What Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study
作者: Keyu Lv, Manyi Zhang, Xiaobo Xia, Jingchen Ni, Shannan Yan, Xianzhi Yu, Lu Hou, Chun Yuan, Haoli Bai
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
针对推理LLM,提出一种高效的低比特量化感知训练方法Reasoning-QAT。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量化感知训练 低比特量化 大型语言模型 推理优化 知识蒸馏
📋 核心要点
- 现有后训练量化(PTQ)方法在低比特设置下,推理LLM时精度损失大,尤其是在推理任务中。
- 论文提出Reasoning-QAT,一种优化的量化感知训练工作流程,结合知识蒸馏、PTQ初始化和强化学习。
- 实验表明,Reasoning-QAT在多个LLM和推理数据集上显著优于PTQ方法,例如在Qwen3-0.6B上,MATH-500提升44.53%。
📝 摘要(中文)
推理模型在编码和数学等复杂任务中表现出色,但其推理速度通常较慢且token效率较低。为了提高推理效率,后训练量化(PTQ)通常会导致较大的精度下降,尤其是在低比特设置下的推理任务中。本研究对推理模型的量化感知训练(QAT)进行了系统的实证研究。主要发现包括:(1)知识蒸馏是监督微调或强化学习训练的推理模型的有效目标;(2)PTQ为QAT提供了一个强大的初始化,提高了准确性并降低了训练成本;(3)在可行的冷启动下,强化学习对于量化模型仍然可行,并产生额外的收益;(4)将PTQ校准域与QAT训练域对齐可以加速收敛,并通常提高最终准确性。最后,我们将这些发现整合到一个优化的工作流程(Reasoning-QAT)中,并表明它在多个LLM骨干网络和推理数据集上始终优于最先进的PTQ方法。例如,在Qwen3-0.6B上,它在MATH-500上超过GPTQ 44.53%,并在2比特状态下持续恢复性能。
🔬 方法详解
问题定义:论文旨在解决低比特量化下,推理大型语言模型(LLM)的精度损失问题。现有的后训练量化(PTQ)方法在推理任务中,尤其是在低比特设置下,会造成显著的性能下降,限制了LLM在资源受限环境中的部署。
