Mixture-of-Experts Models in Vision: Routing, Optimization, and Generalization
作者: Adam Rokah, Daniel Veress, Caleb Caulk, Sourav Sharan
分类: cs.LG, cs.CV
发布日期: 2026-01-21
备注: 7 pages, 8 figures. Code available at: https://github.com/moe-project-uu/mixture-of-experts-project
💡 一句话要点
研究视觉MoE模型:路由、优化与泛化,揭示其在图像分类中的行为特性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 图像分类 模型泛化 Hessian分析 条件计算
📋 核心要点
- 现有方法在图像分类中对MoE的专家利用率和泛化能力研究不足,存在专家崩溃和效率瓶颈。
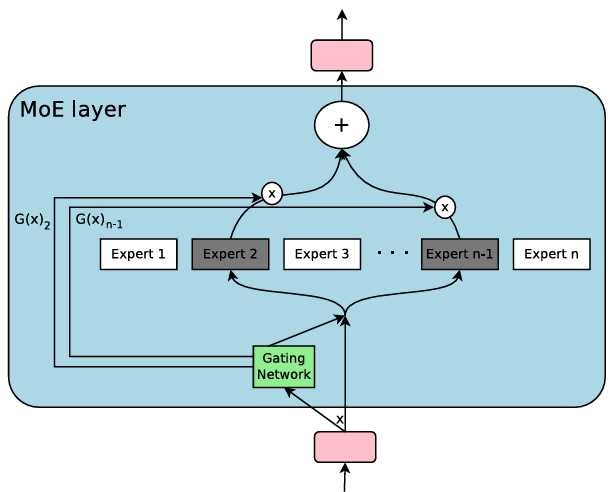
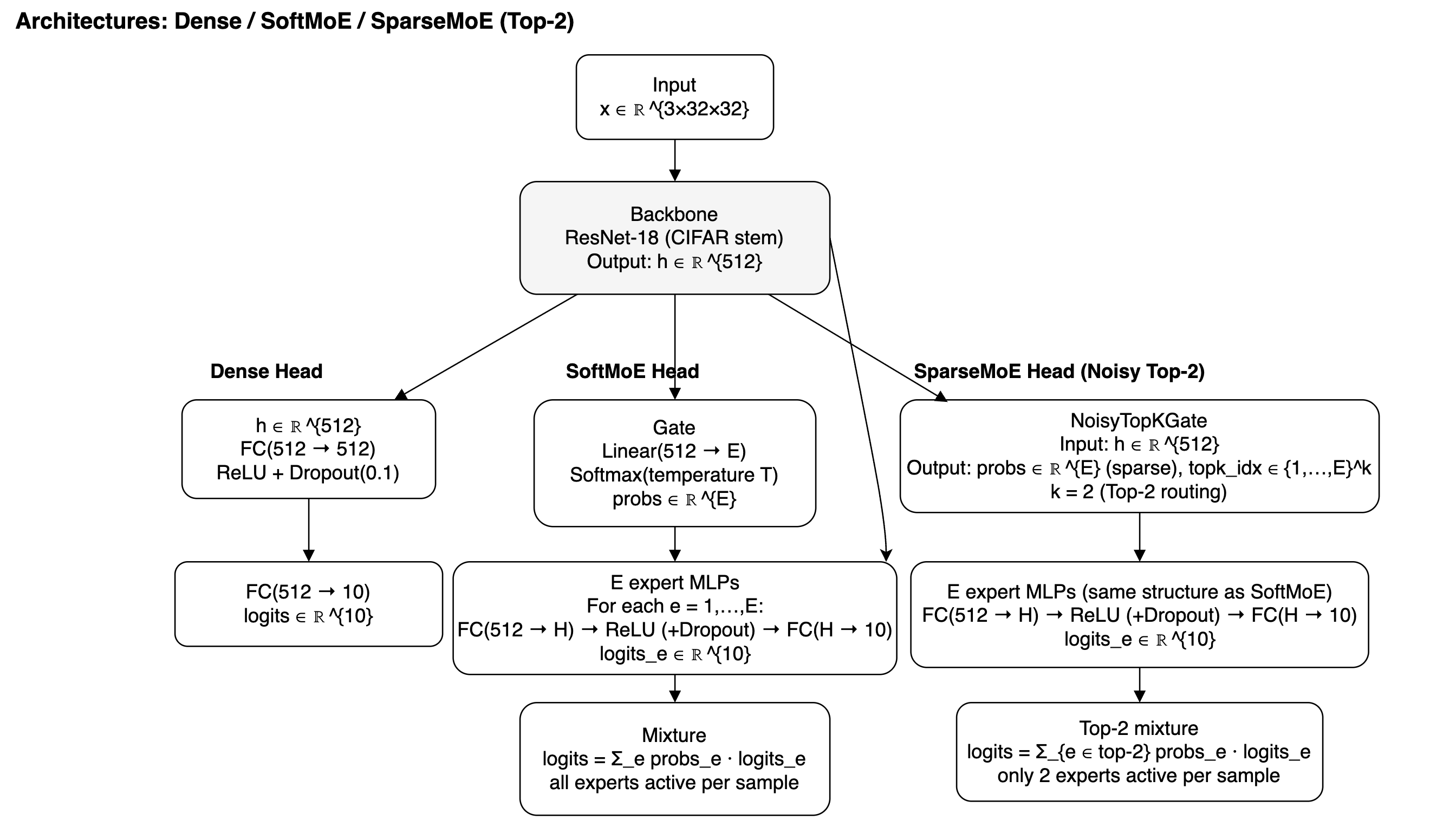
- 本文通过比较Dense、SoftMoE和SparseMoE分类器头部,研究MoE在图像分类中的路由、优化和泛化行为。
- 实验表明,MoE变体在CIFAR10上略优于Dense,但条件路由未实现推理加速,揭示理论与实际效率差距。
📝 摘要(中文)
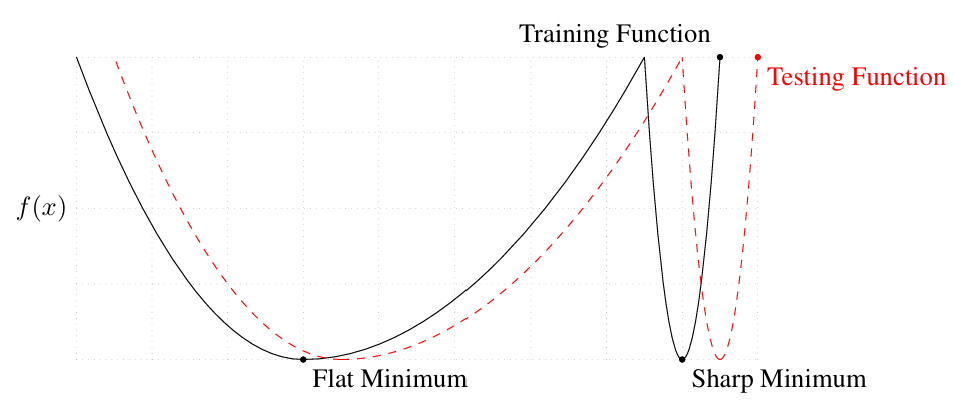
本文研究了混合专家(MoE)架构在图像分类环境下的行为,重点关注预测性能、专家利用率和泛化能力。MoE架构通过将输入路由到多个专家子网络来实现条件计算,通常被认为是扩展大型语言模型的机制。我们在CIFAR10数据集上比较了密集型、SoftMoE和SparseMoE分类器头部,并保持模型容量相当。结果表明,两种MoE变体在通过正则化保持平衡的专家利用率的同时,实现了比密集型基线略高的验证精度,避免了专家崩溃。为了分析泛化能力,我们计算了收敛时的基于Hessian的锐度指标,包括损失Hessian的最大特征值和迹,并在训练和测试数据上进行评估。我们发现,SoftMoE在这些指标上表现出更高的锐度,而Dense和SparseMoE处于相似的曲率状态,尽管所有模型都实现了相当的泛化性能。补充的损失面扰动分析揭示了密集型和MoE模型在有限参数扰动下的非局部行为的定性差异,这有助于理解基于曲率的测量,但不能直接解释验证精度。我们进一步评估了经验推理效率,并表明在这种规模下,天真实现的条件路由并没有在现代硬件上产生推理加速,突出了稀疏MoE模型中理论效率和实际效率之间的差距。
🔬 方法详解
问题定义:论文旨在研究混合专家(MoE)模型在图像分类任务中的行为特性,特别是其路由机制、优化过程和泛化能力。现有方法在图像分类中对MoE的专家利用率和泛化能力研究不足,容易出现专家崩溃问题,并且在实际硬件上难以实现理论上的推理加速效果。
