When Sharpening Becomes Collapse: Sampling Bias and Semantic Coupling in RL with Verifiable Rewards
作者: Mingyuan Fan, Weiguang Han, Daixin Wang, Cen Chen, Zhiqiang Zhang, Jun Zhou
分类: cs.LG, cs.CL
发布日期: 2026-01-22
💡 一句话要点
针对可验证奖励的强化学习,提出逆向成功优势校准和分布级别校准,缓解过拟合问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 大型语言模型 过拟合 泛化能力
📋 核心要点
- 现有基于可验证奖励的强化学习方法存在过拟合问题,导致策略坍塌到有限模式,抑制了其他有效方案。
- 论文提出逆向成功优势校准和分布级别校准,分别用于优先考虑困难查询和增加采样多样性,以缓解过拟合。
- 实验结果表明,所提出的策略能够有效提高模型的泛化能力,验证了其在缓解过拟合问题上的有效性。
📝 摘要(中文)
基于可验证奖励的强化学习(RLVR)是将大型语言模型(LLM)转化为可靠问题解决者的核心范式,尤其是在逻辑密集型领域。尽管它在经验上取得了成功,但RLVR是否能激发新的能力,或者仅仅是锐化现有知识的分布,仍然不清楚。我们通过形式化过度锐化来研究这个问题,这是一种策略坍塌到有限模式,抑制有效替代方案的现象。从高层次上讲,我们发现有限批次更新本质上会使学习偏向于采样的模式,从而触发通过语义耦合全局传播的坍塌。为了缓解这个问题,我们提出了逆向成功优势校准,以优先考虑困难的查询,以及通过记忆网络进行分布级别校准,以实现采样的多样化。经验评估验证了我们的策略可以有效地提高泛化能力。
