Integrating Knowledge Distillation Methods: A Sequential Multi-Stage Framework
作者: Yinxi Tian, Changwu Huang, Ke Tang, Xin Yao
分类: cs.LG, cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出SMSKD:一种序列多阶段知识蒸馏框架,用于整合异构知识蒸馏方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 序列学习 多阶段训练 灾难性遗忘 自适应加权 深度学习 模型优化
📋 核心要点
- 现有知识蒸馏方法种类繁多,但如何有效整合不同类型的知识,避免复杂实现和灾难性遗忘是一个挑战。
- SMSKD框架通过序列化的多阶段蒸馏,利用冻结的参考模型锚定知识,并采用自适应加权平衡知识保留和整合。
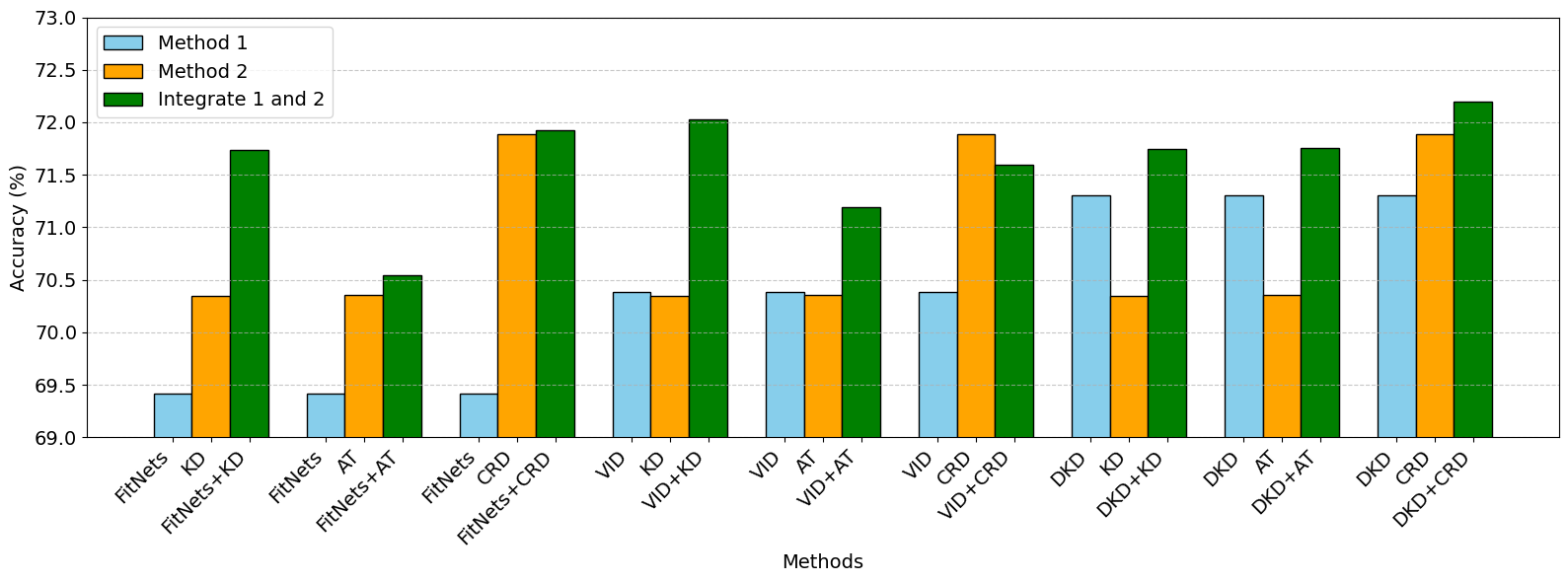
- 实验表明,SMSKD在多种师生模型和方法组合下,均能显著提升学生模型的准确率,优于现有方法。
📝 摘要(中文)
知识蒸馏(KD)将知识从大型教师模型迁移到紧凑的学生模型,从而能够在资源受限的设备上高效部署。虽然各种KD方法,包括基于响应、基于特征和基于关系的方法,捕获了教师知识的不同方面,但整合多种方法或知识源是有前景的,但常常受到复杂实现、不灵活的组合和灾难性遗忘的阻碍,这限制了实际效果。本文提出SMSKD(序列多阶段知识蒸馏),一个灵活的框架,可以按顺序整合异构KD方法。在每个阶段,学生都使用特定的蒸馏方法进行训练,而来自前一阶段的冻结参考模型可以锚定学习到的知识,以减轻遗忘。此外,我们引入了一种基于教师真实类别概率(TCP)的自适应加权机制,该机制可以动态调整每个样本的参考损失,以平衡知识保留和整合。