Rethinking Large Language Models For Irregular Time Series Classification In Critical Care
作者: Feixiang Zheng, Yu Wu, Cecilia Mascolo, Ting Dang
分类: cs.LG
发布日期: 2026-01-23
备注: 5 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
针对ICU不规则时间序列分类,研究并优化大语言模型中的编码器与对齐策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分类 大型语言模型 不规则数据 重症监护 编码器设计 多模态对齐 缺失值处理
📋 核心要点
- ICU时间序列数据具有高缺失率,现有LLM方法对此类不规则数据的有效性有待考察。
- 论文通过系统性实验,着重研究LLM中时间序列编码器和多模态对齐策略对性能的影响。
- 实验表明,显式建模不规则性的编码器能显著提升性能,但LLM方法训练成本高且少样本学习能力不足。
📝 摘要(中文)
重症监护病房(ICU)的时间序列数据为患者监护提供了关键信息。尽管最近将大型语言模型(LLM)应用于时间序列建模(TSM)的进展显示出巨大的前景,但它们在不规则ICU数据上的有效性,尤其以高缺失值率为特征,仍未得到充分探索。本文研究了LLM用于TSM成功的两个关键组成部分:时间序列编码器和多模态对齐策略。为此,我们建立了一个系统的测试平台,以评估它们对各种最先进的基于LLM的方法在基准ICU数据集上的影响,并与强大的监督和自监督基线进行比较。结果表明,编码器设计比对齐策略更关键。显式建模不规则性的编码器实现了显著的性能提升,平均AUPRC比原始Transformer提高了12.8%。虽然影响较小,但对齐策略也值得关注,性能最佳的语义丰富、基于融合的策略比交叉注意力略有提高2.9%。然而,基于LLM的方法需要至少10倍于性能最佳的不规则监督模型的训练时间,同时仅提供相当的性能。它们在数据稀缺的少样本学习环境中也表现不佳。这些发现突出了LLM在不规则ICU时间序列中的希望和当前局限性。代码可在https://github.com/mHealthUnimelb/LLMTS获得。
🔬 方法详解
问题定义:论文旨在解决ICU场景下,利用大语言模型进行不规则时间序列分类的问题。现有方法在处理高缺失率的ICU数据时效果不佳,无法充分利用LLM的潜力。痛点在于如何有效地对不规则时间序列进行编码,并将其与LLM的语义空间对齐。
核心思路:论文的核心思路是分别研究和优化LLM用于时间序列建模的两个关键组件:时间序列编码器和多模态对齐策略。通过对比不同的编码器设计和对齐策略,找出最适合处理不规则ICU时间序列数据的方法。重点关注显式建模数据不规则性的编码器,以及能够有效融合时间序列特征和LLM语义信息的对齐策略。
技术框架:整体框架包含三个主要阶段:1) 时间序列编码阶段,使用不同的编码器(如Transformer、Informer、显式建模不规则性的编码器)将原始时间序列数据转换为向量表示;2) 多模态对齐阶段,利用不同的对齐策略(如交叉注意力、语义融合)将时间序列的向量表示与LLM的语义空间对齐;3) 分类阶段,利用对齐后的特征进行分类预测。
关键创新:论文最重要的技术创新点在于对时间序列编码器和多模态对齐策略的解耦研究,并验证了显式建模不规则性的编码器对于提升性能至关重要。与现有方法相比,该研究更系统地分析了LLM在不规则时间序列分类中的作用,并为未来的研究方向提供了指导。
关键设计:论文的关键设计包括:1) 针对不规则时间序列,采用了能够显式建模缺失模式的编码器,例如基于掩码的Transformer变体;2) 在多模态对齐方面,探索了基于语义融合的策略,将时间序列特征与LLM的语义信息进行更有效的融合;3) 实验中,对不同的编码器和对齐策略进行了充分的对比,并评估了它们在不同数据量下的性能表现。
🖼️ 关键图片

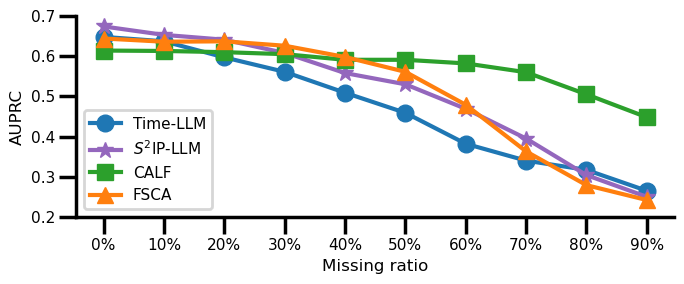
📊 实验亮点
实验结果表明,显式建模不规则性的编码器设计能够显著提升性能,平均AUPRC比原始Transformer提高了12.8%。最佳的语义融合对齐策略也带来了2.9%的性能提升。然而,基于LLM的方法需要至少10倍于最佳监督模型的训练时间,且在少样本学习场景下表现不佳,揭示了LLM在不规则时间序列分类中的局限性。
🎯 应用场景
该研究成果可应用于智能医疗领域,例如ICU患者的病情预测、风险评估和个性化治疗方案制定。通过更有效地利用ICU时间序列数据,可以提高医疗决策的准确性和效率,改善患者的治疗效果。未来,该方法还可以扩展到其他具有不规则时间序列数据的领域,如金融风控、工业监控等。
📄 摘要(原文)
Time series data from the Intensive Care Unit (ICU) provides critical information for patient monitoring. While recent advancements in applying Large Language Models (LLMs) to time series modeling (TSM) have shown great promise, their effectiveness on the irregular ICU data, characterized by particularly high rates of missing values, remains largely unexplored. This work investigates two key components underlying the success of LLMs for TSM: the time series encoder and the multimodal alignment strategy. To this end, we establish a systematic testbed to evaluate their impact across various state-of-the-art LLM-based methods on benchmark ICU datasets against strong supervised and self-supervised baselines. Results reveal that the encoder design is more critical than the alignment strategy. Encoders that explicitly model irregularity achieve substantial performance gains, yielding an average AUPRC increase of $12.8\%$ over the vanilla Transformer. While less impactful, the alignment strategy is also noteworthy, with the best-performing semantically rich, fusion-based strategy achieving a modest $2.9\%$ improvement over cross-attention. However, LLM-based methods require at least 10$\times$ longer training than the best-performing irregular supervised models, while delivering only comparable performance. They also underperform in data-scarce few-shot learning settings. These findings highlight both the promise and current limitations of LLMs for irregular ICU time series. The code is available at https://github.com/mHealthUnimelb/LLMTS.