A Curriculum-Based Deep Reinforcement Learning Framework for the Electric Vehicle Routing Problem
作者: Mertcan Daysalilar, Fuat Uyguroglu, Gabriel Nicolosi, Adam Meyers
分类: cs.LG, cs.AI
发布日期: 2026-01-21
💡 一句话要点
提出基于课程学习的深度强化学习框架,解决电动汽车路径规划问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 电动汽车路径规划 深度强化学习 课程学习 图神经网络 车辆路径问题
📋 核心要点
- 电动汽车路径规划问题(EVRPTW)约束复杂,现有深度强化学习方法训练不稳定,难以泛化。
- 提出基于课程学习的DRL框架,分阶段学习距离优化、电池管理和完整EVRPTW,逐步增加难度。
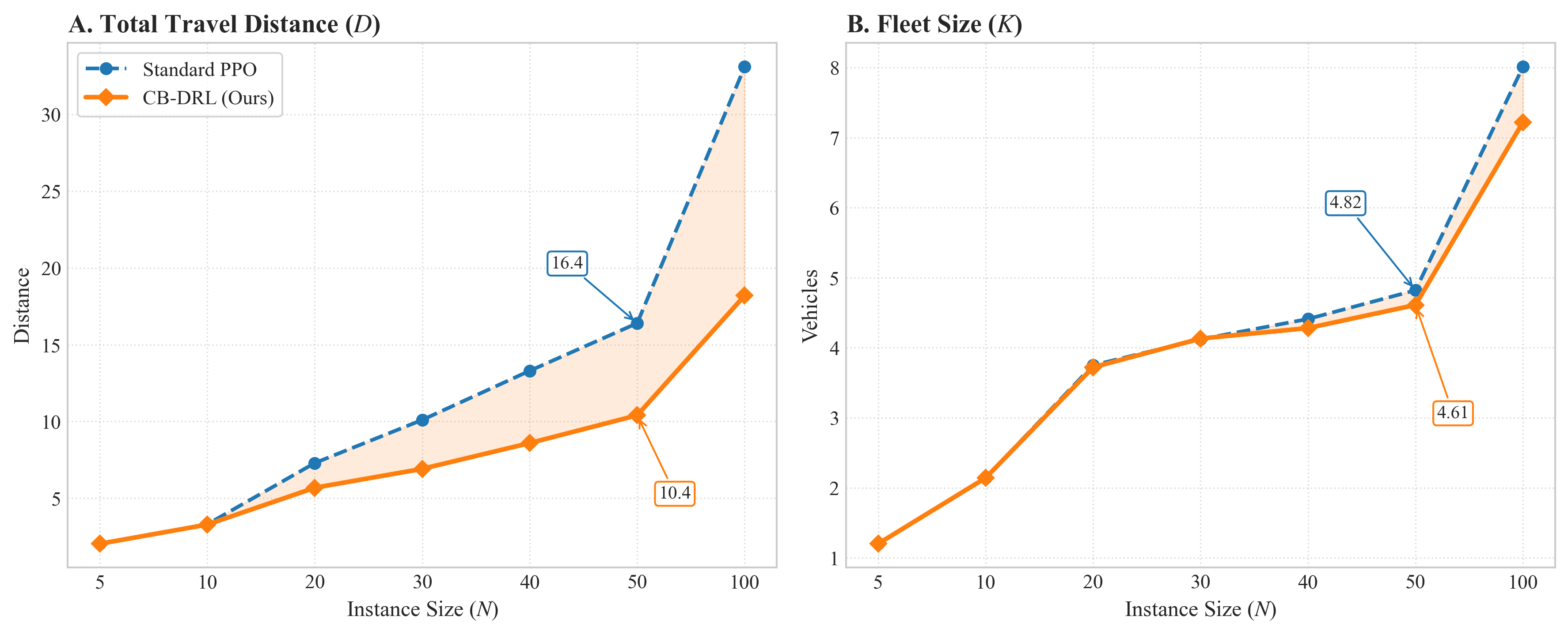
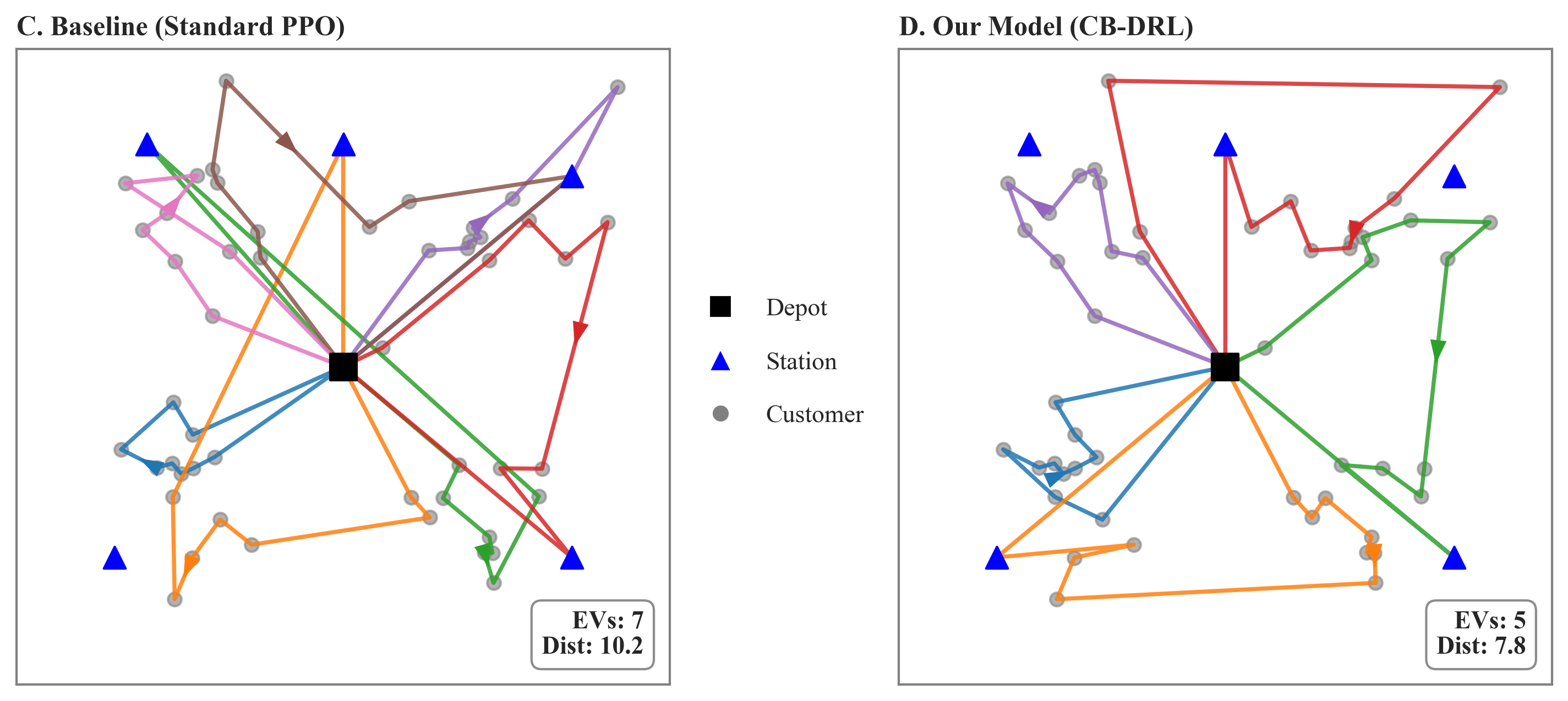
- 实验表明,该方法在小规模数据上训练后,能有效泛化到大规模未见实例,性能优于基线。
📝 摘要(中文)
本文提出了一种基于课程学习的深度强化学习(CB-DRL)框架,用于解决带时间窗的电动汽车路径规划问题(EVRPTW)。EVRPTW是可持续物流中的一个复杂优化问题,需要在满足严格的客户时间约束的同时,最小化总行驶距离、车队规模和电池使用量。现有的DRL模型通常难以保持训练稳定性,在约束密集时无法收敛或泛化。该框架利用一个结构化的三阶段课程,逐步增加问题复杂度:智能体首先学习距离和车队优化(A阶段),然后是电池管理(B阶段),最后是完整的EVRPTW(C阶段)。为了确保跨阶段的稳定学习,该框架采用了一种改进的近端策略优化算法,具有特定于阶段的超参数、价值和优势剪裁以及自适应学习率调度。策略网络建立在异构图注意力编码器之上,并通过全局-局部注意力和特征线性调制进行增强。这种专门的架构显式地捕获了仓库、客户和充电站的不同属性。该模型仅在N=10个客户的小实例上进行训练,就展示了对N=5到N=100的未见实例的强大泛化能力,在中等规模问题上显著优于标准基线。实验结果证实,这种课程引导的方法在标准DRL基线失败的分布外实例上实现了高可行性率和有竞争力的解决方案质量,有效地弥合了神经速度和运营可靠性之间的差距。
🔬 方法详解
问题定义:论文旨在解决带时间窗的电动汽车路径规划问题(EVRPTW)。现有方法,特别是传统的启发式算法和精确求解器,在处理大规模问题时计算成本高昂。而现有的深度强化学习方法虽然具有潜力,但训练过程不稳定,难以收敛,并且在约束条件较为严格的情况下泛化能力较差。
核心思路:论文的核心思路是采用课程学习(Curriculum Learning)的思想,将复杂的EVRPTW问题分解为多个难度递增的子问题,让智能体逐步学习。通过这种方式,可以提高训练的稳定性和效率,并增强模型的泛化能力。
