CLEANER: Self-Purified Trajectories Boost Agentic Reinforcement Learning
作者: Tianshi Xu, Yuteng Chen, Meng Li
分类: cs.LG
发布日期: 2026-01-21
💡 一句话要点
CLEANER:自净化轨迹提升Agentic强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic强化学习 大型语言模型 轨迹净化 自纠错 相似性学习
📋 核心要点
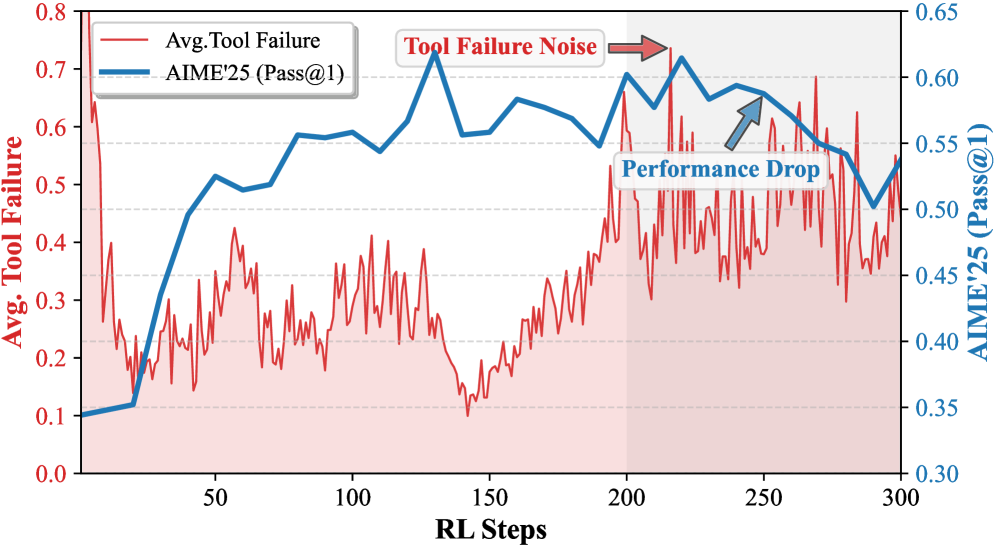
- Agentic RL中,小模型常因执行失败产生噪声轨迹,导致信用分配错误,影响策略优化。
- CLEANER利用模型自纠错能力,通过相似性感知自适应回滚(SAAR)机制,构建自净化轨迹。
- 实验表明,CLEANER在多个基准测试中显著提升性能,并能以更少的训练步骤达到SOTA水平。
📝 摘要(中文)
Agentic强化学习(RL)使大型语言模型(LLMs)能够利用Python解释器等工具解决复杂问题。然而,对于参数受限的模型(例如4B-7B),探索阶段经常受到频繁执行失败的困扰,产生噪声轨迹,阻碍策略优化。在标准基于结果的奖励设置下,这种噪声导致了关键的信用分配问题,即错误的动作与成功的结果一起被无意中加强。现有的缓解措施面临两难:密集的奖励通常会触发奖励利用,而过采样会产生过高的计算成本。为了解决这些挑战,我们提出了CLEANER。与外部过滤方法不同,CLEANER利用模型固有的自我纠正能力,在数据收集期间直接消除受错误污染的上下文。其核心是相似性感知自适应回滚(SAAR)机制,通过回顾性地用成功的自我纠正替换失败,自主构建干净的、净化的轨迹。基于语义相似性,SAAR自适应地调节替换粒度,从浅层执行修复到深层推理替换。通过在这些自净化路径上进行训练,模型内化了正确的推理模式,而不是错误恢复循环。在AIME24/25、GPQA和LiveCodeBench上的经验结果表明,平均准确率比基线提高了6%、3%和5%。值得注意的是,CLEANER仅使用三分之一的训练步骤即可达到最先进的性能,突出了轨迹净化作为高效agentic RL的可扩展解决方案。
🔬 方法详解
问题定义:Agentic RL任务中,尤其是对于参数量较小的LLM,在探索过程中容易出现执行错误,产生大量噪声轨迹。这些噪声轨迹会干扰策略学习,导致模型学习到错误的推理模式,或者陷入错误恢复的循环中。现有的方法,如密集奖励容易导致reward hacking,而过采样则计算成本过高。
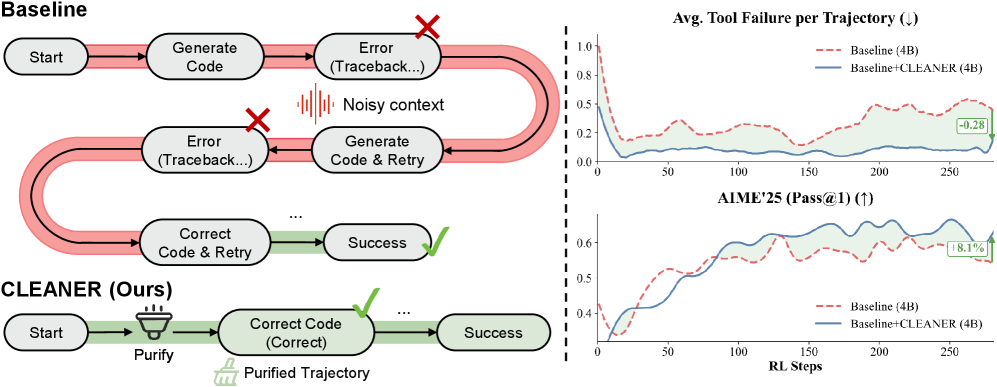
核心思路:CLEANER的核心思路是利用模型自身的纠错能力,在数据收集阶段主动净化轨迹。通过回顾历史轨迹,识别并替换掉执行失败的部分,从而构建高质量的训练数据。这种方法避免了外部过滤带来的信息损失,也降低了对额外奖励信号的依赖。
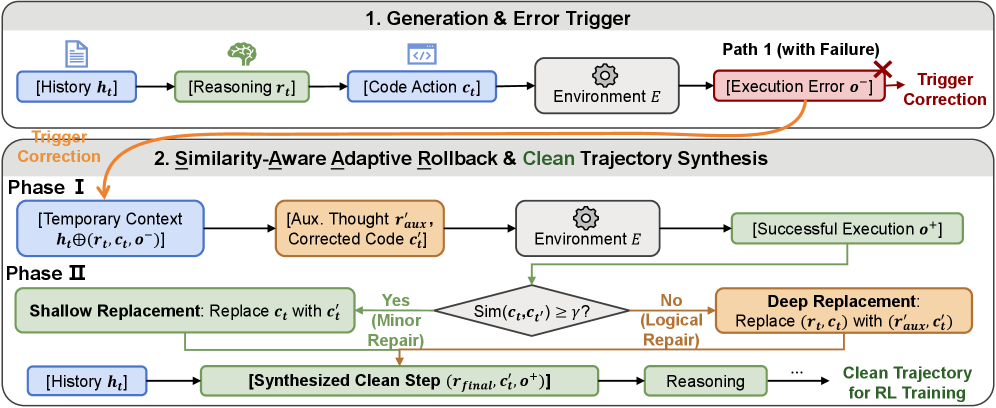
技术框架:CLEANER主要包含以下几个阶段:1) 模型执行任务并生成轨迹;2) SAAR机制分析轨迹,识别执行失败的部分;3) SAAR利用模型的自纠错能力,尝试修复失败的部分;4) 如果修复成功,则用修复后的轨迹替换原始轨迹,形成净化后的轨迹;5) 使用净化后的轨迹训练模型。
关键创新:CLEANER的关键创新在于Similarity-Aware Adaptive Rollback (SAAR)机制。SAAR能够根据语义相似性,自适应地调整回滚的粒度。对于简单的执行错误,SAAR可能只需要进行浅层的修复;而对于深层的推理错误,SAAR则需要进行更深层次的替换。这种自适应性使得CLEANER能够更有效地净化轨迹,避免过度干预或修复不足。
关键设计:SAAR机制中的语义相似度计算是关键。论文中使用了预训练的语言模型来计算轨迹片段之间的语义相似度。此外,回滚的粒度也需要仔细调整,以避免破坏轨迹的连贯性。具体的参数设置(如相似度阈值、回滚深度等)需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CLEANER在AIME24/25、GPQA和LiveCodeBench等基准测试中,相比基线方法平均准确率分别提升了6%、3%和5%。更重要的是,CLEANER仅使用三分之一的训练步骤就能够达到与现有SOTA方法相当的性能,显著提高了训练效率,验证了轨迹净化策略的有效性。
