Towards a Theoretical Understanding to the Generalization of RLHF
作者: Zhaochun Li, Mingyang Yi, Yue Wang, Shisheng Cui, Yong Liu
分类: cs.LG
发布日期: 2026-01-23
备注: 31 pages, 6 figures
💡 一句话要点
提出RLHF理论框架以解决高维设置中的泛化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 泛化理论 算法稳定性 大型语言模型
📋 核心要点
- 现有的RLHF方法在高维设置中的理论泛化特性尚未得到充分探索,限制了其应用和理解。
- 本文提出了一种基于算法稳定性的理论框架,分析RLHF在端到端学习中的泛化能力,提供了新的视角。
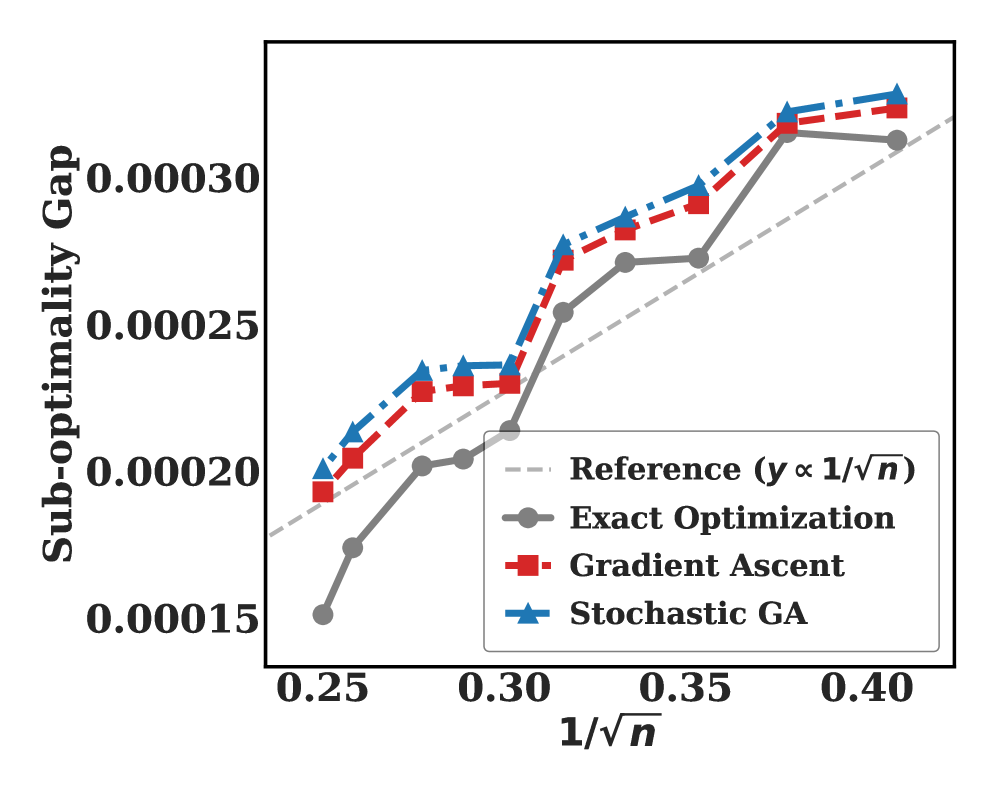
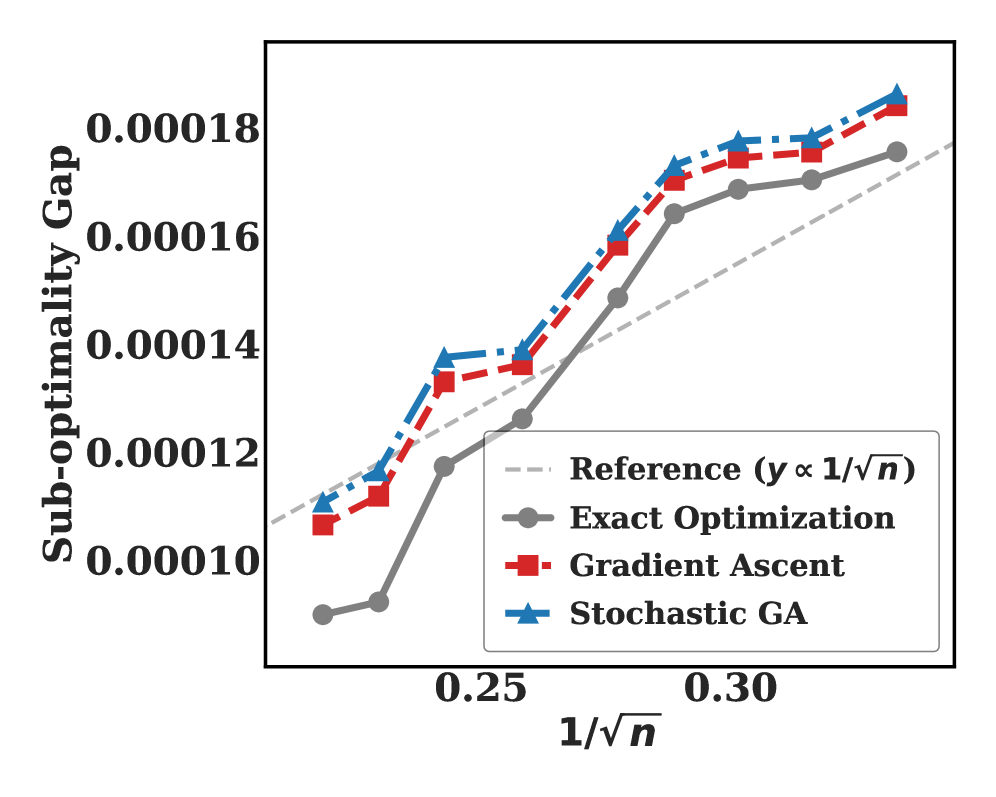
- 研究结果表明,在特征覆盖条件下,策略模型的泛化界限为$ extmath{O}(n^{- rac{1}{2}})$,为RLHF的有效性提供了理论支持。
📝 摘要(中文)
强化学习与人类反馈(RLHF)及其变体已成为将大型语言模型与人类意图对齐的主流方法。尽管在实践中有效,但这些方法在高维设置中的理论泛化特性尚待探讨。为此,本文在线性奖励模型下构建了RLHF的泛化理论,采用算法稳定性的框架。与现有基于最大似然估计一致性的研究不同,我们的分析在端到端学习框架下进行,符合实际应用。具体而言,我们证明在关键的特征覆盖条件下,策略模型的经验最优解具有$ extmath{O}(n^{- rac{1}{2}})$的泛化界限。此外,结果可推广至通过基于梯度的学习算法获得的参数,如梯度上升(GA)和随机梯度上升(SGA)。因此,我们认为我们的结果为RLHF后大型语言模型的经验泛化提供了新的理论证据。
🔬 方法详解
问题定义:本文旨在解决现有RLHF方法在高维设置中的理论泛化能力不足的问题,现有研究多集中于经验结果,缺乏理论支撑。
核心思路:通过构建基于算法稳定性的理论框架,分析RLHF在端到端学习中的泛化特性,强调特征覆盖条件的重要性。
技术框架:整体架构包括线性奖励模型和策略模型的优化过程,采用算法稳定性理论来推导泛化界限。主要模块包括特征提取、奖励模型构建和策略优化。
关键创新:本文的主要创新在于将算法稳定性理论应用于RLHF的泛化分析,提供了与现有基于最大似然估计方法的本质区别。
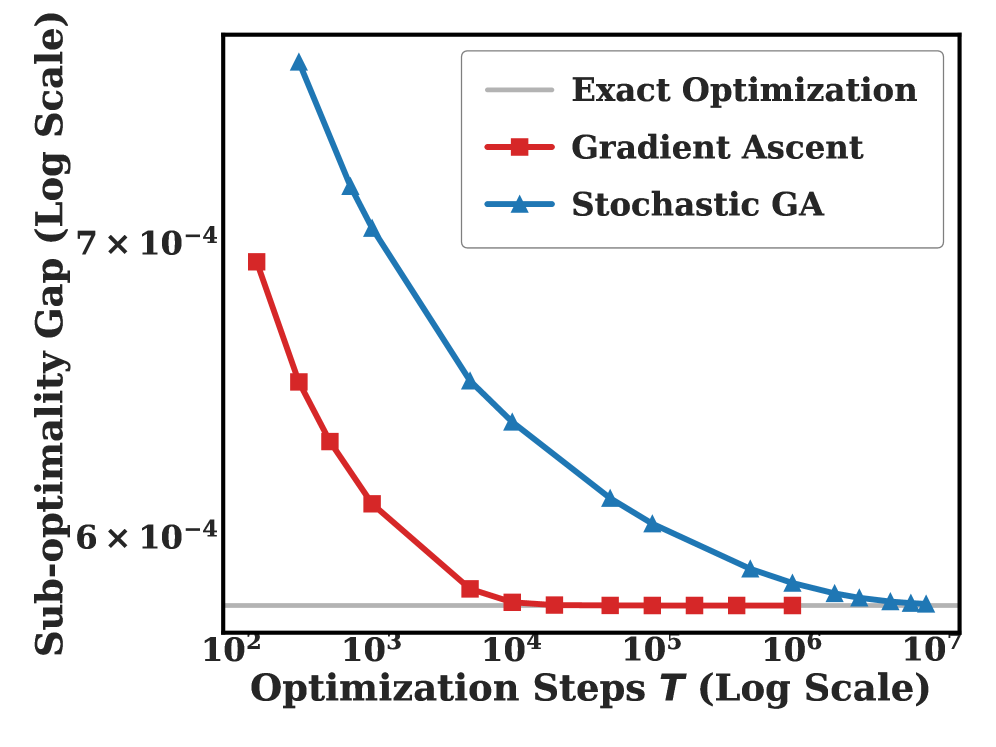
