Beyond Superficial Unlearning: Sharpness-Aware Robust Erasure of Hallucinations in Multimodal LLMs
作者: Xianya Fang, Feiyang Ren, Xiang Chen, Yu Tian, Zhen Bi, Haiyang Yu, Sheng-Jun Huang
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2026-01-23
💡 一句话要点
提出SARE,通过对抗扰动增强多模态LLM的幻觉消除鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 幻觉消除 对抗学习 鲁棒性 损失面平滑
📋 核心要点
- 多模态LLM易产生幻觉,现有消除方法仅能实现表面抑制,模型易受扰动影响。
- SARE将消除学习视为min-max优化,通过Targeted-SAM平滑损失面,增强模型鲁棒性。
- 实验表明,SARE在擦除效果上优于基线,并能抵抗重学习和参数更新,验证有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)功能强大,但容易产生对象幻觉,即描述不存在的实体,从而损害可靠性。现有的消除幻觉方法存在结构脆弱性。本文证明,标准的擦除方法只能实现表面的抑制,模型容易陷入尖锐的极小值,在轻量级的重新学习后,幻觉会灾难性地复现。为了确保几何稳定性,本文提出了SARE,将消除学习视为一个有针对性的min-max优化问题,并使用Targeted-SAM机制来显式地平滑幻觉概念周围的损失面。通过在模拟的最坏情况参数扰动下抑制幻觉,该框架确保了针对权重偏移的鲁棒性消除。大量实验表明,SARE在擦除效果方面显著优于基线方法,同时保持了一般的生成质量。重要的是,它保持了对重新学习和参数更新的持续幻觉抑制,验证了几何稳定化的有效性。
🔬 方法详解
问题定义:多模态大型语言模型(MLLM)容易产生对象幻觉,即生成描述不存在的实体的文本,这会严重影响模型的可信度和可靠性。现有的消除幻觉方法虽然尝试缓解这个问题,但存在结构脆弱性,只能实现表面的抑制,模型容易陷入损失面的尖锐极小值,导致在经过轻微的重学习后,幻觉会再次出现。
核心思路:本文的核心思路是将消除学习问题转化为一个有针对性的min-max优化问题。通过显式地平滑幻觉概念周围的损失面,使得模型在参数扰动下依然能够保持较低的幻觉生成概率。这种方法旨在提高消除学习的鲁棒性,防止模型在重学习或参数更新后重新产生幻觉。
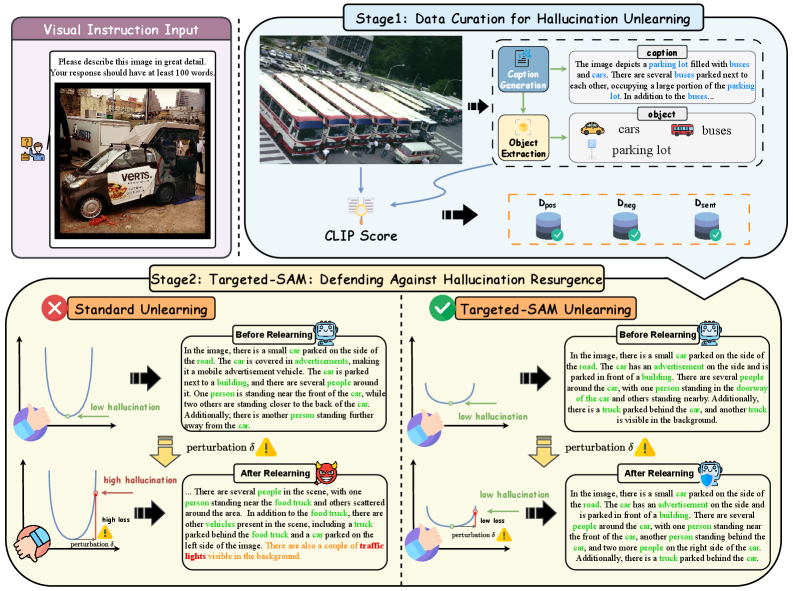
技术框架:SARE (Sharpness-Aware Robust Erasure) 框架主要包含两个关键部分:1) 目标幻觉识别与定位;2) 基于Targeted-SAM的min-max优化。首先,需要确定需要消除的特定幻觉概念。然后,利用Targeted-SAM机制,在幻觉概念周围的参数空间中寻找损失函数的最大值,并以此来更新模型参数,从而平滑损失面。这个过程可以迭代进行,直到达到预定的消除效果。
关键创新:SARE最重要的技术创新在于其将消除学习与损失面平滑相结合,通过对抗扰动来增强消除学习的鲁棒性。与传统的消除学习方法不同,SARE不仅仅关注在当前参数下的幻觉消除,更关注在参数扰动下的幻觉抑制,从而避免模型陷入尖锐的极小值。Targeted-SAM机制是实现这一目标的关键,它能够有效地在目标概念周围平滑损失面。