技术框架:该框架包含三个主要阶段:A阶段学习距离和车队优化,B阶段学习电池管理,C阶段学习完整的EVRPTW问题。每个阶段都使用改进的近端策略优化(PPO)算法进行训练,并采用特定于阶段的超参数、价值和优势剪裁以及自适应学习率调度。策略网络基于异构图注意力编码器,通过全局-局部注意力和特征线性调制来捕获不同类型节点(仓库、客户、充电站)的特征。
关键创新:该论文的关键创新在于将课程学习与深度强化学习相结合,并针对EVRPTW问题的特点设计了三阶段的课程。此外,异构图注意力编码器能够有效地处理不同类型节点之间的关系,从而提高模型的性能。
关键设计:在A阶段,奖励函数主要关注最小化行驶距离和车队规模。在B阶段,奖励函数增加了对电池使用量的惩罚。在C阶段,奖励函数综合考虑了行驶距离、车队规模、电池使用量和时间窗约束。PPO算法中的剪裁参数和学习率调度策略根据不同阶段进行调整,以确保训练的稳定性。异构图注意力编码器使用多头注意力机制来学习节点之间的关系,并通过全局-局部注意力机制来捕获全局和局部信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在小规模实例(N=10)上训练后,能够很好地泛化到中等规模实例(N=5到N=100),显著优于标准DRL基线。具体来说,该方法在分布外实例上实现了高可行性率和有竞争力的解决方案质量,表明其具有较强的鲁棒性和泛化能力。在标准DRL基线失效的情况下,该方法能够有效地解决EVRPTW问题。
🎯 应用场景
该研究成果可应用于电动汽车物流配送、智能交通管理等领域,有助于提高物流效率、降低运营成本、减少碳排放。通过优化电动汽车的行驶路线和充电策略,可以更好地满足客户需求,并促进可持续物流的发展。未来,该方法可以扩展到其他类型的车辆路径规划问题,例如混合动力车辆或无人驾驶车辆。
📄 摘要(原文)
The electric vehicle routing problem with time windows (EVRPTW) is a complex optimization problem in sustainable logistics, where routing decisions must minimize total travel distance, fleet size, and battery usage while satisfying strict customer time constraints. Although deep reinforcement learning (DRL) has shown great potential as an alternative to classical heuristics and exact solvers, existing DRL models often struggle to maintain training stability-failing to converge or generalize when constraints are dense. In this study, we propose a curriculum-based deep reinforcement learning (CB-DRL) framework designed to resolve this instability. The framework utilizes a structured three-phase curriculum that gradually increases problem complexity: the agent first learns distance and fleet optimization (Phase A), then battery management (Phase B), and finally the full EVRPTW (Phase C). To ensure stable learning across phases, the framework employs a modified proximal policy optimization algorithm with phase-specific hyperparameters, value and advantage clipping, and adaptive learning-rate scheduling. The policy network is built upon a heterogeneous graph attention encoder enhanced by global-local attention and feature-wise linear modulation. This specialized architecture explicitly captures the distinct properties of depots, customers, and charging stations. Trained exclusively on small instances with N=10 customers, the model demonstrates robust generalization to unseen instances ranging from N=5 to N=100, significantly outperforming standard baselines on medium-scale problems. Experimental results confirm that this curriculum-guided approach achieves high feasibility rates and competitive solution quality on out-of-distribution instances where standard DRL baselines fail, effectively bridging the gap between neural speed and operational reliability.