🔬 方法详解
问题定义:论文旨在解决基于可验证奖励的强化学习(RLVR)中出现的过拟合问题,即“过度锐化”现象。现有方法容易使策略坍塌到有限的几种模式上,忽略了其他同样有效的解决方案,导致泛化能力下降。这种现象源于有限批次更新带来的采样偏差,以及语义耦合导致的误差传播。
核心思路:论文的核心思路是通过校准奖励信号和采样分布来缓解过拟合。具体来说,一方面,通过逆向成功优势校准,优先考虑那些难以成功的查询,从而避免模型过度拟合容易成功的模式。另一方面,通过分布级别校准,利用记忆网络来增加采样多样性,探索更多可能的解决方案,从而避免策略坍塌。
技术框架:整体框架包含两个主要模块:逆向成功优势校准和分布级别校准。逆向成功优势校准模块根据查询的难度调整奖励信号,使得模型更加关注困难的查询。分布级别校准模块使用一个记忆网络来存储和检索历史查询及其对应的成功率,从而指导采样过程,增加采样多样性。这两个模块共同作用,缓解过拟合问题,提高模型的泛化能力。
关键创新:论文的关键创新在于提出了逆向成功优势校准和分布级别校准两种策略,并将其结合起来解决RLVR中的过拟合问题。逆向成功优势校准通过调整奖励信号,使得模型更加关注困难的查询,这与传统的奖励塑造方法不同,后者通常侧重于奖励容易成功的行为。分布级别校准通过记忆网络来增加采样多样性,这与传统的探索策略不同,后者通常侧重于随机探索。