关键设计:在模型训练中,设置了特征覆盖条件,并采用了梯度上升和随机梯度上升算法进行参数优化,确保了理论分析与实际应用的一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在特征覆盖条件下,策略模型的泛化界限为$ extmath{O}(n^{- rac{1}{2}})$,与现有方法相比,提供了更为严谨的理论支持,验证了RLHF在大型语言模型中的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和人机交互等,能够帮助提升大型语言模型在实际应用中的泛化能力和可靠性。未来,随着RLHF方法的进一步发展,可能会在更多复杂任务中实现更好的性能。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) and its variants have emerged as the dominant approaches for aligning Large Language Models with human intent. While empirically effective, the theoretical generalization properties of these methods in high-dimensional settings remain to be explored. To this end, we build the generalization theory on RLHF of LLMs under the linear reward model, through the framework of algorithmic stability. In contrast to the existing works built upon the consistency of maximum likelihood estimations on reward model, our analysis is presented under an end-to-end learning framework, which is consistent with practice. Concretely, we prove that under a key \textbf{feature coverage} condition, the empirical optima of policy model have a generalization bound of order $\mathcal{O}(n^{-\frac{1}{2}})$. Moreover, the results can be extrapolated to parameters obtained by gradient-based learning algorithms, i.e., Gradient Ascent (GA) and Stochastic Gradient Ascent (SGA). Thus, we argue that our results provide new theoretical evidence for the empirically observed generalization of LLMs after RLHF.