Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation
作者: Haonan Yuan, Qingyun Sun, Jiacheng Tao, Xingcheng Fu, Jianxin Li
分类: cs.LG, cs.AI
发布日期: 2026-01-21
备注: Accepted by the Web Conference 2026 (Research Track)
💡 一句话要点
提出RAG-GFM,通过检索增强生成克服图基础模型中的内存瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图基础模型 检索增强生成 知识图谱 图学习 双模态学习
📋 核心要点
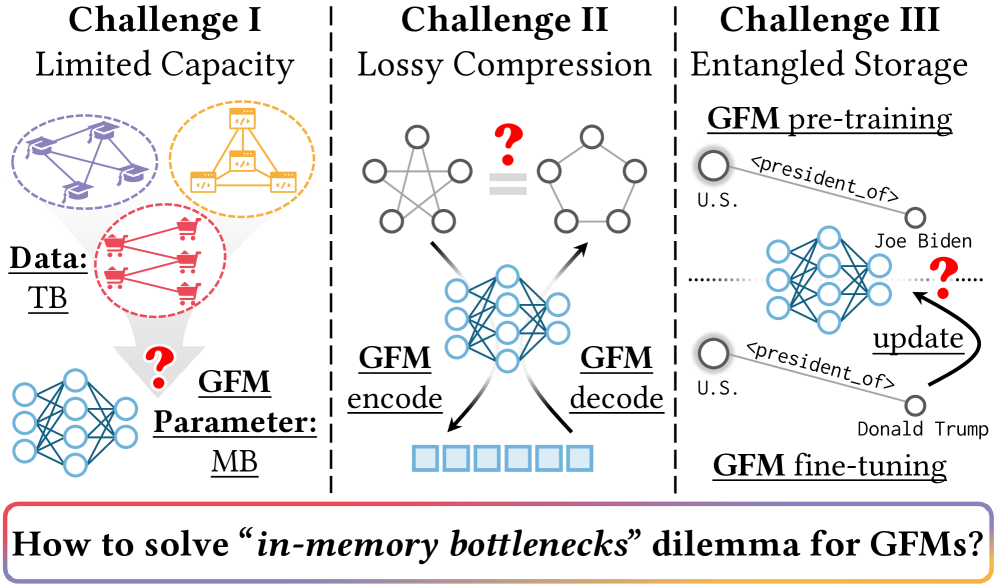
- 图基础模型受限于内存瓶颈,无法有效编码和利用图知识,导致可扩展性和可解释性问题。
- RAG-GFM通过检索增强生成,将知识从模型参数中卸载,利用外部知识库提升模型性能。
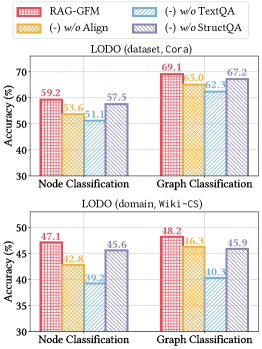
- 实验表明,RAG-GFM在跨领域节点和图分类任务中显著优于现有方法,提升了有效性和效率。
📝 摘要(中文)
图基础模型(GFMs)已成为图学习领域的前沿,有望在各种任务中提供可迁移的表示。然而,GFMs仍然受到内存瓶颈的限制:它们试图将知识编码到模型参数中,这限制了语义容量,引入了严重的有损压缩和冲突,并将图表示与知识纠缠在一起,从而阻碍了高效的适应性,损害了可扩展性和可解释性。在这项工作中,我们提出了RAG-GFM,一种检索增强生成辅助的图基础模型,它将知识从参数中卸载并补充参数化学习。为了外部化图知识,我们构建了一个双模态统一检索模块,其中包含来自前缀结构化文本的语义存储和来自基于中心性的motif的结构存储。为了保留异构信息,我们设计了一个双视图对齐目标,对比两种模态以捕获内容和关系模式。为了实现高效的下游适应,我们执行上下文增强,以检索到的文本和motif作为上下文证据来丰富支持实例。在五个基准图数据集上的大量实验表明,RAG-GFM在跨领域节点和图分类中始终优于13个最先进的基线,实现了卓越的有效性和效率。
🔬 方法详解
问题定义:图基础模型(GFMs)试图将所有知识编码到模型参数中,这导致了几个问题:有限的语义容量,因为模型大小是固定的;有损压缩,因为大量信息被压缩到有限的参数中;以及图表示与知识的纠缠,这使得模型难以适应新的任务。现有方法难以在可扩展性和可解释性之间取得平衡。
核心思路:RAG-GFM的核心思想是将知识从模型参数中分离出来,并利用外部知识库来增强图表示。通过检索相关的文本和结构信息,RAG-GFM可以更好地理解图的语义,并提高模型的泛化能力。这种方法类似于人类在解决问题时查阅资料的过程,可以有效地扩展模型的知识范围。
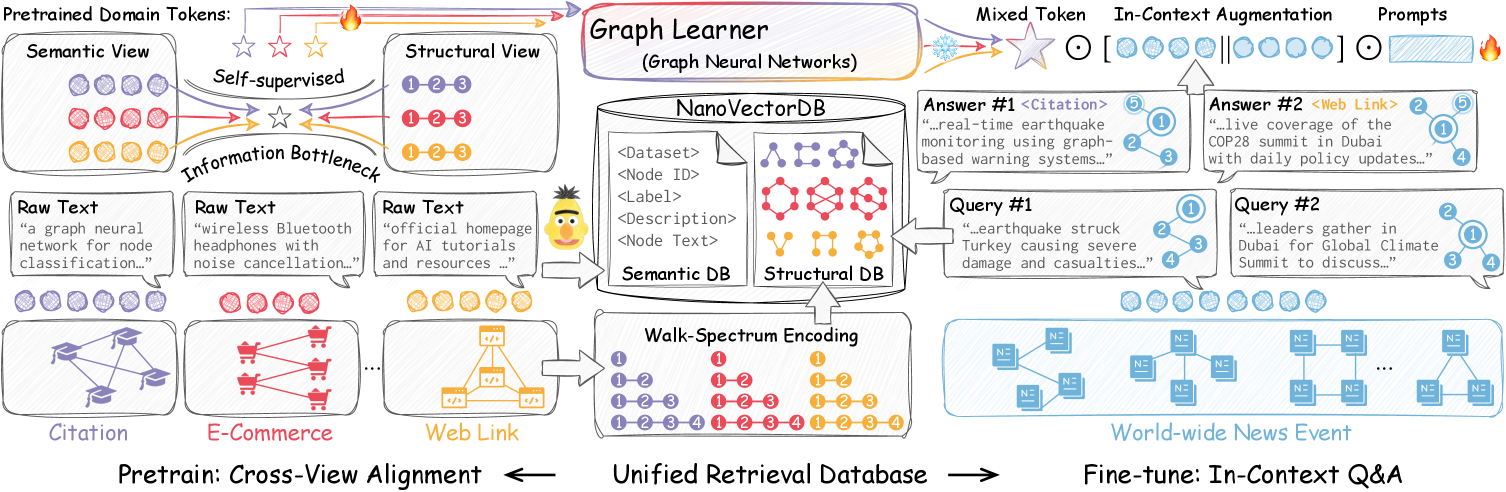
技术框架:RAG-GFM包含以下几个主要模块:1) 双模态统一检索模块:该模块包含一个语义存储(来自前缀结构化文本)和一个结构存储(来自基于中心性的motif)。2) 双视图对齐目标:该目标对比两种模态(文本和结构),以捕获内容和关系模式。3) 上下文增强:该模块利用检索到的文本和motif作为上下文证据来丰富支持实例,从而实现高效的下游适应。整体流程是,给定一个图,首先使用双模态统一检索模块检索相关的文本和结构信息,然后使用双视图对齐目标对齐两种模态,最后使用上下文增强模块增强图表示。
关键创新:RAG-GFM的关键创新在于其检索增强生成框架,它允许模型利用外部知识库来增强图表示。与现有方法相比,RAG-GFM不需要将所有知识都编码到模型参数中,从而避免了内存瓶颈和有损压缩问题。此外,RAG-GFM的双模态统一检索模块和双视图对齐目标可以有效地捕获图的语义和结构信息。