关键设计:逆向成功优势校准的关键在于如何定义查询的难度,以及如何根据难度调整奖励信号。论文中可能使用了某种指标来衡量查询的难度,例如,查询的成功率或解决查询所需的步骤数。分布级别校准的关键在于记忆网络的结构和更新方式,以及如何利用记忆网络来指导采样过程。具体的损失函数和网络结构等技术细节未知,需要查阅原文。
🖼️ 关键图片
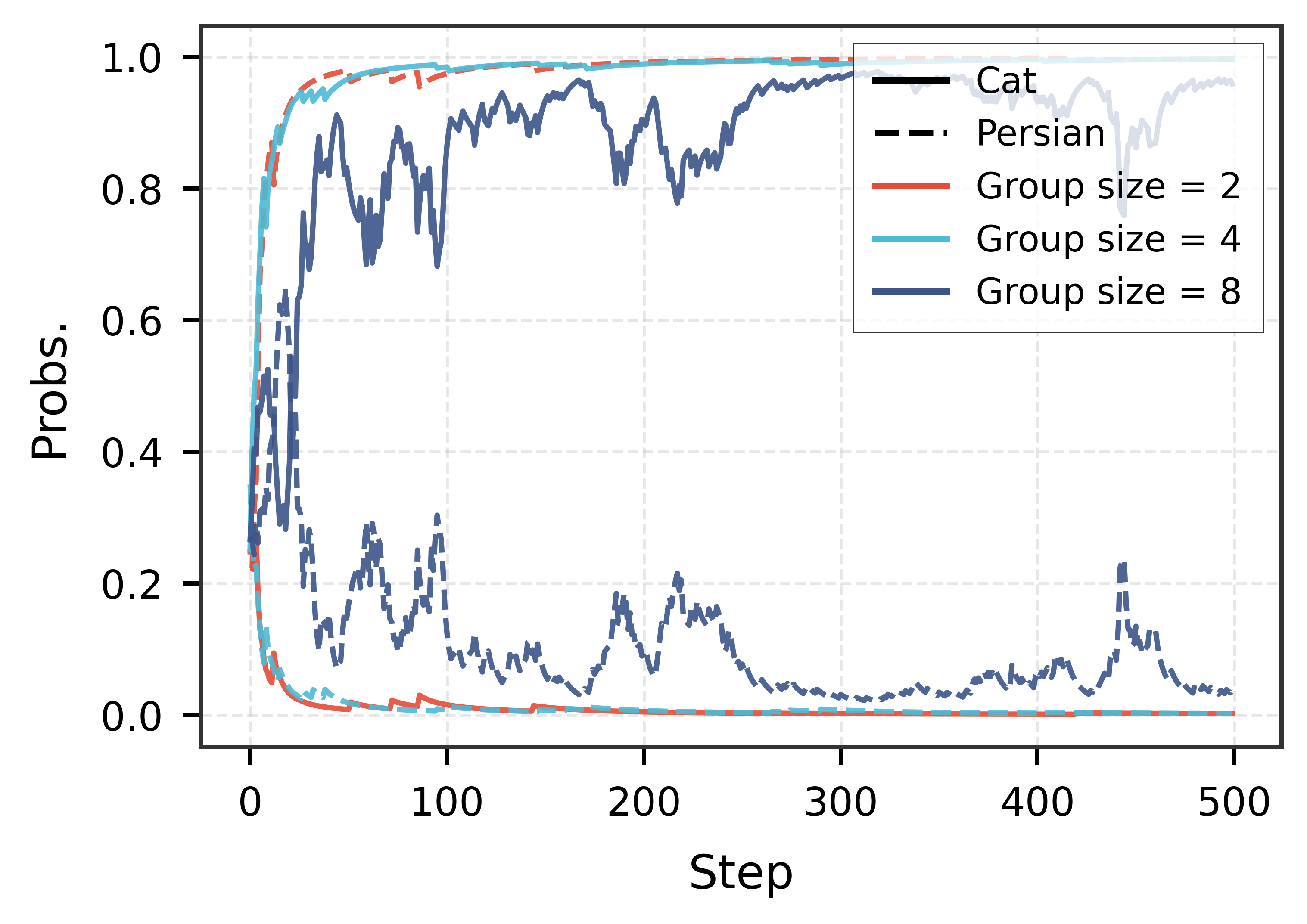
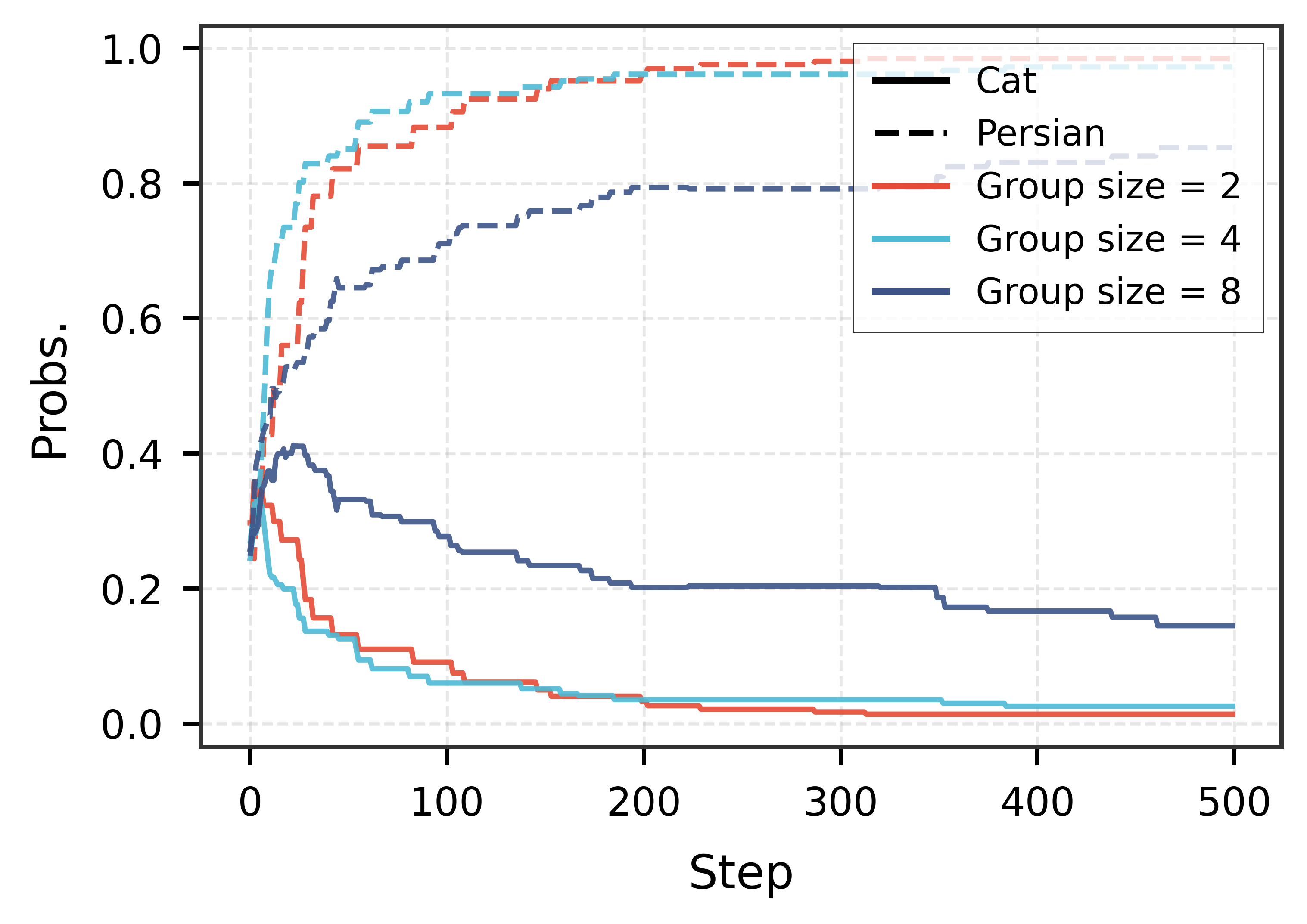
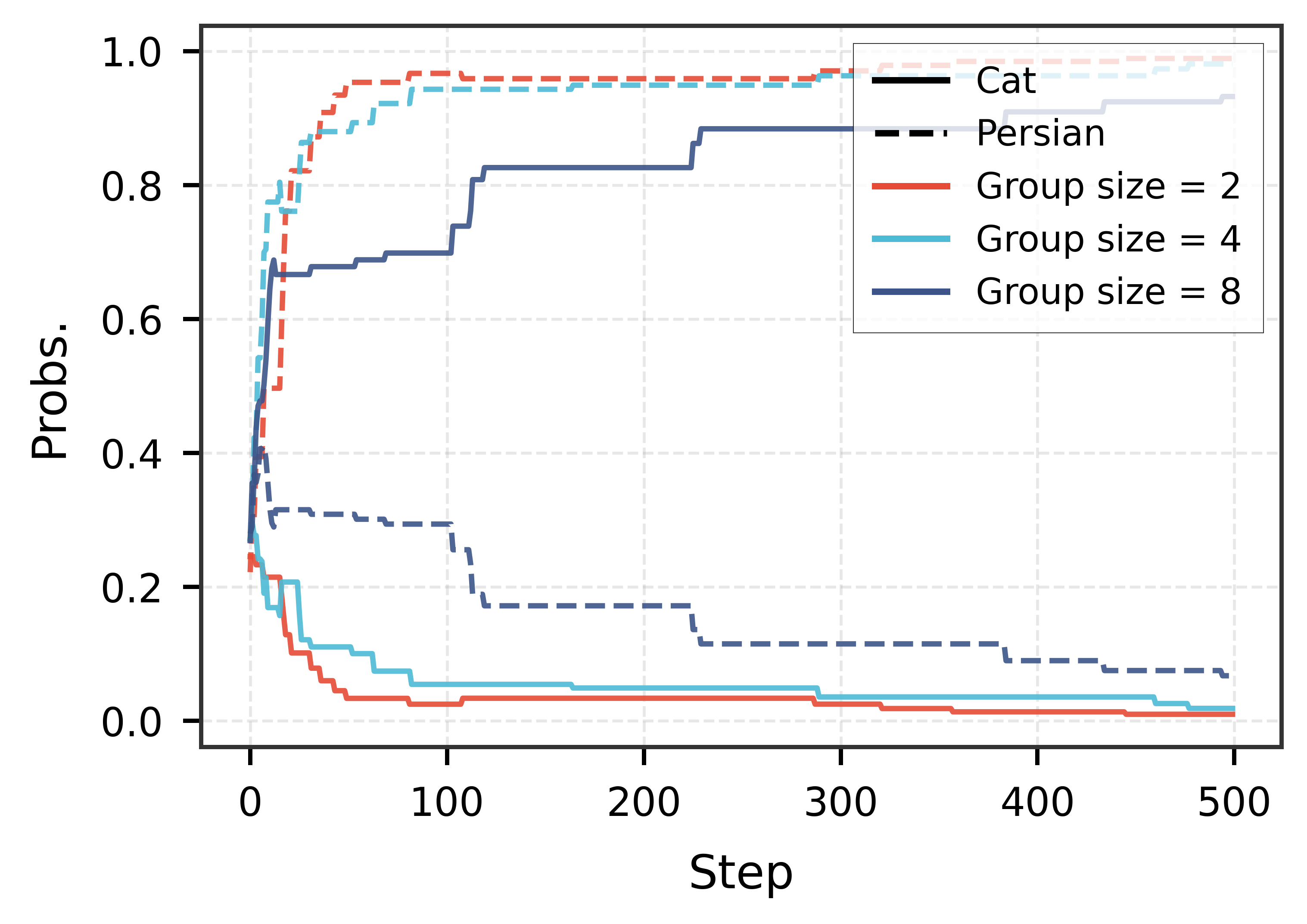
📊 实验亮点
论文通过实验验证了所提出的逆向成功优势校准和分布级别校准策略能够有效提高模型的泛化能力。具体的性能数据和对比基线未知,但摘要中明确指出“经验评估验证了我们的策略可以有效地提高泛化能力”,表明该方法在实验中取得了显著的提升效果。详细的实验结果需要查阅原文。
🎯 应用场景
该研究成果可应用于各种需要大型语言模型进行逻辑推理和问题解决的领域,例如智能客服、自动编程、定理证明等。通过提高模型的泛化能力,可以使其在面对新的、未知的查询时,也能给出可靠的答案,从而提升用户体验和工作效率。未来的研究可以进一步探索如何将该方法应用于更复杂的任务和更大的模型。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) is a central paradigm for turning large language models (LLMs) into reliable problem solvers, especially in logic-heavy domains. Despite its empirical success, it remains unclear whether RLVR elicits novel capabilities or merely sharpens the distribution over existing knowledge. We study this by formalizing over-sharpening, a phenomenon where the policy collapses onto limited modes, suppressing valid alternatives. At a high level, we discover finite-batch updates intrinsically bias learning toward sampled modes, triggering a collapse that propagates globally via semantic coupling. To mitigate this, we propose inverse-success advantage calibration to prioritize difficult queries and distribution-level calibration to diversify sampling via a memory network. Empirical evaluations validate that our strategies can effectively improve generalization.