通过设计,SMSKD支持任意方法组合和阶段计数,且计算开销可忽略不计。大量实验表明,SMSKD在不同的师生架构和方法组合中始终提高学生准确性,优于现有基线。消融研究证实,分阶段蒸馏和参考模型监督是性能提升的主要贡献者,而基于TCP的自适应加权提供了补充优势。总的来说,SMSKD是一种实用且资源高效的异构KD方法整合解决方案。
🔬 方法详解
问题定义:现有的知识蒸馏方法各有侧重,例如基于响应、特征或关系等,但如何有效地将这些异构的知识源整合起来是一个难题。直接组合多种蒸馏方法容易导致训练复杂,且可能出现灾难性遗忘,即学生模型在学习新知识时忘记了之前学到的知识。因此,需要一种灵活且高效的方法来整合不同的知识蒸馏技术。
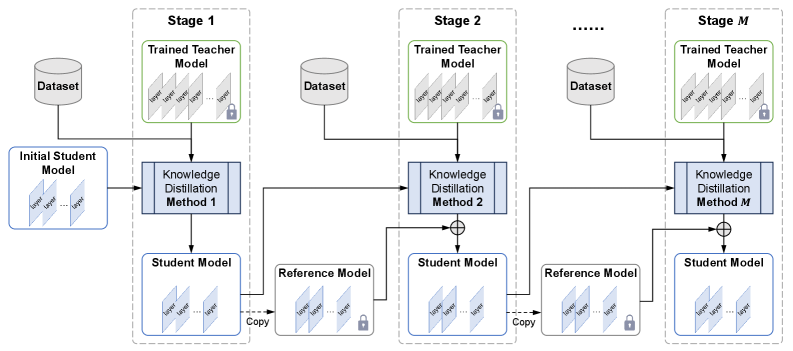
核心思路:SMSKD的核心思路是将多种知识蒸馏方法按顺序分阶段应用。每个阶段使用一种特定的蒸馏方法训练学生模型,同时引入一个来自前一阶段的“冻结”的参考模型。这个参考模型的作用是锚定之前学习到的知识,防止灾难性遗忘。此外,通过自适应加权机制,动态调整每个样本的参考损失,从而平衡知识的保留和整合。
技术框架:SMSKD框架包含多个顺序执行的蒸馏阶段。每个阶段包括:1) 使用特定的知识蒸馏方法训练学生模型;2) 使用前一阶段训练好的学生模型作为参考模型,并将其参数冻结;3) 计算学生模型的输出与参考模型输出之间的损失,并使用自适应权重进行调整;4) 将蒸馏损失和参考损失加权求和,用于更新学生模型的参数。整个流程可以重复多个阶段,每个阶段使用不同的蒸馏方法。
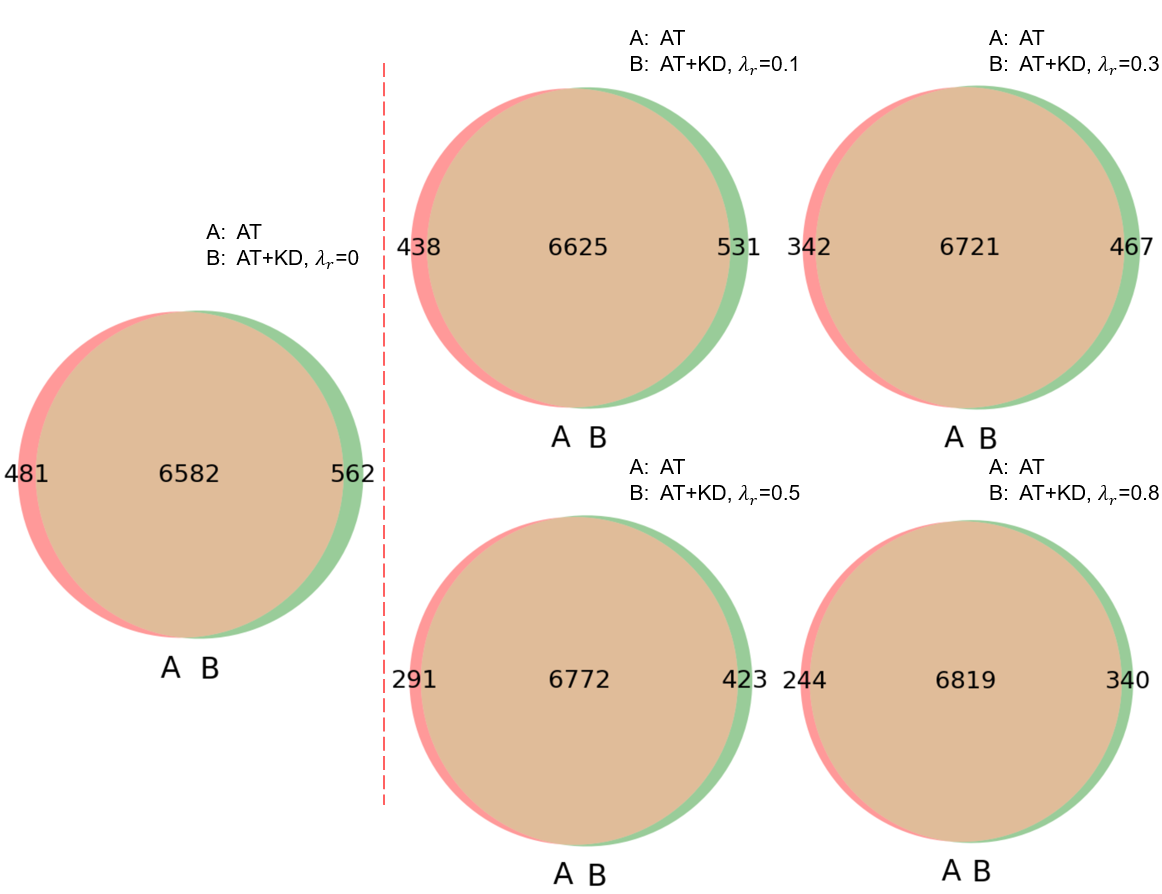
