Beyond Error-Based Optimization: Experience-Driven Symbolic Regression with Goal-Conditioned Reinforcement Learning
作者: Jianwen Sun, Xinrui Li, Fuqing Li, Xiaoxuan Shen
分类: cs.LG, cs.AI
发布日期: 2026-01-21
💡 一句话要点
提出EGRL-SR框架以解决符号回归中的搜索效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 符号回归 强化学习 经验重放 结构模式 自动建模 数据分析
📋 核心要点
- 现有符号回归方法依赖拟合误差,导致在表达空间中搜索方向模糊,难以收敛到真实函数。
- 本文提出EGRL-SR框架,将符号回归视为目标条件强化学习问题,利用历史经验优化搜索过程。
- 实验结果显示,EGRL-SR在多个基准测试中表现优异,恢复复杂表达式的能力显著提升。
📝 摘要(中文)
符号回归旨在自动识别输入与输出变量之间的数学表达关系。现有的基于搜索的符号回归方法通常依赖拟合误差来指导搜索过程。然而,在广阔的表达空间中,许多候选表达式可能具有相似的误差值,但结构差异显著,导致搜索方向模糊,阻碍了对真实函数的收敛。为了解决这一挑战,本文提出了一种新颖的框架EGRL-SR(经验驱动的目标条件强化学习符号回归)。与传统的误差驱动方法不同,EGRL-SR通过利用精确的历史轨迹和优化动作价值网络,主动引导搜索过程,从而实现更稳健的表达式搜索。实验结果表明,EGRL-SR在恢复率和鲁棒性方面均优于现有最先进的方法。
🔬 方法详解
问题定义:本文解决符号回归中的搜索效率问题,现有方法依赖误差值,导致在表达空间中搜索方向不明确,难以找到真实函数。
核心思路:EGRL-SR框架通过引入目标条件强化学习,利用历史轨迹和经验重放来优化搜索过程,关注结构模式而非单纯的低误差表达式。
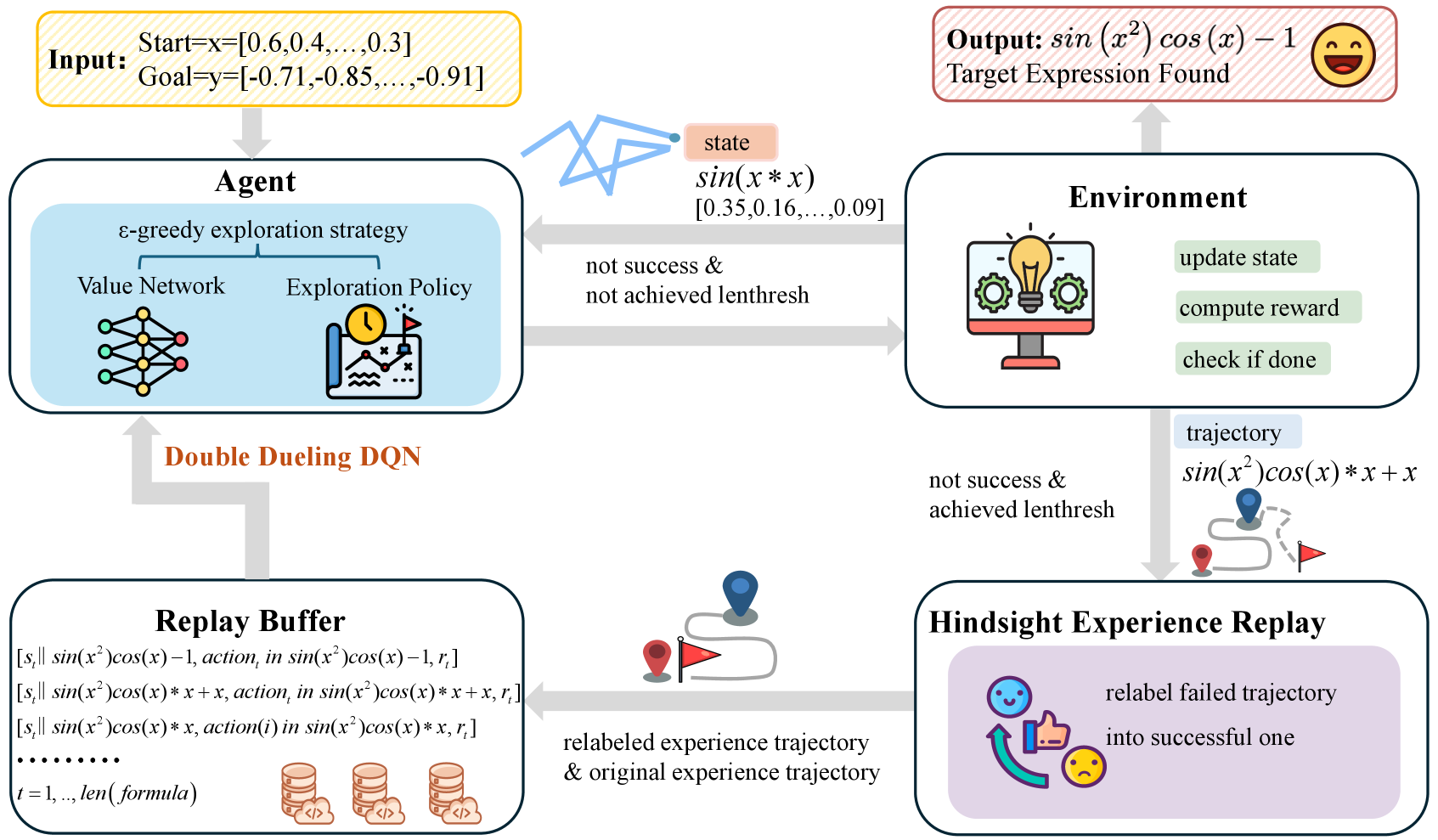
技术框架:EGRL-SR包括动作价值网络、经验重放模块和结构引导的启发式探索策略,整体流程为:输入-输出对的映射学习、历史经验的积累与重放、基于结构的搜索引导。
关键创新:EGRL-SR的核心创新在于将符号回归问题转化为强化学习问题,采用全点满意度的二元奖励函数,鼓励网络关注结构模式,显著区别于传统误差驱动方法。
关键设计:设计了全点满意度的奖励函数,强调结构模式的学习;同时,采用结构引导的启发式探索策略,以增强搜索的多样性和覆盖率。实验验证了动作价值网络的有效性,以及奖励函数和探索策略的重要性。