关键设计:SARE的关键设计包括:1) Targeted-SAM机制,用于在幻觉概念周围寻找损失函数的最大值,并以此来更新模型参数;2) min-max优化目标,旨在最小化模型在最坏情况参数扰动下的幻觉生成概率;3) 损失函数的设计,需要同时考虑幻觉消除的效果和对模型整体性能的影响。具体的参数设置和网络结构取决于所使用的多模态LLM,但SARE的框架可以灵活地应用于不同的模型。
🖼️ 关键图片

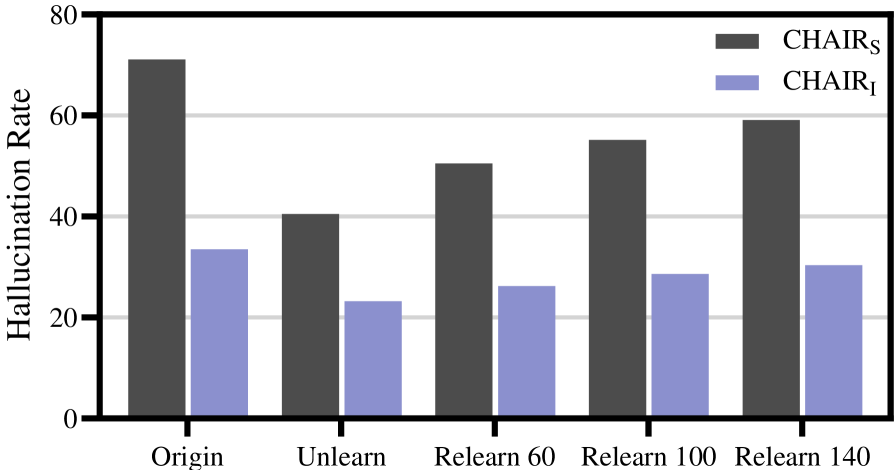
📊 实验亮点
实验结果表明,SARE在幻觉消除效果方面显著优于基线方法,并且能够有效地抵抗重学习和参数更新带来的影响。具体而言,SARE在保持生成质量的同时,能够更彻底地消除目标幻觉,并且在经过多次重学习后,幻觉复现的概率明显低于其他方法。这些结果验证了SARE在几何稳定化方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要高度可靠性的多模态LLM应用场景,例如医疗诊断、自动驾驶、金融分析等。通过消除模型中的幻觉,可以提高决策的准确性和安全性,减少潜在的风险。此外,该方法还可以用于提高模型的泛化能力和鲁棒性,使其在面对新的数据和环境时表现更加稳定。
📄 摘要(原文)
Multimodal LLMs are powerful but prone to object hallucinations, which describe non-existent entities and harm reliability. While recent unlearning methods attempt to mitigate this, we identify a critical flaw: structural fragility. We empirically demonstrate that standard erasure achieves only superficial suppression, trapping the model in sharp minima where hallucinations catastrophically resurge after lightweight relearning. To ensure geometric stability, we propose SARE, which casts unlearning as a targeted min-max optimization problem and uses a Targeted-SAM mechanism to explicitly flatten the loss landscape around hallucinated concepts. By suppressing hallucinations under simulated worst-case parameter perturbations, our framework ensures robust removal stable against weight shifts. Extensive experiments demonstrate that SARE significantly outperforms baselines in erasure efficacy while preserving general generation quality. Crucially, it maintains persistent hallucination suppression against relearning and parameter updates, validating the effectiveness of geometric stabilization.