,我们研究了性能如何随上下文示例数量变化,发现仅用50个示例即可实现较高的平衡准确率。总而言之,我们证明了上下文学习可以作为在数据稀缺环境中运营的风险投资公司的决策工具。
🔬 方法详解
问题定义:论文旨在解决早期创业公司成功预测问题。现有方法,特别是传统的监督机器学习方法,在数据稀缺的环境下表现不佳。风险投资公司通常只掌握少量早期创业公司的数据,这使得训练有效的预测模型变得困难。因此,如何利用有限的数据进行准确的创业公司成功预测是一个关键挑战。
核心思路:论文的核心思路是利用大语言模型(LLM)的上下文学习能力,通过提供少量标注示例(即成功的和失败的创业公司案例)作为上下文,让LLM学习如何预测新的创业公司是否会成功。这种方法避免了传统的模型训练过程,从而克服了数据稀缺带来的限制。通过选择与待预测创业公司最相似的已知案例作为上下文,可以提高预测的准确性。
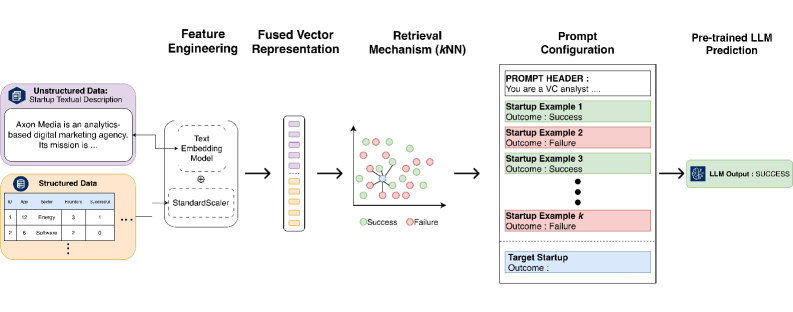
技术框架:kNN-ICL框架主要包含以下几个阶段:1) 数据准备:从Crunchbase等平台收集创业公司的信息,包括公司描述、行业、融资情况等。2) 特征提取:将创业公司的信息转换为向量表示,以便计算相似度。3) 近邻选择:使用k近邻算法(kNN)从已标注的创业公司中选择与待预测创业公司最相似的k个案例。4) 上下文构建:将选定的k个案例作为上下文,输入到大语言模型中。5) 预测:大语言模型根据上下文生成预测结果,判断待预测创业公司是否会成功。
关键创新:论文的关键创新在于提出了基于k近邻的上下文学习方法(kNN-ICL)。与传统的上下文学习方法相比,kNN-ICL能够更有效地选择相关的上下文示例,从而提高预测的准确性。传统的上下文学习通常随机选择示例,或者使用启发式方法,而kNN-ICL通过计算相似度来选择最相关的示例,这使得LLM能够更好地理解待预测创业公司的特征,并做出更准确的判断。
关键设计:kNN-ICL的关键设计包括:1) 相似度度量:选择合适的相似度度量方法(例如,余弦相似度)来计算创业公司之间的相似度。2) k值的选择:确定k近邻算法中k的值,即选择多少个最相似的示例作为上下文。3) 大语言模型的选择:选择合适的预训练大语言模型,例如GPT-3或类似的模型。4) Prompt设计:设计合适的prompt,将上下文示例和待预测创业公司输入到大语言模型中,并引导模型生成预测结果。5) 评估指标:使用平衡准确率(balanced accuracy)等指标来评估预测的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,kNN-ICL方法在创业公司成功预测任务中优于监督机器学习基线和原始上下文学习方法。具体来说,kNN-ICL在真实世界数据集上实现了更高的平衡准确率。研究还发现,仅使用50个示例作为上下文,kNN-ICL即可达到较高的预测精度,这进一步验证了该方法在数据稀缺环境下的有效性。
🎯 应用场景
该研究成果可应用于风险投资领域,帮助风险投资公司更准确地评估早期创业公司的潜力,从而做出更明智的投资决策。此外,该方法还可以扩展到其他数据稀缺的预测问题,例如新药研发、罕见病诊断等。未来,该方法可以与专家知识相结合,构建更强大的决策支持系统。
📄 摘要(原文)
Venture capital (VC) investments in early-stage startups that end up being successful can yield high returns. However, predicting early-stage startup success remains challenging due to data scarcity (e.g., many VC firms have information about only a few dozen of early-stage startups and whether they were successful). This limits the effectiveness of traditional machine learning methods that rely on large labeled datasets for model training. To address this challenge, we propose an in-context learning framework for startup success prediction using large language models (LLMs) that requires no model training and leverages only a small set of labeled startups as demonstration examples. Specifically, we propose a novel k-nearest-neighbor-based in-context learning framework, called kNN-ICL, which selects the most relevant past startups as examples based on similarity. Using real-world profiles from Crunchbase, we find that the kNN-ICL approach achieves higher prediction accuracy than supervised machine learning baselines and vanilla in-context learning. Further, we study how performance varies with the number of in-context examples and find that a high balanced accuracy can be achieved with as few as 50 examples. Together, we demonstrate that in-context learning can serve as a decision-making tool for VC firms operating in data-scarce environments.