Mechanism Shift During Post-training from Autoregressive to Masked Diffusion Language Models
作者: Injin Kong, Hyoungjoon Lee, Yohan Jo
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
揭示后训练中自回归到掩码扩散语言模型的机制转变
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 掩码扩散模型 自回归模型 后训练 电路分析 机制转变
📋 核心要点
- 现有自回归模型在序列生成任务中存在局限性,后训练为掩码扩散模型是一种潜在的解决方案。
- 论文通过比较电路分析,研究了自回归模型后训练为掩码扩散模型时内部计算机制的转变。
- 研究发现,掩码扩散模型在全局规划任务中会放弃自回归路径,并增加早期层的处理,实现非序列全局规划。
📝 摘要(中文)
将预训练的自回归模型(ARM)后训练为掩码扩散模型(MDM)已成为一种经济高效的策略,以克服序列生成的局限性。然而,这种范式转变引起的内部算法转换仍未被探索,因此尚不清楚后训练的MDM是否获得了真正的双向推理能力,或者仅仅是重新包装了自回归启发式方法。在这项工作中,我们通过对ARM及其MDM对应物进行比较电路分析来解决这个问题。我们的分析揭示了一种依赖于任务结构性质的系统性“机制转变”。在结构上,我们观察到明显的差异:虽然MDM在局部因果依赖关系占主导地位的任务中主要保留自回归电路,但它们放弃了全局规划任务的初始化路径,表现出以早期层处理增加为特征的独特重连。在语义上,我们发现从ARM中清晰、局部化的专业化到MDM中分布式集成的转变。通过这些发现,我们得出结论,扩散后训练不仅适应模型参数,而且从根本上重组内部计算以支持非序列全局规划。
🔬 方法详解
问题定义:论文旨在解决将预训练的自回归模型(ARM)后训练为掩码扩散模型(MDM)后,模型内部算法机制如何转变的问题。现有方法缺乏对这种转变的深入理解,不清楚后训练的MDM是否真正获得了双向推理能力,还是仅仅沿用了自回归的策略。
核心思路:论文的核心思路是通过比较电路分析,深入研究ARM和MDM在不同任务上的内部计算过程。通过分析模型在不同任务上的电路结构和语义表示,揭示后训练过程中发生的“机制转变”。
技术框架:论文的技术框架主要包含以下几个步骤:1) 选择合适的ARM和MDM模型;2) 设计具有不同结构性质的任务,例如局部因果依赖任务和全局规划任务;3) 对ARM和MDM在这些任务上的电路进行分析,包括激活模式、信息流等;4) 比较ARM和MDM在不同任务上的电路结构和语义表示,从而揭示后训练过程中发生的机制转变。
关键创新:论文的关键创新在于首次对自回归模型后训练为掩码扩散模型过程中的内部机制转变进行了深入的电路分析。通过比较ARM和MDM在不同任务上的电路结构和语义表示,揭示了MDM在全局规划任务中会放弃自回归路径,并增加早期层的处理,从而实现非序列全局规划。
关键设计:论文的关键设计包括:1) 精心设计的任务,能够区分局部因果依赖和全局规划;2) 细致的电路分析方法,能够捕捉模型内部的信息流和激活模式;3) 对比ARM和MDM的分析框架,能够清晰地揭示后训练过程中发生的机制转变。具体的参数设置、损失函数、网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
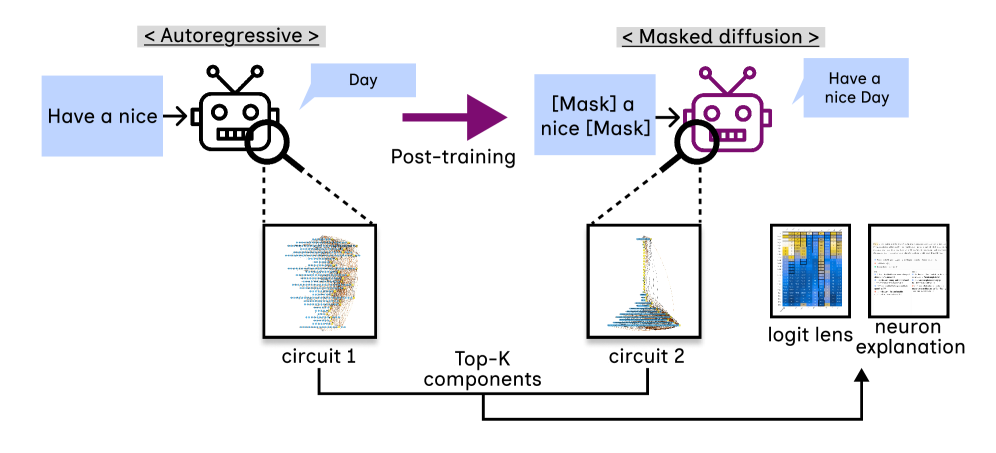

📊 实验亮点
论文通过电路分析发现,在全局规划任务中,掩码扩散模型会放弃自回归模型中已初始化的路径,并表现出以早期层处理增加为特征的独特重连。此外,论文还观察到从自回归模型中清晰、局部化的专业化到掩码扩散模型中分布式集成的转变。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于改进扩散模型的训练策略,使其更好地适应各种自然语言处理任务,尤其是在需要全局理解和规划的任务中,例如文本摘要、机器翻译、对话生成等。此外,该研究也为理解深度学习模型的内部工作机制提供了新的视角。
📄 摘要(原文)
Post-training pretrained Autoregressive models (ARMs) into Masked Diffusion models (MDMs) has emerged as a cost-effective strategy to overcome the limitations of sequential generation. However, the internal algorithmic transformations induced by this paradigm shift remain unexplored, leaving it unclear whether post-trained MDMs acquire genuine bidirectional reasoning capabilities or merely repackage autoregressive heuristics. In this work, we address this question by conducting a comparative circuit analysis of ARMs and their MDM counterparts. Our analysis reveals a systematic "mechanism shift" dependent on the structural nature of the task. Structurally, we observe a distinct divergence: while MDMs largely retain autoregressive circuitry for tasks dominated by local causal dependencies, they abandon initialized pathways for global planning tasks, exhibiting distinct rewiring characterized by increased early-layer processing. Semantically, we identify a transition from sharp, localized specialization in ARMs to distributed integration in MDMs. Through these findings, we conclude that diffusion post-training does not merely adapt model parameters but fundamentally reorganizes internal computation to support non-sequential global planning.