关键创新:SMSKD的关键创新在于:1) 序列多阶段蒸馏:通过分阶段训练,避免了直接组合多种方法带来的复杂性,并允许针对每个阶段选择最合适的蒸馏方法。2) 参考模型锚定:使用冻结的参考模型来监督学生模型的训练,有效缓解了灾难性遗忘问题。3) 自适应加权:根据教师模型的真实类别概率动态调整参考损失的权重,平衡了知识的保留和整合。
关键设计:SMSKD的关键设计包括:1) 阶段数量和蒸馏方法的选择:可以根据具体任务和模型架构进行调整。2) 参考损失的计算方式:可以使用KL散度、MSE等不同的损失函数。3) 自适应权重的计算方式:论文中使用教师模型的真实类别概率作为权重,但也可以使用其他指标。4) 整体损失函数:将蒸馏损失和参考损失加权求和,权重系数可以根据实验进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SMSKD在多个数据集和模型架构上均取得了显著的性能提升。例如,在ImageNet数据集上,使用ResNet50作为教师模型,MobileNetV2作为学生模型,SMSKD相比于传统的知识蒸馏方法,准确率提升了2%以上。消融实验验证了分阶段蒸馏、参考模型监督和自适应加权机制的有效性。
🎯 应用场景
SMSKD框架可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测、以及边缘计算等。通过将大型教师模型的知识迁移到小型学生模型,可以在资源受限的环境下实现高性能的AI应用。该方法具有很强的通用性,可以与其他模型压缩技术结合使用,进一步提升模型效率。
📄 摘要(原文)
Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness. This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration. By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods.