Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
作者: Zhiwei Zhang, Fei Zhao, Rui Wang, Zezhong Wang, Bin Liang, Jiakang Wang, Yao Hu, Shaosheng Cao, Kam-Fai Wong
分类: cs.LG, cs.AI
发布日期: 2026-01-22
备注: 8 pages, 4 figures, 2 tables
💡 一句话要点
Fission-GRPO:通过分解错误轨迹和在线重采样,提升LLM工具使用中的错误恢复能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 错误恢复 强化学习 在线学习 轨迹分解 错误模拟 GRPO
📋 核心要点
- 现有方法在LLM工具使用中,对执行错误的恢复能力不足,导致多轮交互中容易失败。
- Fission-GRPO通过分解错误轨迹,并结合错误模拟器和在线重采样,将错误转化为纠正监督信号。
- 实验表明,Fission-GRPO显著提升了LLM在工具使用任务中的错误恢复率和整体准确率。
📝 摘要(中文)
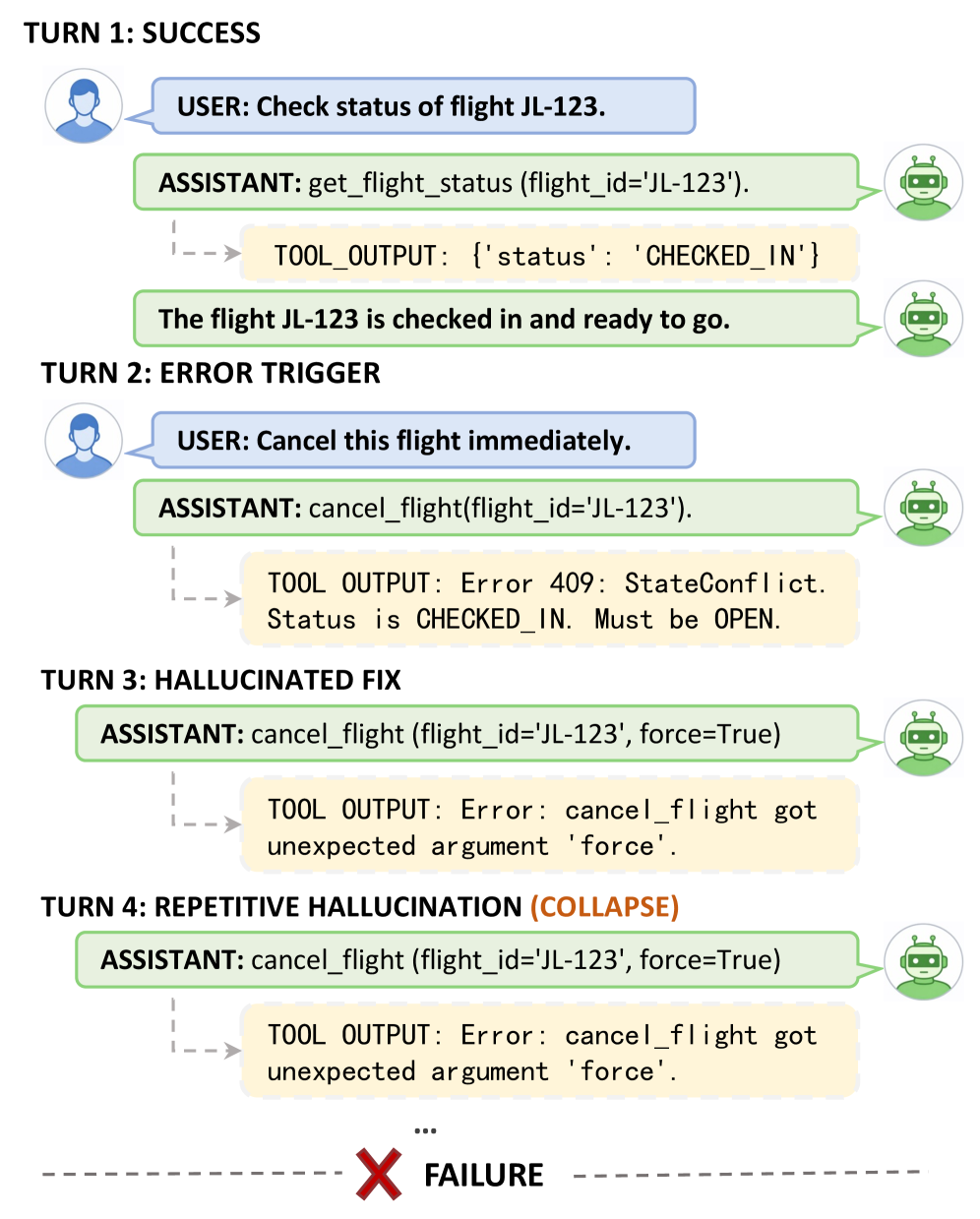
大型语言模型(LLMs)在工具调用方面表现出色,但在多轮执行中仍然脆弱:在工具调用出错后,较小的模型经常退化为重复的无效重调用,无法解释错误反馈并进行自我纠正。这种脆弱性阻碍了可靠的实际部署,因为工具交互过程中不可避免地会出现执行错误。我们发现当前方法的一个关键限制:标准的强化学习(RL)将错误视为稀疏的负奖励,没有提供关于如何恢复的指导,而预先收集的合成错误纠正数据集与模型的在线错误模式存在分布不匹配。为了弥合这一差距,我们提出了Fission-GRPO,这是一个在RL训练循环中将执行错误转换为纠正监督的框架。我们的核心机制通过使用微调的错误模拟器提供的诊断反馈来扩充每个失败的轨迹,从而将每个失败的轨迹分解为一个新的训练实例,然后在策略上重新采样恢复rollout。这使得模型能够从探索过程中产生的精确错误中学习,而不是从静态的、预先收集的错误案例中学习。在BFCL v4 Multi-Turn上,Fission-GRPO将Qwen3-8B的错误恢复率提高了5.7%,关键是,与GRPO相比,总体准确率提高了4%(从42.75%提高到46.75%),并且优于专门的工具使用代理。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多轮工具使用过程中,由于执行错误导致的性能下降问题。现有方法,如标准强化学习,将错误视为稀疏负奖励,缺乏有效的错误恢复指导。而预先收集的合成错误纠正数据集,又存在与模型实际在线错误模式的分布不匹配问题。这些问题导致LLM在实际应用中,难以从错误中学习并进行自我纠正。
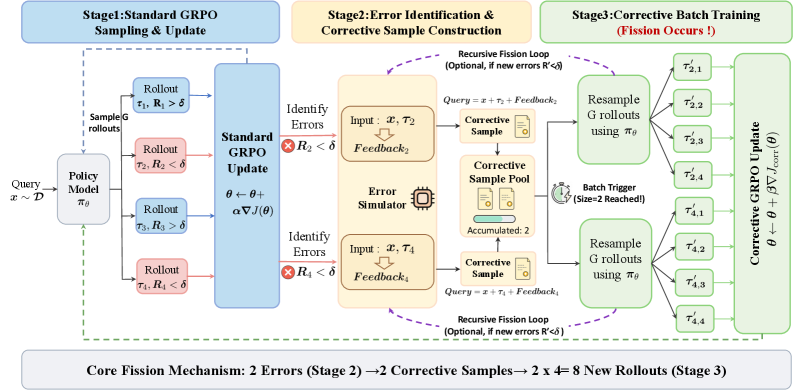
核心思路:Fission-GRPO的核心思路是将执行错误转化为可利用的监督信号,从而指导模型学习如何从错误中恢复。具体而言,当模型执行出错时,不是简单地给予负奖励,而是利用错误模拟器生成诊断反馈,并基于此反馈重新采样恢复轨迹,从而构建新的训练样本。这种方式使得模型能够从自身产生的错误中学习,避免了分布不匹配问题。
技术框架:Fission-GRPO框架主要包含以下几个模块:1) 工具使用Agent:负责与环境交互,调用工具完成任务。2) 错误模拟器:用于模拟各种可能的执行错误,并提供诊断反馈。3) 轨迹分解模块:将失败的轨迹分解为多个片段,并利用错误模拟器的反馈进行增强。4) 策略优化模块:使用强化学习算法(如GRPO)优化Agent的策略,使其能够更好地从错误中恢复。整个流程是在RL训练循环中进行的,通过不断地与环境交互、生成错误、分解轨迹、重采样和优化策略,提升模型的错误恢复能力。
关键创新:Fission-GRPO的关键创新在于其将错误转化为监督信号的方式。与传统的强化学习方法不同,Fission-GRPO不是简单地将错误视为负奖励,而是利用错误模拟器生成诊断反馈,并基于此反馈重新采样恢复轨迹。这种方式使得模型能够从自身产生的错误中学习,避免了分布不匹配问题,并且能够更有效地利用错误信息进行策略优化。
关键设计:Fission-GRPO的关键设计包括:1) 错误模拟器的微调:使用真实世界的错误数据对错误模拟器进行微调,使其能够更准确地模拟实际的执行错误。2) 轨迹分解策略:设计合理的轨迹分解策略,将失败的轨迹分解为多个有意义的片段,并利用错误模拟器的反馈进行增强。3) 重采样策略:设计有效的重采样策略,从错误状态出发,生成高质量的恢复轨迹。4) 损失函数设计:使用GRPO损失函数,结合错误纠正的监督信号,优化Agent的策略。
🖼️ 关键图片

📊 实验亮点
Fission-GRPO在BFCL v4 Multi-Turn数据集上进行了评估,实验结果表明,Fission-GRPO能够显著提升LLM的错误恢复能力。具体而言,Fission-GRPO将Qwen3-8B的错误恢复率提高了5.7%,并且与GRPO相比,总体准确率提高了4%(从42.75%提高到46.75%)。此外,Fission-GRPO的性能优于专门的工具使用代理,证明了其有效性和优越性。
🎯 应用场景
Fission-GRPO技术可应用于各种需要LLM进行工具使用的场景,例如智能助手、自动化流程、机器人控制等。通过提高LLM的错误恢复能力,可以显著提升这些系统的可靠性和用户体验,降低人工干预的需求。未来,该技术有望推动LLM在更复杂、更具挑战性的实际应用中发挥更大的作用。
📄 摘要(原文)
Large language models (LLMs) can call tools effectively, yet they remain brittle in multi-turn execution: following a tool call error, smaller models often degenerate into repetitive invalid re-invocations, failing to interpret error feedback and self-correct. This brittleness hinders reliable real-world deployment, where the execution errors are inherently inevitable during tool interaction procedures. We identify a key limitation of current approaches: standard reinforcement learning (RL) treats errors as sparse negative rewards, providing no guidance on how to recover, while pre-collected synthetic error-correction datasets suffer from distribution mismatch with the model's on-policy error modes. To bridge this gap, we propose Fission-GRPO, a framework that converts execution errors into corrective supervision within the RL training loop. Our core mechanism fissions each failed trajectory into a new training instance by augmenting it with diagnostic feedback from a finetuned Error Simulator, then resampling recovery rollouts on-policy. This enables the model to learn from the precise errors it makes during exploration, rather than from static, pre-collected error cases. On the BFCL v4 Multi-Turn, Fission-GRPO improves the error recovery rate of Qwen3-8B by 5.7% absolute, crucially, yielding a 4% overall accuracy gain (42.75% to 46.75%) over GRPO and outperforming specialized tool-use agents.