🖼️ 关键图片
📊 实验亮点
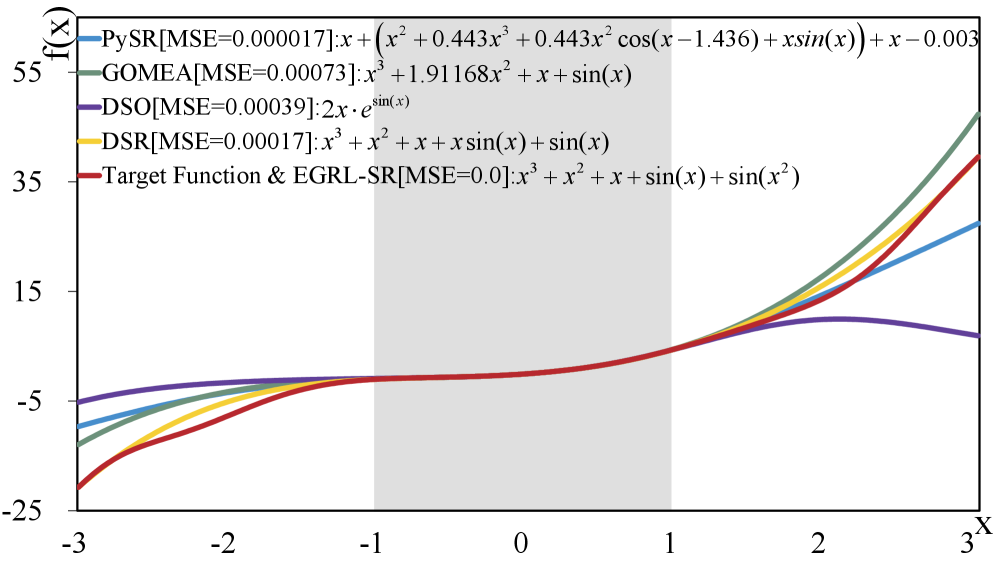
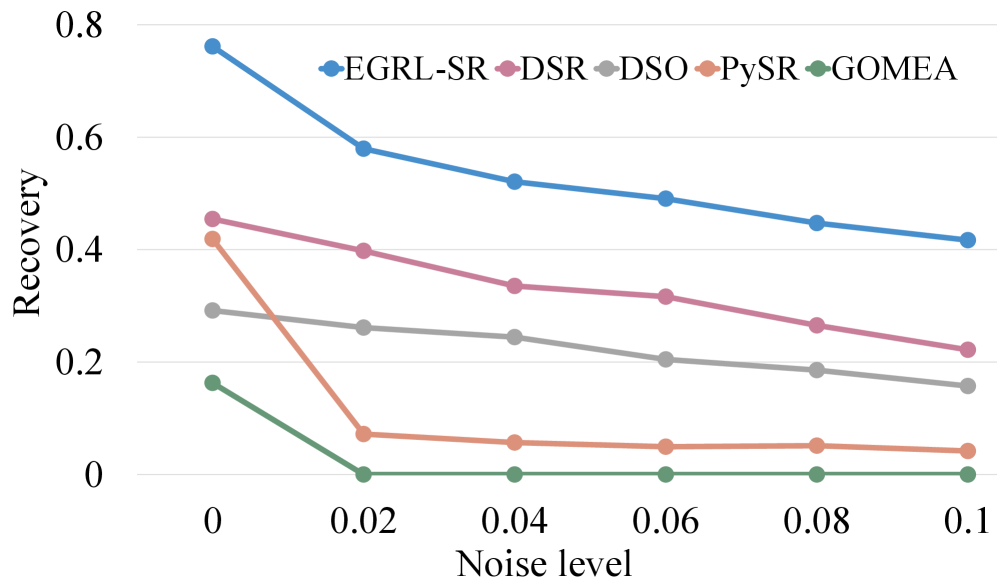
实验结果表明,EGRL-SR在多个公共基准测试中均优于现有最先进的方法,恢复率和鲁棒性显著提升。在相同的搜索预算下,EGRL-SR能够恢复更复杂的表达式,验证了其在符号回归领域的有效性。
🎯 应用场景
该研究在自动化建模、数据分析和科学计算等领域具有广泛的应用潜力。通过提高符号回归的效率和准确性,EGRL-SR可以帮助研究人员和工程师更快速地发现数据中的潜在规律,推动科学研究和工业应用的发展。
📄 摘要(原文)
Symbolic Regression aims to automatically identify compact and interpretable mathematical expressions that model the functional relationship between input and output variables. Most existing search-based symbolic regression methods typically rely on the fitting error to inform the search process. However, in the vast expression space, numerous candidate expressions may exhibit similar error values while differing substantially in structure, leading to ambiguous search directions and hindering convergence to the underlying true function. To address this challenge, we propose a novel framework named EGRL-SR (Experience-driven Goal-conditioned Reinforcement Learning for Symbolic Regression). In contrast to traditional error-driven approaches, EGRL-SR introduces a new perspective: leveraging precise historical trajectories and optimizing the action-value network to proactively guide the search process, thereby achieving a more robust expression search. Specifically, we formulate symbolic regression as a goal-conditioned reinforcement learning problem and incorporate hindsight experience replay, allowing the action-value network to generalize common mapping patterns from diverse input-output pairs. Moreover, we design an all-point satisfaction binary reward function that encourages the action-value network to focus on structural patterns rather than low-error expressions, and concurrently propose a structure-guided heuristic exploration strategy to enhance search diversity and space coverage. Experiments on public benchmarks show that EGRL-SR consistently outperforms state-of-the-art methods in recovery rate and robustness, and can recover more complex expressions under the same search budget. Ablation results validate that the action-value network effectively guides the search, with both the reward function and the exploration strategy playing critical roles.