PCL-Reasoner-V1.5: Advancing Math Reasoning with Offline Reinforcement Learning
作者: Yao Lu, Dengdong Fan, Jianzheng Nie, Fan Xu, Jie Chen, Bin Zhou, Yonghong Tian
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
PCL-Reasoner-V1.5:利用离线强化学习提升数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大型语言模型 离线强化学习 Qwen2.5-32B 监督微调
📋 核心要点
- 现有在线强化学习方法在训练大型语言模型时,面临训练不稳定和效率低下的挑战。
- 论文提出一种离线强化学习方法,旨在提升训练的稳定性和效率,从而更好地优化数学推理能力。
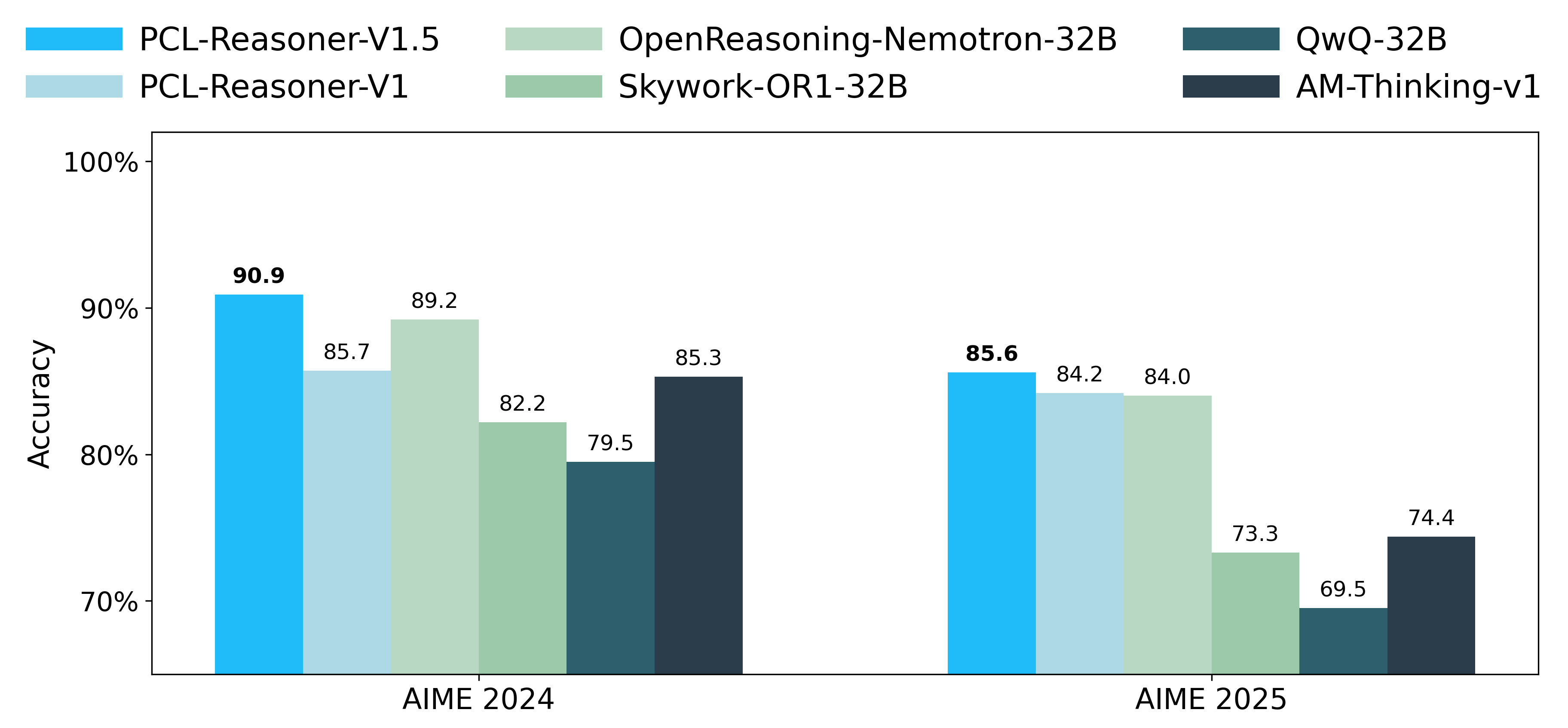
- PCL-Reasoner-V1.5模型在AIME 2024和AIME 2025数据集上取得了显著的性能提升,验证了离线强化学习的有效性。
📝 摘要(中文)
本文介绍了PCL-Reasoner-V1.5,一个拥有320亿参数的大型语言模型(LLM),专为数学推理而设计。该模型基于Qwen2.5-32B构建,并通过监督微调(SFT)和强化学习(RL)进行优化。一个核心创新是提出的离线强化学习方法,与标准的在线强化学习方法(如GRPO)相比,该方法提供了卓越的训练稳定性和效率。我们的模型在基于Qwen2.5-32B进行后训练的模型中实现了最先进的性能,在AIME 2024上达到了90.9%的平均准确率,在AIME 2025上达到了85.6%的平均准确率。这项工作证明了离线强化学习是推进LLM推理能力的一种稳定而高效的范例。所有实验均在华为Ascend 910C NPU上进行。
🔬 方法详解
问题定义:现有的大型语言模型在数学推理任务中,通常采用在线强化学习方法进行优化。然而,在线强化学习方法在训练过程中容易出现不稳定现象,且训练效率较低,难以充分利用已有的数据资源。因此,如何设计一种稳定且高效的强化学习方法,以提升LLM的数学推理能力,是一个亟待解决的问题。
核心思路:论文的核心思路是采用离线强化学习方法来训练LLM。与在线强化学习不同,离线强化学习利用预先收集好的数据集进行训练,避免了与环境的实时交互,从而提高了训练的稳定性和效率。通过学习数据集中的策略,模型可以更好地掌握数学推理的技巧。
技术框架:PCL-Reasoner-V1.5的训练流程主要包括两个阶段:监督微调(SFT)和强化学习(RL)。首先,使用监督学习方法在大量的数学推理数据集上对Qwen2.5-32B进行微调,使其具备初步的数学推理能力。然后,采用离线强化学习方法进一步优化模型的推理策略。离线强化学习模块负责从预先收集的数据集中学习,并根据学习到的策略更新模型参数。
