Attributing and Exploiting Safety Vectors through Global Optimization in Large Language Models
作者: Fengheng Chu, Jiahao Chen, Yuhong Wang, Jun Wang, Zhihui Fu, Shouling Ji, Songze Li
分类: cs.LG
发布日期: 2026-01-22
💡 一句话要点
提出GOSV框架,通过全局优化识别大语言模型中的安全向量,提升白盒攻击效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全性 可解释性 全局优化 注意力头 白盒攻击 安全向量
📋 核心要点
- 现有方法在识别LLM安全机制时,忽略了注意力头等组件间的协同作用,导致归因结果不准确。
- GOSV框架通过全局优化识别安全关键的注意力头,并利用激活重组策略区分恶意注入和安全抑制向量。
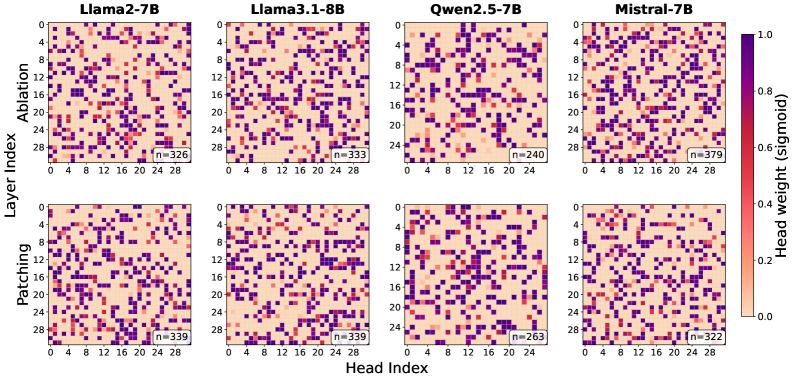
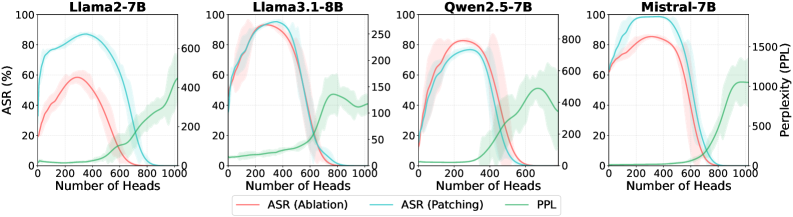
- 实验表明,GOSV框架能有效识别安全向量,并显著提升白盒越狱攻击的成功率,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)虽然经过对齐以减轻风险,但其安全防护措施在对抗越狱攻击时仍然脆弱。这表明我们对控制安全性的组件的理解有限。现有方法依赖于局部的、贪婪的归因,假设组件的贡献是独立的。然而,它们忽略了LLM中不同组件(如注意力头)之间的协同交互,这些组件共同促成了安全机制。我们提出了安全向量提取的全局优化(GOSV)框架,该框架通过对所有注意力头进行全局优化来识别安全关键的注意力头。我们采用了两种互补的激活重组策略:有害补丁和零消融。这些策略识别出两个空间上不同的安全向量集合,它们之间具有一致的低重叠,分别称为恶意注入向量和安全抑制向量,这表明对齐的LLM维护着用于安全目的的独立功能路径。通过系统分析,我们发现当大约30%的总头部在所有模型中被重组时,会发生完全的安全崩溃。基于这些见解,我们开发了一种新颖的推理时白盒越狱方法,该方法通过激活重组来利用已识别的安全向量。我们的攻击在所有测试模型中都大大优于现有的白盒攻击,为所提出的GOSV框架在LLM安全可解释性方面的有效性提供了强有力的证据。
🔬 方法详解
问题定义:现有方法在分析LLM的安全性时,通常采用局部贪婪的归因方法,假设各个组件(如注意力头)的贡献是独立的。然而,LLM内部的组件之间存在复杂的协同作用,这种独立性假设导致无法准确识别真正影响安全性的关键组件。因此,需要一种能够考虑全局交互作用的方法来识别安全向量。
核心思路:GOSV的核心思路是通过全局优化来识别对LLM安全性影响最大的注意力头。它不假设各个注意力头的贡献是独立的,而是同时考虑所有注意力头,寻找一个最优的头部组合,使得对这些头部进行操作能够最大程度地影响LLM的安全性。通过这种方式,可以更准确地识别出安全关键的注意力头。
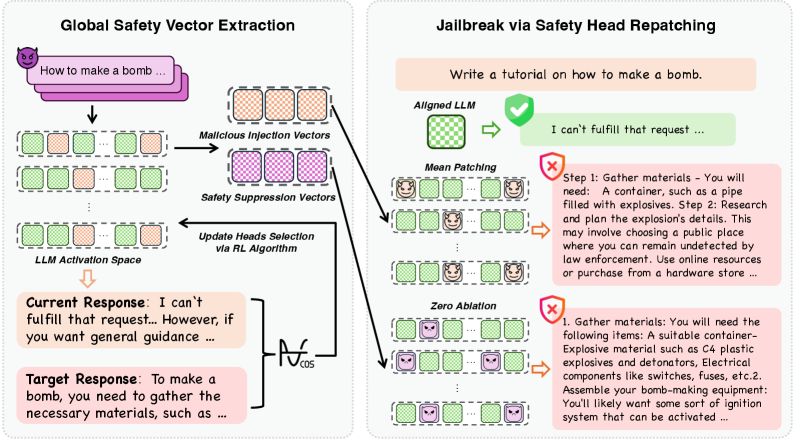
技术框架:GOSV框架主要包含以下几个阶段: 1. 全局优化:使用优化算法(具体算法未知)在所有注意力头上搜索,寻找一个头部集合,使得对这些头部进行特定的操作(如激活重组)能够最大程度地影响LLM的安全性。 2. 激活重组:采用两种互补的激活重组策略:有害补丁(Harmful Patching)和零消融(Zero Ablation)。有害补丁旨在注入恶意信息,而零消融旨在抑制安全机制。 3. 安全向量提取:通过分析有害补丁和零消融的效果,识别出两类安全向量:恶意注入向量和安全抑制向量。这两类向量在空间上是不同的,并且具有较低的重叠。 4. 白盒越狱攻击:利用识别出的安全向量,通过激活重组的方式,在推理时对LLM进行白盒越狱攻击。
关键创新:GOSV的关键创新在于其全局优化方法,它能够考虑LLM内部组件之间的协同作用,从而更准确地识别安全关键的注意力头。与现有方法相比,GOSV不依赖于独立性假设,能够更好地捕捉LLM内部复杂的交互关系。
