Fine-Grained Traceability for Transparent ML Pipelines
作者: Liping Chen, Mujie Liu, Haytham Fayek
分类: cs.LG
发布日期: 2026-01-21
备注: Accepted at The Web Conference (WWW) 2026
💡 一句话要点
FG-Trac:为机器学习流水线建立可验证的细粒度溯源框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器学习流水线 数据溯源 透明性 可验证性 细粒度追踪
📋 核心要点
- 现有机器学习流水线缺乏样本级别的可验证溯源性,导致无法追踪特定样本的使用情况和数据沿袭。
- FG-Trac通过捕获和验证样本生命周期事件、计算贡献分数并锚定加密承诺,实现细粒度溯源。
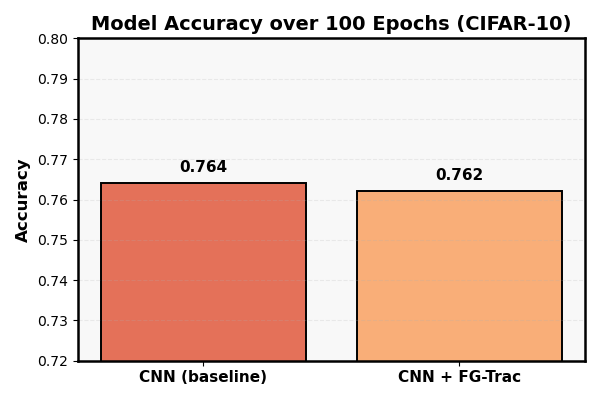
- 实验表明,FG-Trac在不影响模型性能的前提下,提供了可验证的数据使用历史,且计算开销可接受。
📝 摘要(中文)
现代机器学习系统日益以多阶段流水线的形式实现,然而现有的透明性机制通常只在模型层面运作:它们描述了一个系统是什么以及它为什么会这样运作,但没有记录、跟踪和验证单个数据样本在流水线中如何操作。这种缺乏可验证的、样本级别的溯源性使得从业者和用户无法确定是否使用了特定样本,何时处理了该样本,或者相应的记录是否随着时间的推移保持完整。我们提出了FG-Trac,一个模型无关的框架,用于在整个机器学习流水线中建立可验证的、细粒度的样本级别溯源性。FG-Trac定义了一个显式的机制来捕获和验证跨预处理和训练的样本生命周期事件,计算明确基于训练检查点的贡献分数,并将这些跟踪锚定到防篡改的加密承诺。该框架无需修改模型架构或训练目标即可集成,以实际的计算开销重建完整且可审计的数据使用历史。在典型的卷积神经网络和多模态图学习流水线上的实验表明,FG-Trac在保持预测性能的同时,使机器学习系统能够提供可验证的证据,证明在模型执行期间如何使用和传播单个样本。
🔬 方法详解
问题定义:现有的机器学习系统通常以复杂的多阶段流水线形式存在,但缺乏对单个数据样本在整个流水线中的处理过程进行追踪和验证的能力。这使得用户难以确定特定样本是否被使用、何时被处理,以及相关记录是否完整,从而影响了系统的透明性和可信度。现有方法主要关注模型层面的解释性,忽略了样本级别的溯源需求。
核心思路:FG-Trac的核心思路是在机器学习流水线的各个阶段,对每个数据样本的关键事件进行记录和验证,并建立样本贡献度的评估机制。通过将这些信息与加密承诺锚定,确保数据的完整性和防篡改性,从而实现可信的样本级别溯源。这种设计旨在提供一种模型无关的、可验证的溯源框架,无需修改现有的模型架构或训练目标。
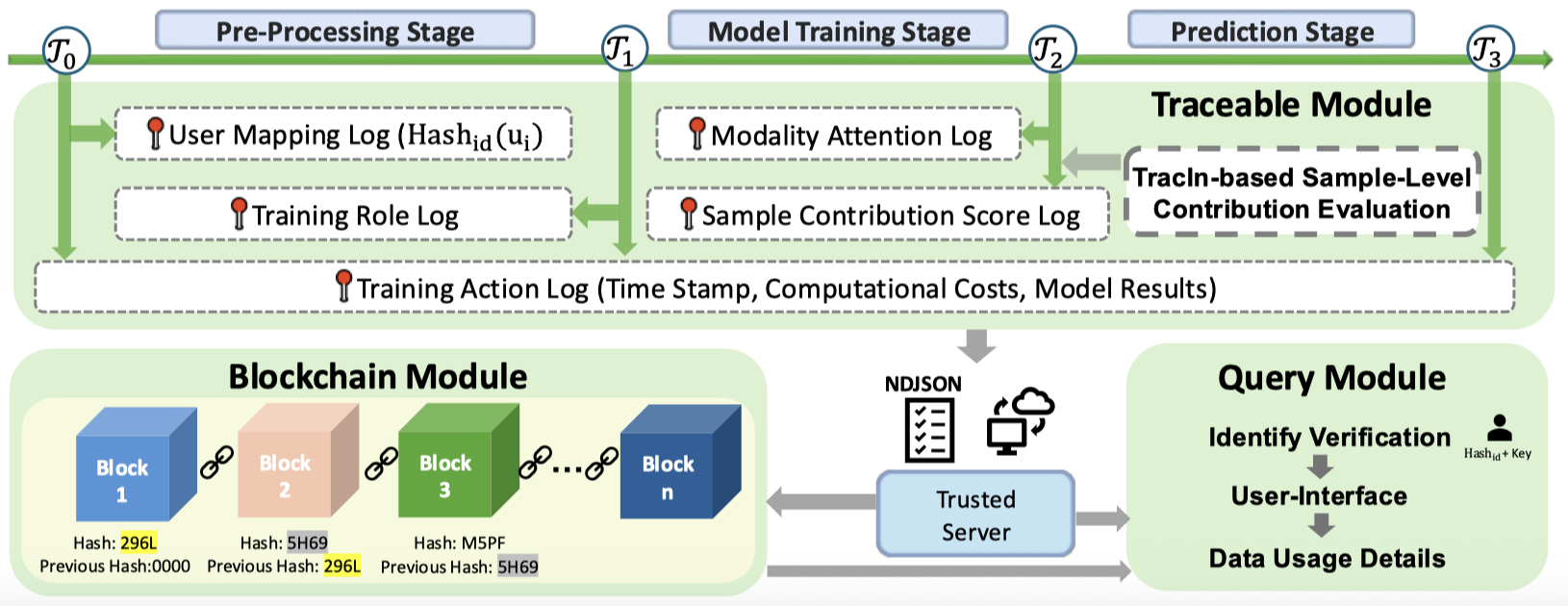
技术框架:FG-Trac框架主要包含以下几个关键模块:1) 事件捕获模块:负责在流水线的各个阶段(如预处理、训练等)捕获样本的关键事件,例如样本的创建、修改、使用等。2) 贡献度计算模块:基于训练过程中的检查点,计算每个样本对模型预测结果的贡献度。3) 加密承诺模块:将捕获的事件和贡献度信息与加密承诺进行锚定,以确保数据的完整性和防篡改性。4) 溯源查询模块:提供查询接口,允许用户查询特定样本的溯源信息,包括其生命周期事件、贡献度和验证状态。
关键创新:FG-Trac的关键创新在于其细粒度的样本级别溯源能力和可验证性。与现有方法相比,FG-Trac不仅关注模型的整体行为,还关注单个样本在流水线中的处理过程,并提供可验证的证据。此外,FG-Trac的设计是模型无关的,可以应用于各种不同的机器学习模型和流水线。
关键设计:FG-Trac使用哈希链来链接样本在不同阶段的事件记录,确保溯源信息的连续性和完整性。贡献度计算基于训练过程中的梯度信息,评估每个样本对模型参数更新的影响。加密承诺采用Merkle树结构,将多个样本的溯源信息聚合在一起,提高验证效率。框架的具体参数设置和损失函数取决于具体的机器学习任务和模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FG-Trac在卷积神经网络和多模态图学习流水线上均能有效实现样本级别的溯源,且对模型的预测性能影响很小。在保持模型准确率的同时,FG-Trac能够提供可验证的数据使用历史,并支持对样本贡献度的评估。计算开销方面,FG-Trac引入的额外开销在可接受范围内,证明了其在实际应用中的可行性。