核心思路:论文的核心思路是通过对比不同类型的MoE模型(SoftMoE和SparseMoE)与传统的密集型模型,在图像分类任务上分析它们的性能差异、专家利用率以及泛化能力。通过Hessian分析和损失面扰动分析,深入理解不同模型在优化过程中的行为差异,并评估条件路由在实际硬件上的推理效率。
技术框架:整体框架包括三个主要部分:1)构建Dense、SoftMoE和SparseMoE三种类型的分类器头部,并将其集成到图像分类模型中;2)在CIFAR10数据集上训练这些模型,并使用正则化方法来平衡专家利用率;3)使用Hessian分析和损失面扰动分析来研究模型的泛化能力和优化行为,并评估条件路由的推理效率。
关键创新:论文的关键创新在于对MoE模型在图像分类任务中的行为进行了深入分析,特别是通过Hessian分析和损失面扰动分析揭示了不同模型在优化过程中的差异。此外,论文还指出了稀疏MoE模型在理论效率和实际效率之间的差距,强调了在现代硬件上实现推理加速的挑战。
关键设计:论文的关键设计包括:1)使用正则化方法来平衡专家利用率,避免专家崩溃;2)使用Hessian矩阵的最大特征值和迹作为锐度指标来评估模型的泛化能力;3)通过损失面扰动分析来研究模型的非局部行为;4)评估条件路由在实际硬件上的推理效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SoftMoE和SparseMoE在CIFAR10数据集上实现了略高于Dense模型的验证精度,同时通过正则化保持了平衡的专家利用率。Hessian分析显示,SoftMoE表现出更高的锐度,而Dense和SparseMoE处于相似的曲率状态。然而,条件路由在现代硬件上并未实现推理加速,突显了稀疏MoE模型中理论效率和实际效率之间的差距。
🎯 应用场景
该研究成果可应用于图像分类、目标检测等计算机视觉任务,并为设计更高效、更具泛化能力的MoE模型提供指导。研究结果有助于优化模型结构,提升模型在资源受限设备上的部署效率,并为未来更大规模视觉模型的开发奠定基础。
📄 摘要(原文)
Mixture-of-Experts (MoE) architectures enable conditional computation by routing inputs to multiple expert subnetworks and are often motivated as a mechanism for scaling large language models. In this project, we instead study MoE behavior in an image classification setting, focusing on predictive performance, expert utilization, and generalization. We compare dense, SoftMoE, and SparseMoE classifier heads on the CIFAR10 dataset under comparable model capacity. Both MoE variants achieve slightly higher validation accuracy than the dense baseline while maintaining balanced expert utilization through regularization, avoiding expert collapse. To analyze generalization, we compute Hessian-based sharpness metrics at convergence, including the largest eigenvalue and trace of the loss Hessian, evaluated on both training and test data. We find that SoftMoE exhibits higher sharpness by these metrics, while Dense and SparseMoE lie in a similar curvature regime, despite all models achieving comparable generalization performance. Complementary loss surface perturbation analyses reveal qualitative differences in non-local behavior under finite parameter perturbations between dense and MoE models, which help contextualize curvature-based measurements without directly explaining validation accuracy. We further evaluate empirical inference efficiency and show that naively implemented conditional routing does not yield inference speedups on modern hardware at this scale, highlighting the gap between theoretical and realized efficiency in sparse MoE models.