核心思路:论文的核心思路是通过量化感知训练(QAT)来缓解量化带来的精度损失。具体而言,论文通过系统性地研究QAT的各个环节,包括知识蒸馏目标、PTQ初始化、强化学习以及校准域对齐,找到最优的QAT配置,从而在低比特量化下保持LLM的推理能力。
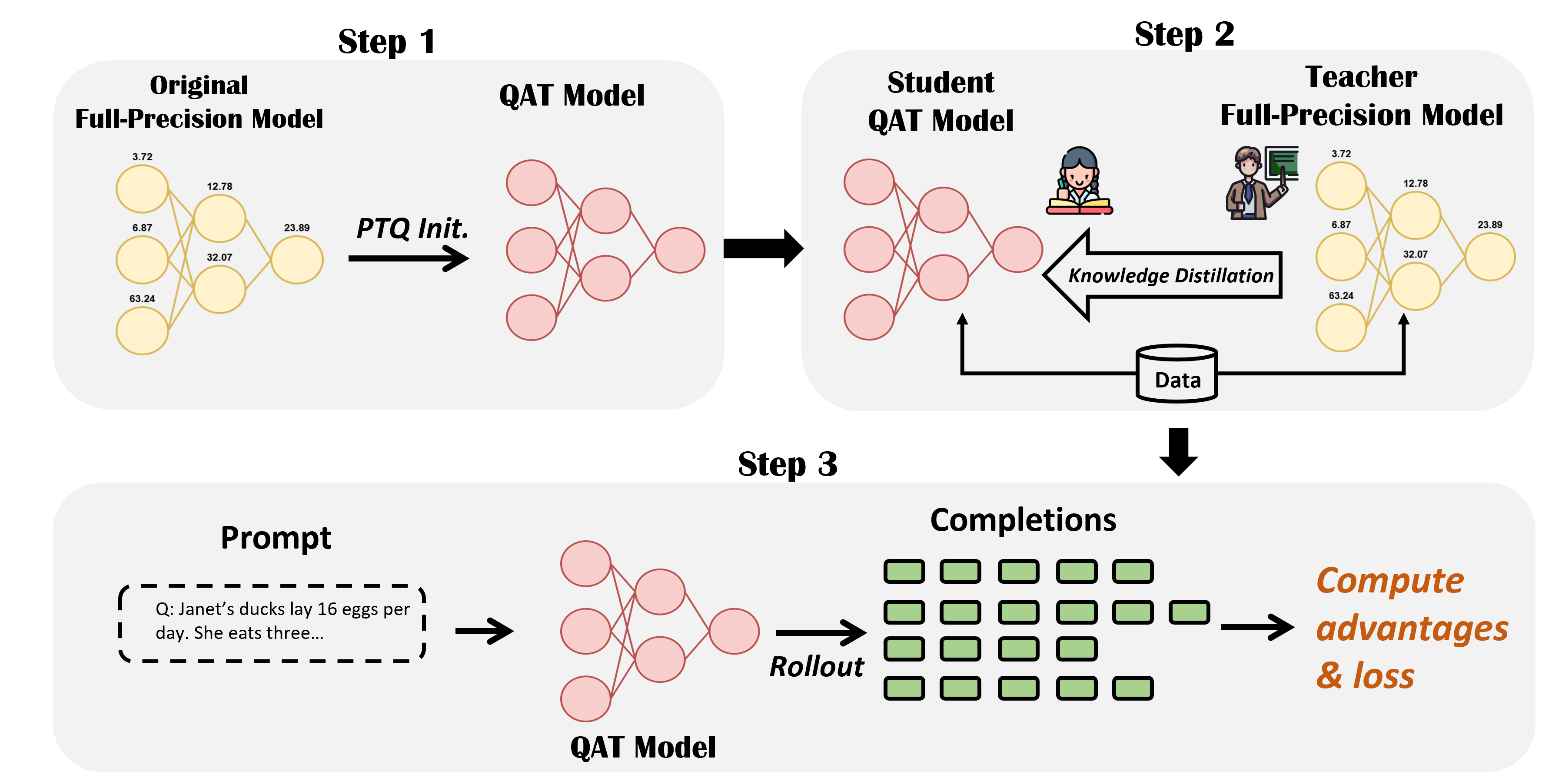
技术框架:Reasoning-QAT的整体流程如下:首先,使用PTQ对模型进行初始化,得到一个量化后的模型。然后,使用知识蒸馏作为训练目标,对量化模型进行微调。在微调过程中,可以选择使用监督微调或强化学习。最后,通过对齐PTQ校准域和QAT训练域,加速收敛并提高最终精度。
关键创新:论文的关键创新在于系统性地研究了QAT的各个环节,并提出了以下几个关键发现:1) 知识蒸馏是推理模型QAT的有效目标;2) PTQ可以为QAT提供良好的初始化;3) 强化学习可以进一步提升量化模型的性能;4) 对齐PTQ校准域和QAT训练域可以加速收敛。基于这些发现,论文提出了一个优化的QAT工作流程Reasoning-QAT。
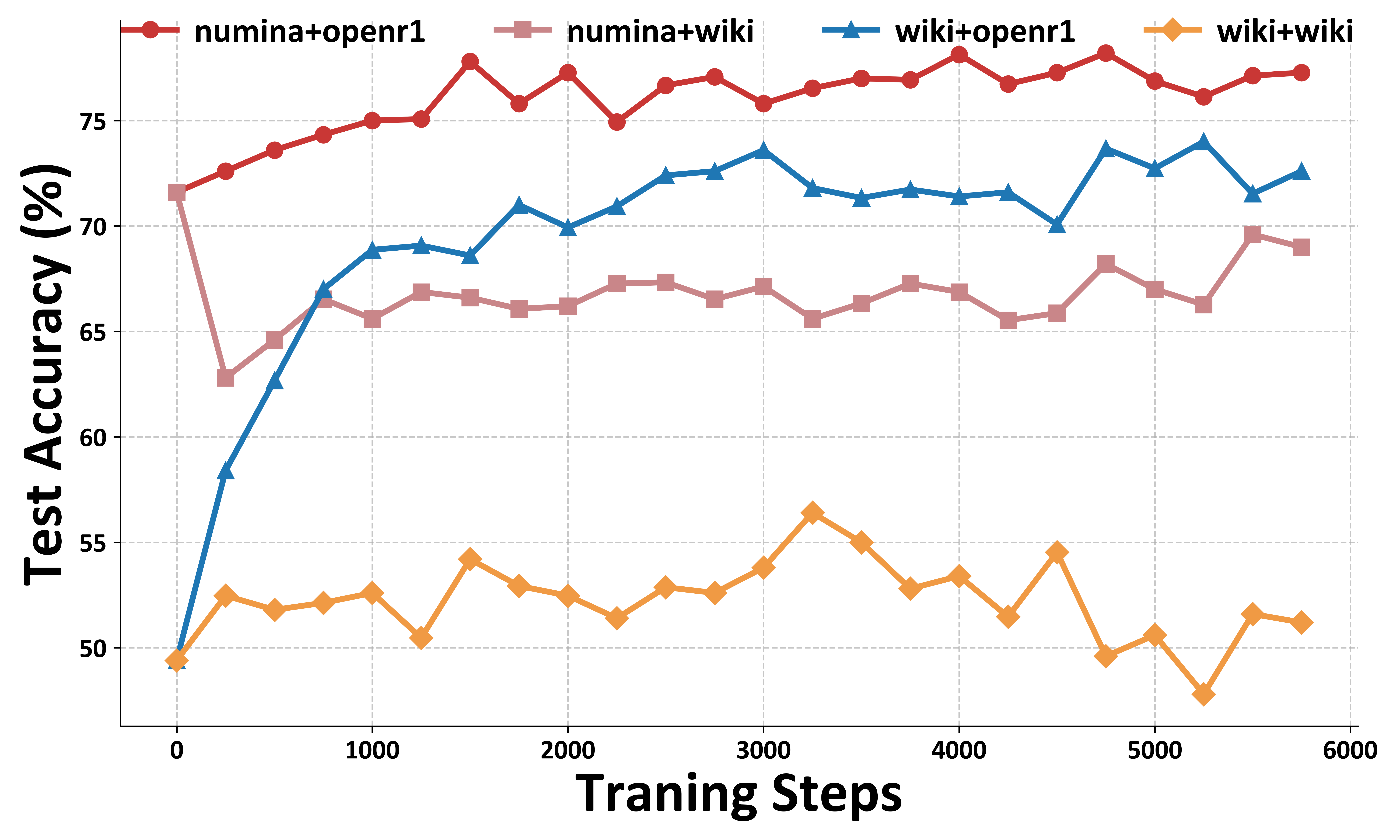
关键设计:在知识蒸馏方面,论文采用了标准的知识蒸馏损失函数,鼓励量化模型的输出接近原始模型的输出。在PTQ初始化方面,论文使用了GPTQ等先进的PTQ方法。在强化学习方面,论文使用了与原始模型相同的奖励函数。在校准域对齐方面,论文使用了与QAT训练数据相同的数据集进行PTQ校准。
🖼️ 关键图片

📊 实验亮点
Reasoning-QAT在多个LLM骨干网络和推理数据集上都取得了显著的性能提升。例如,在Qwen3-0.6B模型上,Reasoning-QAT在MATH-500数据集上超过GPTQ 44.53%,并且在2比特量化下也能保持较好的性能,证明了其在低比特量化下的有效性。
🎯 应用场景
该研究成果可应用于各种需要高效推理的场景,例如移动设备上的智能助手、边缘计算设备上的自然语言处理应用等。通过降低LLM的计算和存储成本,可以使其更容易部署在资源受限的环境中,从而推动LLM在更广泛领域的应用。
📄 摘要(原文)
Reasoning models excel at complex tasks such as coding and mathematics, yet their inference is often slow and token-inefficient. To improve the inference efficiency, post-training quantization (PTQ) usually comes with the cost of large accuracy drops, especially for reasoning tasks under low-bit settings. In this study, we present a systematic empirical study of quantization-aware training (QAT) for reasoning models. Our key findings include: (1) Knowledge distillation is a robust objective for reasoning models trained via either supervised fine-tuning or reinforcement learning; (2) PTQ provides a strong initialization for QAT, improving accuracy while reducing training cost; (3) Reinforcement learning remains feasible for quantized models given a viable cold start and yields additional gains; and (4) Aligning the PTQ calibration domain with the QAT training domain accelerates convergence and often improves the final accuracy. Finally, we consolidate these findings into an optimized workflow (Reasoning-QAT), and show that it consistently outperforms state-of-the-art PTQ methods across multiple LLM backbones and reasoning datasets. For instance, on Qwen3-0.6B, it surpasses GPTQ by 44.53% on MATH-500 and consistently recovers performance in the 2-bit regime.