Adaptive Exponential Integration for Stable Gaussian Mixture Black-Box Variational Inference
作者: Baojun Che, Yifan Chen, Daniel Zhengyu Huang, Xinying Mao, Weijie Wang
分类: cs.LG
发布日期: 2026-01-21
备注: 26 pages, 7 figures
💡 一句话要点
提出自适应指数积分方法,稳定高效地进行高斯混合黑盒变分推断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 黑盒变分推断 高斯混合模型 指数积分 自适应步长 自然梯度 贝叶斯推断 流形优化
📋 核心要点
- 传统黑盒变分推断在高斯混合模型中面临不稳定和效率低下的问题,限制了其在复杂后验分布中的应用。
- 论文提出一种结合仿射不变预处理、指数积分器和自适应步长的框架,以保证协方差矩阵的正定性和优化过程的稳定性。
- 实验表明,该方法在多峰分布、Neal漏斗和Darcy流反问题上表现出优越的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种稳定高效的框架,用于高斯混合模型的黑盒变分推断(BBVI)。该方法无需目标密度的梯度信息,即可灵活地逼近复杂的后验分布。为了克服标准数值优化方法的不稳定性和低效性,该框架结合了三个关键组件:(1) 通过自然梯度公式实现的仿射不变预处理;(2) 无条件保持协方差矩阵正定性的指数积分器;(3) 自适应步长,以确保稳定性和适应不同的预热和收敛阶段。该方法与流形优化和镜像下降有天然的联系。对于高斯后验,我们证明了在无噪声情况下的指数收敛,以及在蒙特卡洛估计下的几乎必然收敛,从而严格证明了自适应步长的必要性。在多峰分布、Neal的多尺度漏斗以及基于PDE的Darcy流贝叶斯反问题上的数值实验证明了该方法的有效性。
🔬 方法详解
问题定义:黑盒变分推断(BBVI)旨在近似复杂的后验分布,但当使用高斯混合模型时,标准数值优化方法常常面临不稳定性和效率低下的问题。尤其是在高维或多峰后验分布中,优化过程容易发散或收敛速度缓慢。现有方法难以保证协方差矩阵的正定性,导致算法崩溃。
核心思路:论文的核心思路是通过结合仿射不变预处理、指数积分器和自适应步长来解决BBVI中的稳定性和效率问题。仿射不变预处理可以改善优化问题的条件数,指数积分器可以保证协方差矩阵的正定性,自适应步长可以根据优化过程的状态动态调整学习率,从而加速收敛并避免发散。
技术框架:该方法的技术框架主要包含以下几个阶段:1. 初始化高斯混合模型参数;2. 计算自然梯度,并进行仿射不变预处理;3. 使用指数积分器更新参数,保证协方差矩阵的正定性;4. 根据优化过程的状态,自适应地调整步长;5. 重复步骤2-4,直到收敛。
关键创新:该方法最重要的技术创新点在于结合了仿射不变预处理、指数积分器和自适应步长,从而在理论上保证了算法的稳定性和收敛性。指数积分器的使用是保证协方差矩阵正定性的关键,而自适应步长则可以根据优化过程的状态动态调整学习率,从而加速收敛并避免发散。
关键设计:指数积分器采用Cayley变换来实现,保证了协方差矩阵的正定性。自适应步长根据梯度范数的变化动态调整,当梯度范数变化剧烈时,减小步长;当梯度范数变化缓慢时,增大步长。具体的步长调整策略需要根据具体问题进行调整。
🖼️ 关键图片
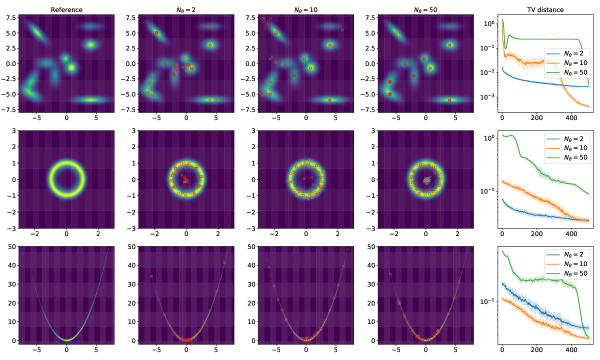
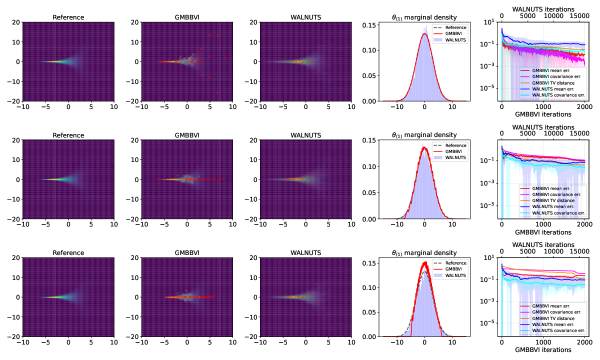
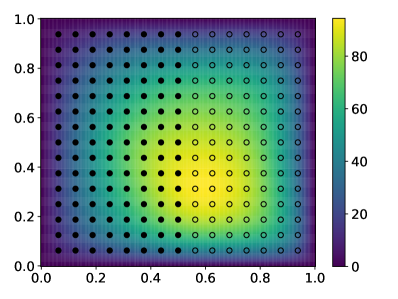
📊 实验亮点
实验结果表明,该方法在多峰分布、Neal's funnel和Darcy流反问题上均优于现有的BBVI方法。例如,在Neal's funnel问题上,该方法能够更快地收敛到正确的后验分布,并且具有更高的稳定性。在Darcy流反问题上,该方法能够更准确地估计模型参数,并降低不确定性。
🎯 应用场景
该研究成果可应用于各种需要进行贝叶斯推断的领域,例如机器学习、计算机视觉、自然语言处理和科学计算。特别是在处理高维、多峰或非凸后验分布时,该方法能够提供更稳定和高效的推断结果。例如,可以应用于贝叶斯神经网络的训练、图像分割、主题模型和贝叶斯反问题等。
📄 摘要(原文)
Black-box variational inference (BBVI) with Gaussian mixture families offers a flexible approach for approximating complex posterior distributions without requiring gradients of the target density. However, standard numerical optimization methods often suffer from instability and inefficiency. We develop a stable and efficient framework that combines three key components: (1) affine-invariant preconditioning via natural gradient formulations, (2) an exponential integrator that unconditionally preserves the positive definiteness of covariance matrices, and (3) adaptive time stepping to ensure stability and to accommodate distinct warm-up and convergence phases. The proposed approach has natural connections to manifold optimization and mirror descent. For Gaussian posteriors, we prove exponential convergence in the noise-free setting and almost-sure convergence under Monte Carlo estimation, rigorously justifying the necessity of adaptive time stepping. Numerical experiments on multimodal distributions, Neal's multiscale funnel, and a PDE-based Bayesian inverse problem for Darcy flow demonstrate the effectiveness of the proposed method.