关键设计:RAG-GFM的关键设计包括:1) 使用前缀结构化文本构建语义存储,这可以有效地组织和检索文本信息。2) 使用基于中心性的motif构建结构存储,这可以有效地捕获图的结构信息。3) 设计双视图对齐目标,对比文本和结构模态,以捕获内容和关系模式。4) 使用检索到的文本和motif作为上下文证据来增强图表示,从而提高模型的泛化能力。具体的损失函数和网络结构细节在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片
📊 实验亮点
RAG-GFM在五个基准图数据集上进行了广泛的实验,结果表明,RAG-GFM在跨领域节点和图分类任务中始终优于13个最先进的基线。具体的性能提升数据在摘要中未给出,但强调了RAG-GFM在有效性和效率方面的卓越表现。
🎯 应用场景
RAG-GFM具有广泛的应用前景,例如知识图谱补全、药物发现、社交网络分析等。通过利用外部知识库,RAG-GFM可以更好地理解图的语义,并提高模型的泛化能力。该研究有助于推动图学习领域的发展,并为解决实际问题提供新的思路。
📄 摘要(原文)
Graph Foundation Models (GFMs) have emerged as a frontier in graph learning, which are expected to deliver transferable representations across diverse tasks. However, GFMs remain constrained by in-memory bottlenecks: they attempt to encode knowledge into model parameters, which limits semantic capacity, introduces heavy lossy compression with conflicts, and entangles graph representation with the knowledge in ways that hinder efficient adaptation, undermining scalability and interpretability. In this work,we propose RAG-GFM, a Retrieval-Augmented Generation aided Graph Foundation Model that offloads knowledge from parameters and complements parameterized learning. To externalize graph knowledge, we build a dual-modal unified retrieval module, where a semantic store from prefix-structured text and a structural store from centrality-based motif. To preserve heterogeneous information, we design a dual-view alignment objective that contrasts both modalities to capture both content and relational patterns. To enable efficient downstream adaptation, we perform in-context augmentation to enrich supporting instances with retrieved texts and motifs as contextual evidence. Extensive experiments on five benchmark graph datasets demonstrate that RAG-GFM consistently outperforms 13 state-of-the-art baselines in both cross-domain node and graph classification, achieving superior effectiveness and efficiency.