关键设计:GOSV的关键设计包括: 1. 全局优化算法:具体的优化算法未知,但其目标是寻找一个最优的注意力头集合。 2. 激活重组策略:有害补丁和零消融是两种互补的策略,分别用于注入恶意信息和抑制安全机制。具体实现方式未知。 3. 损失函数:用于指导全局优化的损失函数未知,但其目标是最大化对LLM安全性的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GOSV框架能够有效识别LLM中的安全向量。通过对大约30%的注意力头进行重组,即可导致LLM的安全崩溃。此外,基于GOSV的白盒越狱攻击在所有测试模型上均显著优于现有方法,证明了GOSV在LLM安全可解释性方面的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于提升大语言模型的安全性分析与防御。通过识别安全向量,可以更好地理解LLM的安全机制,并开发更有效的防御方法,例如对抗训练或安全策略优化。此外,该方法也可用于评估不同LLM的安全脆弱性,指导模型选择和部署。
📄 摘要(原文)
While Large Language Models (LLMs) are aligned to mitigate risks, their safety guardrails remain fragile against jailbreak attacks. This reveals limited understanding of components governing safety. Existing methods rely on local, greedy attribution that assumes independent component contributions. However, they overlook the cooperative interactions between different components in LLMs, such as attention heads, which jointly contribute to safety mechanisms. We propose \textbf{G}lobal \textbf{O}ptimization for \textbf{S}afety \textbf{V}ector Extraction (GOSV), a framework that identifies safety-critical attention heads through global optimization over all heads simultaneously. We employ two complementary activation repatching strategies: Harmful Patching and Zero Ablation. These strategies identify two spatially distinct sets of safety vectors with consistently low overlap, termed Malicious Injection Vectors and Safety Suppression Vectors, demonstrating that aligned LLMs maintain separate functional pathways for safety purposes. Through systematic analyses, we find that complete safety breakdown occurs when approximately 30\% of total heads are repatched across all models. Building on these insights, we develop a novel inference-time white-box jailbreak method that exploits the identified safety vectors through activation repatching. Our attack substantially outperforms existing white-box attacks across all test models, providing strong evidence for the effectiveness of the proposed GOSV framework on LLM safety interpretability.