🎯 应用场景
FG-Trac适用于对数据溯源性有严格要求的机器学习应用场景,例如金融风控、医疗诊断、自动驾驶等。它可以帮助用户验证数据的合规性,提高模型的透明度和可信度,并为模型的公平性和安全性提供保障。未来,FG-Trac可以扩展到更复杂的机器学习流水线,并与其他安全技术(如差分隐私、联邦学习)相结合,构建更安全、可信的机器学习系统。
📄 摘要(原文)
Modern machine learning systems are increasingly realised as multistage pipelines, yet existing transparency mechanisms typically operate at a model level: they describe what a system is and why it behaves as it does, but not how individual data samples are operationally recorded, tracked, and verified as they traverse the pipeline. This absence of verifiable, sample-level traceability leaves practitioners and users unable to determine whether a specific sample was used, when it was processed, or whether the corresponding records remain intact over time. We introduce FG-Trac, a model-agnostic framework that establishes verifiable, fine-grained sample-level traceability throughout machine learning pipelines. FG-Trac defines an explicit mechanism for capturing and verifying sample lifecycle events across preprocessing and training, computes contribution scores explicitly grounded in training checkpoints, and anchors these traces to tamper-evident cryptographic commitments. The framework integrates without modifying model architectures or training objectives, reconstructing complete and auditable data-usage histories with practical computational overhead. Experiments on a canonical convolutional neural network and a multimodal graph learning pipeline demonstrate that FG-Trac preserves predictive performance while enabling machine learning systems to furnish verifiable evidence of how individual samples were used and propagated during model execution.