关键创新:论文最重要的技术创新点在于提出了使用离线强化学习方法来训练用于数学推理的LLM。与传统的在线强化学习方法相比,离线强化学习具有更高的训练稳定性和效率,能够更好地利用已有的数据资源。此外,论文还针对数学推理任务的特点,设计了合适的奖励函数和策略优化算法。
关键设计:在离线强化学习阶段,论文可能采用了诸如Behavior Cloning (BC), Advantage Weighted Regression (AWR), or Conservative Q-Learning (CQL) 等算法。具体选择哪种算法以及如何调整超参数以适应数学推理任务是关键设计细节。奖励函数的设计也至关重要,需要能够准确地反映模型推理的正确性和效率。此外,数据集的质量和规模也会直接影响模型的性能。
🖼️ 关键图片
📊 实验亮点
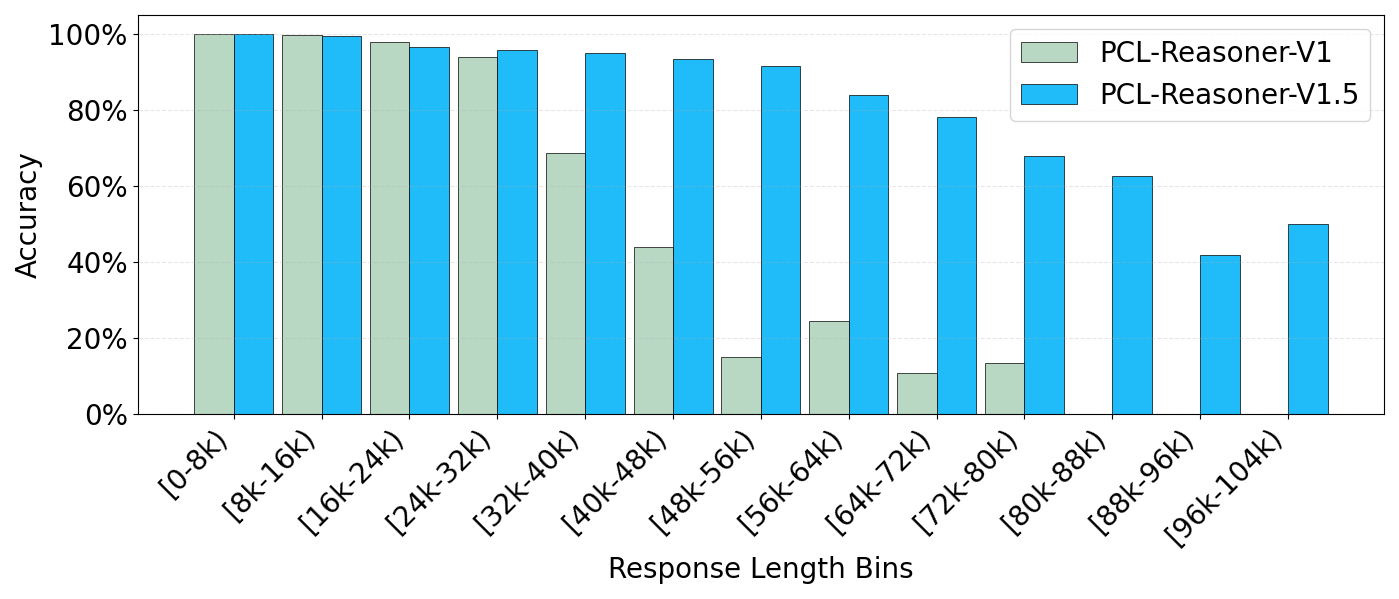
PCL-Reasoner-V1.5在AIME 2024数据集上取得了90.9%的平均准确率,在AIME 2025数据集上取得了85.6%的平均准确率。这些结果表明,该模型在数学推理任务中达到了最先进的水平,显著优于其他基于Qwen2.5-32B进行后训练的模型。离线强化学习方法的应用是性能提升的关键因素。
🎯 应用场景
该研究成果可广泛应用于教育、科研、金融等领域。在教育领域,可以开发智能辅导系统,帮助学生解决数学难题。在科研领域,可以辅助科学家进行复杂的数学建模和计算。在金融领域,可以用于风险评估和量化交易等任务。未来,该技术有望进一步提升人工智能在复杂推理任务中的能力。
📄 摘要(原文)
We present PCL-Reasoner-V1.5, a 32-billion-parameter large language model (LLM) for mathematical reasoning. The model is built upon Qwen2.5-32B and refined via supervised fine-tuning (SFT) followed by reinforcement learning (RL). A central innovation is our proposed offline RL method, which provides superior training stability and efficiency over standard online RL methods such as GRPO. Our model achieves state-of-the-art performance among models post-trained on Qwen2.5-32B, attaining average accuracies of 90.9% on AIME 2024 and 85.6% on AIME 2025. Our work demonstrates offline RL as a stable and efficient paradigm for advancing reasoning in LLMs. All experiments were conducted on Huawei Ascend 910C NPUs.