CoScale-RL: Efficient Post-Training by Co-Scaling Data and Computation
作者: Yutong Chen, Jiandong Gao, Ji Wu
分类: cs.LG, cs.AI
发布日期: 2026-01-21
备注: preprint
💡 一句话要点
CoScale-RL:通过协同缩放数据和计算,高效地进行大模型后训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 后训练 强化学习 数据增强 模型合并 Re-distillation 协同缩放
📋 核心要点
- 现有大型推理模型训练在难题上不稳定,后训练缩放策略效率有待提升。
- CoScale-RL通过协同缩放数据和计算,为每个问题收集多个解,并扩大rollout计算规模。
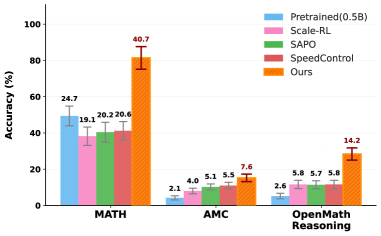
- 实验表明,CoScale-RL显著提升数据和计算效率,在多个基准测试中平均提升3.76倍准确率。
📝 摘要(中文)
训练大型推理模型(LRM)通常不稳定且难以预测,尤其是在难题或弱基础模型上。我们发现,当前的后训练缩放策略在这些情况下仍然可以改进。我们提出CoScale-RL,一种具有更好数据和计算效率的新型缩放策略。我们首先扩大解决方案的规模,使问题可解。核心思想是为每个问题收集多个解决方案,而不是简单地扩大数据集。然后,我们扩大rollout计算的规模,以稳定强化学习。我们进一步利用一种称为Re-distillation的模型合并技术,以在扩大规模时维持甚至提高计算效率。我们的方法显著提高了数据和计算效率,在四个基准测试中平均提高了3.76倍的准确率。CoScale-RL能够在没有大量SFT数据集的情况下提高LRM的能力边界。我们的方法为进一步提高LRM的推理能力提供了一个新的缩放方向。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRM)在难题上训练不稳定、推理能力不足的问题。现有的后训练缩放策略通常依赖于简单地扩大数据集,这导致数据效率低下,并且难以有效提升模型的能力边界。此外,强化学习训练过程中的不稳定性也是一个挑战。
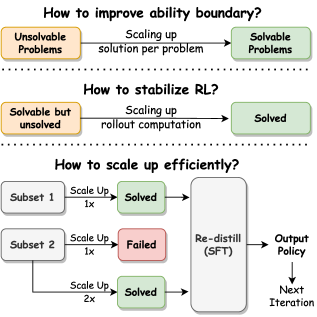
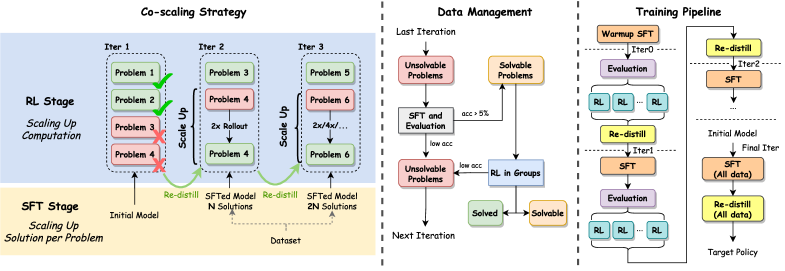
核心思路:CoScale-RL的核心思路是通过协同缩放数据和计算来提高训练效率和模型性能。具体来说,它不是简单地扩大数据集,而是为每个问题收集多个解决方案,从而使问题更容易解决。同时,通过扩大rollout计算的规模来稳定强化学习的训练过程。此外,还利用模型合并技术Re-distillation来维持或提高计算效率。
技术框架:CoScale-RL的整体框架包含以下几个主要阶段:1) 数据增强:为每个问题生成多个解决方案,增加数据的多样性。2) 强化学习训练:使用增强后的数据和扩大的rollout计算规模来训练模型,提高模型的推理能力和稳定性。3) 模型合并:使用Re-distillation技术将多个模型合并成一个更强大的模型,提高计算效率。
关键创新:CoScale-RL的关键创新在于其协同缩放数据和计算的策略。与传统的只关注数据规模的缩放方法不同,CoScale-RL同时考虑了数据和计算两个方面,通过为每个问题收集多个解决方案来提高数据效率,并通过扩大rollout计算规模来稳定强化学习的训练过程。Re-distillation技术的应用进一步提高了计算效率。
关键设计:论文中涉及的关键设计包括:1) 多个解决方案的生成方法:具体如何为每个问题生成多个不同的解决方案,可能涉及到不同的搜索算法或策略。2) rollout计算规模的确定:如何确定合适的rollout计算规模,以在稳定训练和计算效率之间取得平衡。3) Re-distillation的具体实现:如何使用Re-distillation技术将多个模型有效地合并成一个更强大的模型,可能涉及到损失函数的设计和参数的调整。
🖼️ 关键图片
📊 实验亮点
CoScale-RL在四个基准测试中取得了显著的性能提升,平均准确率提高了3.76倍。这一结果表明,该方法能够有效提高大型推理模型的能力边界,并且具有较高的数据和计算效率。与传统的缩放方法相比,CoScale-RL能够在更少的数据和计算资源下取得更好的性能。
🎯 应用场景
CoScale-RL可应用于各种需要大型推理模型的场景,例如问答系统、代码生成、数学问题求解等。该方法能够有效提高模型的推理能力和训练效率,降低对大规模标注数据的依赖,具有重要的实际应用价值。未来,该方法有望进一步推广到其他类型的模型和任务中。
📄 摘要(原文)
Training Large Reasoning Model (LRM) is usually unstable and unpredictable, especially on hard problems or weak foundation models. We found that the current post-training scaling strategy can still improve on these cases. We propose CoScale-RL, a novel scaling strategy with better data and computational efficiency. We first scale up solutions to make problems solvable. The core idea is to collect multiple solutions for each problem, rather than simply enlarging the dataset. Then, we scale up rollout computation to stabilize Reinforcement Learning. We further leverage a model merge technique called Re-distillation to sustain or even improve computational efficiency when scaling up. Our method significantly improves data and computational efficiency, with an average 3.76$\times$ accuracy improvement on four benchmarks. CoScale-RL is able to improve an LRM's ability boundary without an extensive SFT dataset. Our method provides a new scaling direction to further improve LRM's reasoning ability.