🎯 应用场景
CLEANER可应用于各种Agentic RL任务,尤其是在资源受限的环境下,例如移动设备上的智能助手、低功耗机器人等。通过提高训练效率和模型性能,CLEANER能够帮助这些设备更好地完成复杂任务,提升用户体验。此外,该方法也有潜力应用于其他需要高质量训练数据的机器学习任务。
📄 摘要(原文)
Agentic Reinforcement Learning (RL) has empowered Large Language Models (LLMs) to utilize tools like Python interpreters for complex problem-solving. However, for parameter-constrained models (e.g., 4B--7B), the exploration phase is often plagued by frequent execution failures, creating noisy trajectories that hinder policy optimization. Under standard outcome-based reward settings, this noise leads to a critical credit assignment issue, where erroneous actions are inadvertently reinforced alongside successful outcomes. Existing mitigations face a dilemma: dense rewards often trigger reward hacking, while supersampling incurs prohibitive computational costs. To address these challenges, we propose CLEANER. Distinct from external filtering methods, CLEANER exploits the model's intrinsic self-correction capabilities to eliminate error-contaminated context directly during data collection. At its core, the Similarity-Aware Adaptive Rollback (SAAR) mechanism autonomously constructs clean, purified trajectories by retrospectively replacing failures with successful self-corrections. Based on semantic similarity, SAAR adaptively regulates replacement granularity from shallow execution repairs to deep reasoning substitutions. By training on these self-purified paths, the model internalizes correct reasoning patterns rather than error-recovery loops. Empirical results on AIME24/25, GPQA, and LiveCodeBench show average accuracy gains of 6%, 3%, and 5% over baselines. Notably, CLEANER matches state-of-the-art performance using only one-third of the training steps, highlighting trajectory purification as a scalable solution for efficient agentic RL. Our models and code are available at GitHub